Prompt Caching Là Gì? Giảm 90% Chi Phí Claude API (2026)
Tháng trước mình check hóa đơn API và thấy $280 chỉ trong 3 tuần. Nhìn vào breakdown, 70% là input tokens, phần lớn từ system prompt 8,000 tokens mình đính kèm vào mỗi request. Vấn đề là: Claude re-process toàn bộ 8,000 token đó từ đầu mỗi lần gọi API. Một ngàn requests? Tám triệu token input chỉ cho system prompt. Prompt caching sửa lỗi đó. Cache read chỉ tốn $0.30/MTok thay vì $3/MTok, đúng 10% giá gốc với Sonnet 4.6. Dưới đây là cách implement trong 10 phút.
TL;DR
- Prompt caching lưu trữ phần đầu prompt (prefix) để các request sau đọc lại với giá 10% thay vì 100%
- Cache read = $0.30/MTok (Sonnet 4.6) so với $3/MTok bình thường, tiết kiệm 90%
- Implement chỉ cần thêm
cache_control={"type": "ephemeral"}vào API call - Cache-First Cost Formula: prefix ổn định + trên 1,024 tokens + nhiều requests = cache bắt buộc
- Claude Code tự động cache CLAUDE.md và system prompt, không cần config thêm gì
Prompt Caching Là Gì?
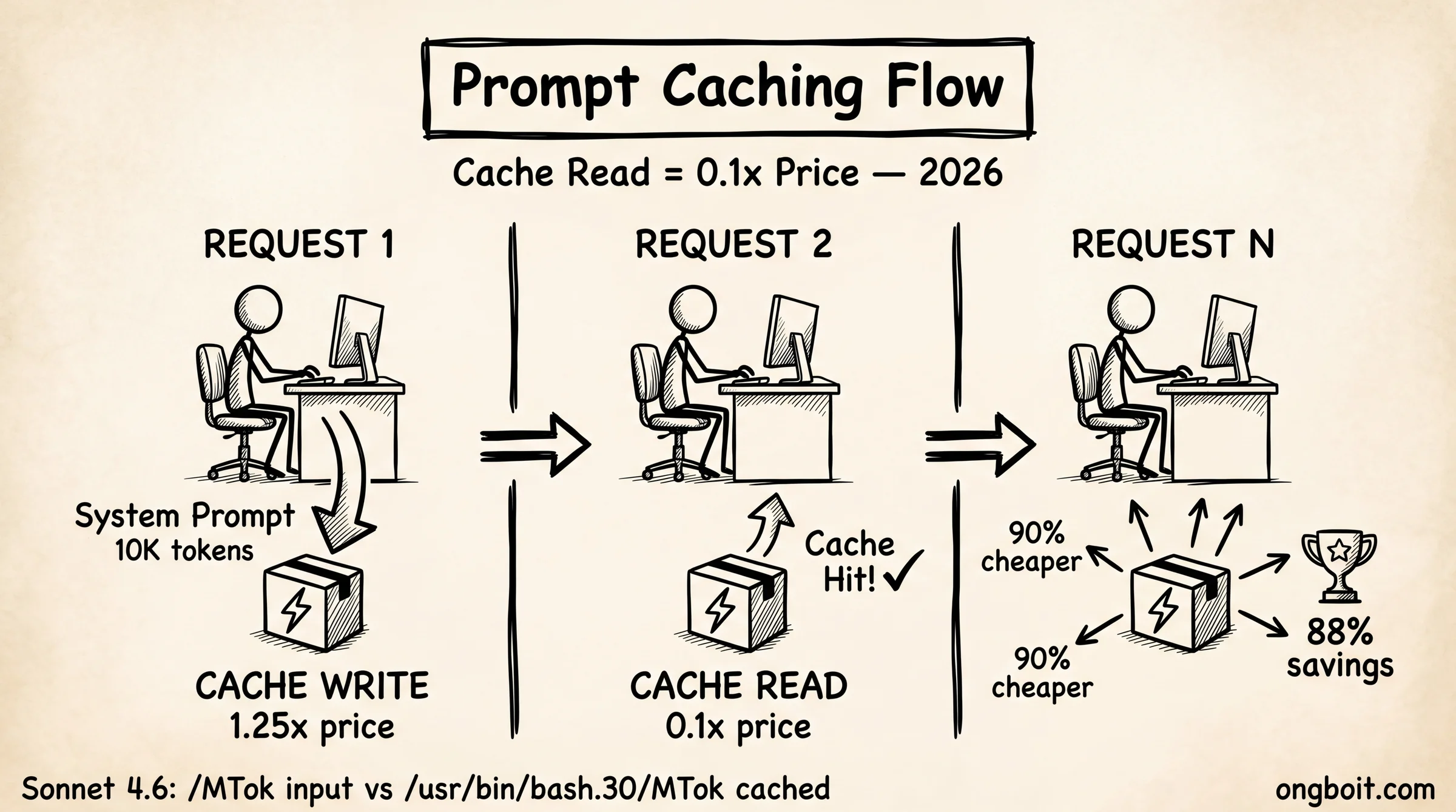
Prompt caching là tính năng của Anthropic API cho phép lưu trữ phần đầu của prompt (prefix) vào bộ nhớ tạm, giúp các request tiếp theo đọc lại thay vì phải xử lý từ đầu. Kết quả: giảm 90% chi phí cho phần token đã được cache.
Để hiểu cơ chế, cần nắm rõ token là gì trước. Mỗi lần gọi Claude API, model xử lý toàn bộ input: system prompt, tài liệu đính kèm, lịch sử hội thoại và câu hỏi của người dùng. Nếu system prompt của bạn dài 5,000 token và bạn gọi 500 request trong ngày, Claude xử lý 2,500,000 token cho system prompt, dù nội dung đó không thay đổi gì giữa các lần gọi.
Caching giải quyết đúng vấn đề này. Lần đầu tiên gọi, Claude xử lý phần prefix và ghi vào cache (cache write). Các lần sau, nếu phần đầu prompt giống hệt, Claude đọc thẳng từ cache (cache hit) với giá chỉ 10% so với xử lý lại. Bạn vẫn trả tiền cho output và phần user message, nhưng phần system prompt lớn được tính theo giá cache.
Cơ chế kỹ thuật là exact prefix matching: cache chỉ hit khi phần đầu prompt giống 100% với lần ghi. Thay đổi 1 ký tự trong system prompt? Cache miss hoàn toàn, phải xử lý lại từ đầu. Đây là lý do thiết kế prompt nên đặt phần ổn định (system instructions, tài liệu tham chiếu, ví dụ few-shot) lên đầu, phần thay đổi (câu hỏi user, timestamp, context động) xuống cuối. Xem chi tiết zero-shot và few-shot.
Tính năng này hỗ trợ tất cả model Claude active hiện tại, bao gồm Opus 4.7, Sonnet 4.6, và Haiku 4.5. Với mô hình ngôn ngữ lớn (LLM) có context window lớn như Claude, phần system prompt thường chiếm 60-80% tổng input token mỗi request, nên tiết kiệm 90% trên phần đó tạo ra khoản giảm chi phí rất đáng kể.
Prompt Caching Tiết Kiệm Được Bao Nhiêu?
Với system prompt 10,000 tokens và 100 requests mỗi ngày, prompt caching tiết kiệm $79.95/tháng, tức giảm 88.8% chi phí cho phần đó (Sonnet 4.6, tháng 4/2026). Dưới đây là cách mình tính chi tiết.
Scenario: System prompt 10,000 tokens, 100 requests mỗi ngày, TTL 5 phút
| Chỉ số | Không có caching | Có caching |
|---|---|---|
| Tokens xử lý mỗi ngày | 1,000,000 (1 MTok) | 10,000 (write) + 990,000 × 10% (reads) |
| Chi phí system prompt mỗi ngày | $3.00 | $0.038 + $0.297 = $0.335 |
| Chi phí mỗi tháng | $90 | $10.05 |
| Tiết kiệm | n/a | $79.95/tháng (88.8%) |
Đây chỉ là chi phí cho phần system prompt, chưa kể output và phần user message. Trong thực tế, Du’An Lightfoot, engineer dùng Claude API cho production chatbot, đã giảm hóa đơn từ $720 xuống $72/tháng sau khi implement prompt caching cho toàn bộ pipeline.
Với Claude Code của ongboit.com: mình check cache_read_input_tokens trên một ngày làm việc điển hình với CLAUDE.md khoảng 5,000 token. Kết quả: 73% input token trong ngày đó là cache reads, tức tiết kiệm khoảng $15-20 so với nếu không có caching.
Giá thực tế Sonnet 4.6 (theo Anthropic pricing, tháng 4/2026):
| Loại token | Giá |
|---|---|
| Base input | $3/MTok |
| Cache write (5 phút) | $3.75/MTok (1.25 lần giá base) |
| Cache write (1 giờ) | $6/MTok (2 lần giá base) |
| Cache read | $0.30/MTok (0.1 lần giá base) |
| Output | $15/MTok |

Implement Prompt Caching Như Thế Nào?
Có hai cách implement: automatic (nhanh, dùng cho hầu hết use case) và explicit breakpoints (kiểm soát chi tiết hơn khi cần cache từng phần riêng biệt).
Automatic caching: 1 dòng code
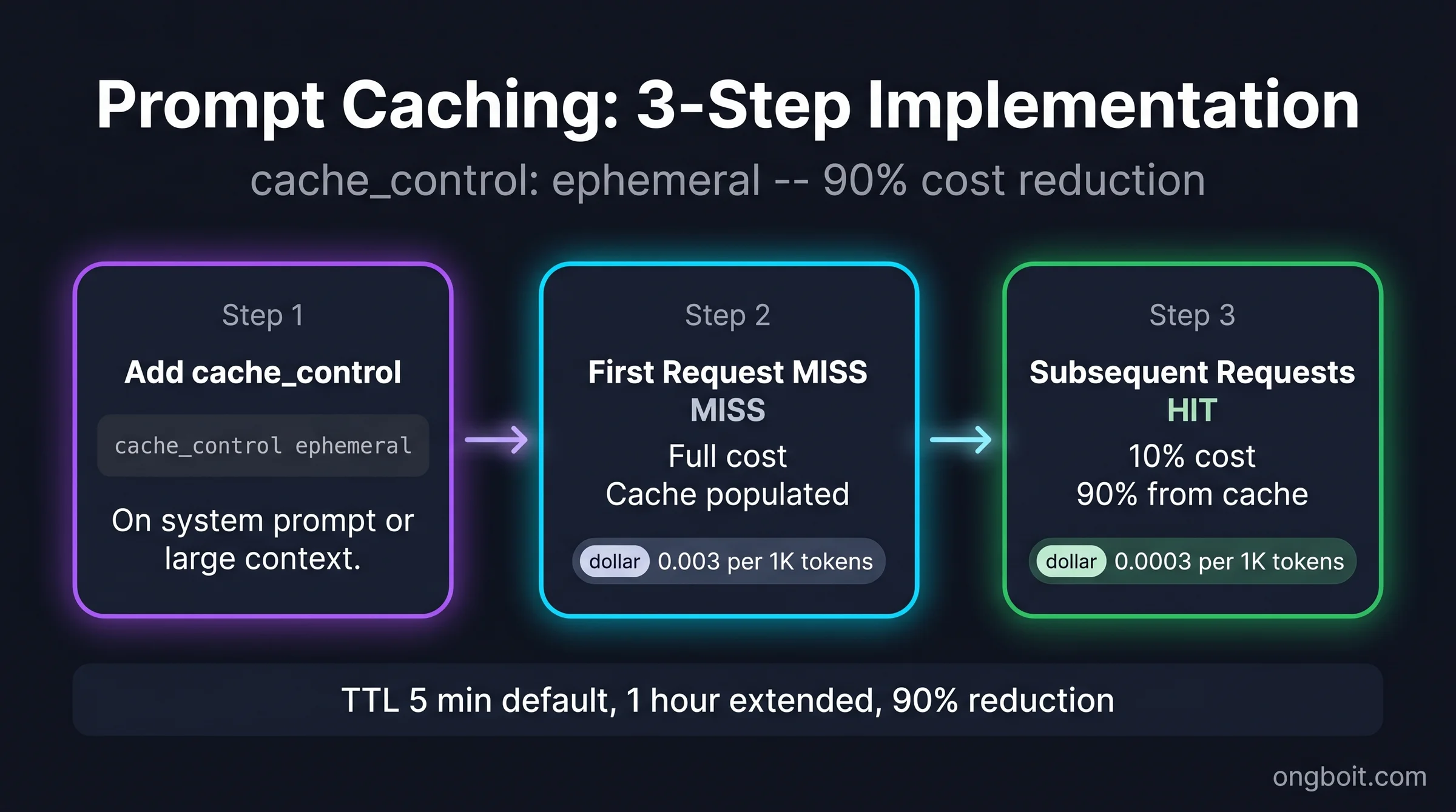
Thêm cache_control={"type": "ephemeral"} vào top level của messages.create(). System tự xác định chỗ đặt cache breakpoint tối ưu:
import anthropic
from tenacity import retry, stop_after_attempt, wait_exponential
client = anthropic.Anthropic()
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def ask_claude(user_question: str) -> str:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
cache_control={"type": "ephemeral"}, # dòng duy nhất cần thêm
system="[System prompt dài 2,000+ tokens của bạn: instructions, context, ví dụ]",
messages=[{"role": "user", "content": user_question}],
timeout=30,
)
# Kiểm tra cache performance:
usage = response.usage
print(f"Cache writes: {usage.cache_creation_input_tokens} tokens")
print(f"Cache reads: {usage.cache_read_input_tokens} tokens (rẻ hơn 90%)")
print(f"Regular input: {usage.input_tokens} tokens")
return response.content[0].textRequest đầu tiên: cache_creation_input_tokens sẽ lớn hơn 0 (đang ghi cache). Request thứ hai trở đi (trong vòng 5 phút): cache_read_input_tokens sẽ lớn hơn 0, bạn đang tiết kiệm 90%.
Explicit breakpoints: fine-grained control
Khi bạn muốn cache từng phần riêng biệt, ví dụ system instructions và document cache độc lập:
import anthropic
client = anthropic.Anthropic()
def analyze_document(document_text: str, question: str) -> str:
try:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": "Bạn là trợ lý phân tích tài liệu pháp lý chuyên nghiệp.",
# Không cache phần này (ngắn, thay đổi theo context)
},
{
"type": "text",
"text": document_text, # 40,000+ token document
"cache_control": {"type": "ephemeral"}, # Cache breakpoint ở đây
},
],
messages=[{"role": "user", "content": question}],
timeout=60,
)
return response.content[0].text
except anthropic.RateLimitError:
raise # Để tenacity retry
except anthropic.APIError as e:
print(f"API error: {e}")
raiseVới document 40,000 tokens, mỗi câu hỏi tiếp theo tiết kiệm: 40,000 × ($3 – $0.30)/MTok = $0.108 mỗi request. Một trăm câu hỏi về cùng document = $10.80 tiết kiệm thuần túy.
TTL 1 giờ cho batch jobs
Khi prompt được dùng định kỳ (không phải real-time):
import anthropic
from tenacity import retry, stop_after_attempt, wait_exponential
client = anthropic.Anthropic()
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def run_batch_job(content: str) -> str:
try:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "[System prompt 10,000 tokens cho batch job chạy mỗi 30 phút]",
"cache_control": {"type": "ephemeral", "ttl": "1h"}, # 1-hour TTL
},
],
messages=[{"role": "user", "content": content}],
timeout=30,
)
# Kiểm tra cache reads:
print(f"Cache reads: {response.usage.cache_read_input_tokens} tokens")
return response.content[0].text
except anthropic.RateLimitError:
raise # Tenacity retry sẽ xử lý
except anthropic.APIError as e:
print(f"API error: {e}")
raiseCache-First Cost Formula: Khi Nào Nên Cache?
Cache-First Cost Formula là rule of thumb mình dùng để quyết định nhanh, trả lời 3 câu hỏi:
- Prefix có ổn định không? System prompt, tài liệu, few-shot examples có thay đổi giữa các request?
- Prefix có đủ dài không? Sonnet 4.6 cần tối thiểu 2,048 tokens; Opus 4.7 cần 4,096 tokens
- Sẽ có nhiều requests không? Với TTL 5 phút: cần ít nhất 1 cache read để hòa vốn; với TTL 1 giờ: cần ít nhất 2 reads
Nếu cả 3 câu trả lời đều YES: cache là bắt buộc, không phải optional.
| Use case | Nên cache? | Lý do |
|---|---|---|
| Chatbot với system prompt 3,000 tokens | BẮT BUỘC | Prefix ổn định, nhiều turns |
| Document Q&A (40,000 token doc) | BẮT BUỘC | Document ổn định, nhiều câu hỏi |
| Few-shot prompting (20 examples) | NÊN | Examples ổn định, tiết kiệm lớn |
| Request đơn lẻ, một lần | KHÔNG | Không có cache read để hòa vốn |
| Dynamic prompt (user thay đổi system) | KHÔNG | Prefix không ổn định |
| Phân tích codebase với context window lớn | BẮT BUỘC | Context window lớn, tốn kém khi tính lại |
Cache-First Cost Formula áp dụng với bất kỳ LLM API nào có prompt caching, không chỉ Claude. OpenAI GPT-4o cũng có automatic prompt caching từ 2025, cơ chế tương tự.
Nên Chọn TTL 5 Phút Hay 1 Giờ?
Chọn TTL 5 phút cho chatbot và ứng dụng real-time, chọn TTL 1 giờ cho batch jobs chạy định kỳ. Sự khác biệt chính: cache write 5 phút tốn 1.25 lần giá base, cần 1 read để hòa vốn; cache write 1 giờ tốn 2 lần giá base, cần 2 reads mới có lãi.
| Tiêu chí | TTL 5 phút | TTL 1 giờ |
|---|---|---|
| Chi phí cache write | 1.25 lần giá base | 2 lần giá base |
| Chi phí cache read | 0.1 lần giá base | 0.1 lần giá base |
| Cần bao nhiêu reads để hòa vốn | 1 read | 2 reads |
| Tự động refresh khi được dùng | Có, miễn phí | Có, miễn phí |
| Phù hợp nhất với | Real-time chatbot, multi-turn | Batch jobs, phân tích định kỳ |
| Nên chọn khi | Interval giữa requests dưới 5 phút | Interval từ 5 phút đến 1 giờ |
Ví dụ quyết định thực tế:
- Chatbot customer support (users nhắn tin liên tục): chọn TTL 5 phút
- Batch phân tích hóa đơn chạy mỗi 30 phút: chọn TTL 1 giờ (cần ít nhất 2 batch runs để hòa vốn write cost)
- Report generation chạy mỗi đêm: caching không hiệu quả vì interval trên 1 giờ
Một điểm thường bị bỏ qua: cache tự động refresh (không tốn phí) mỗi khi được đọc trong TTL window. Nếu chatbot có user đang nhắn tin liên tục, cache của session đó tự renew, bạn không bị tính cache write thêm. Đây là thiết kế thông minh của Anthropic để khuyến khích dùng caching.
Prompt Caching Trong Claude Code Hoạt Động Thế Nào?
Đây là điều mình không biết cho đến khi check response usage lần đầu: Claude Code đã tự động implement prompt caching từ đầu, không cần config gì thêm từ phía người dùng.
Mỗi session Claude Code, toàn bộ nội dung CLAUDE.md và system prompt của tool được cache tự động vào đầu session. Khi bạn làm việc trong session dài với nhiều tool calls liên tiếp, phần lớn input token sẽ là cache reads, rẻ hơn 90% so với regular input.
Điều này giải thích tại sao Claude Code thường rẻ hơn so với gọi API thủ công với cùng context. Mình tính cho một session 4 giờ với CLAUDE.md 5,000 tokens và 200 tool calls:
- Nếu không có caching: 5,000 × 200 = 1,000,000 input tokens chỉ cho CLAUDE.md
- Có caching: 5,000 cache write + 995,000 × 0.1 = khoảng 104,500 effective tokens tính phí
- Tiết kiệm: khoảng $2.70 chỉ riêng CLAUDE.md trong một session làm việc
Nhân với 20 ngày làm việc mỗi tháng, chỉ riêng khoản này là hơn $50/tháng mà bạn không phải trả thêm so với khi dùng raw API không caching. Nếu muốn tối ưu thêm, xem 15 cách tiết kiệm token Claude Code với các chiến thuật bổ sung.
Prompt Caching Kết Hợp Với Phần Còn Lại Của Hệ Sinh Thái LLM Ra Sao?
Phần này giúp người đọc hiểu rõ vị trí của Prompt Caching trong toàn bộ hệ sinh thái LLM năm 2026. Hiểu được mối liên kết giữa các khái niệm giúp lập trình viên áp dụng kỹ thuật này hiệu quả cho dự án production, không chỉ là tối ưu chi phí mà còn là phần không thể thiếu của kiến trúc sản phẩm chất lượng cao.
Prompt Caching đặc biệt hiệu quả khi kết hợp với Context Engineering. Khi đội ngũ thiết kế context theo lớp ưu tiên với phần static ổn định ở đầu và phần dynamic thay đổi ở cuối, Prompt Caching hoạt động tối ưu vì có thể tận dụng được phần static được lặp lại nhiều lần. Pattern khôn ngoan là cấu trúc prompt theo thứ tự rõ ràng từ ổn định nhất đến thay đổi nhất, đặt mọi thông tin có thể cache vào nửa đầu prompt để hệ thống dễ dàng nhận diện và lưu trữ tạm thời.
Khi nói về tối ưu chi phí cho dự án production, Prompt Caching là một trong những kỹ thuật quan trọng nhất song hành với pattern viết prompt hiệu quả. Để hiểu sâu hơn về các Prompt Engineering pattern nâng cao, người dùng nên tham khảo Prompt Engineering cho Claude Code. Tài liệu này tổng hợp 10 khái niệm cơ bản bao gồm Prompt Caching, token, context window, và nhiều kỹ thuật khác. Hiểu được cách các kỹ thuật này kết hợp với nhau giúp đội ngũ phát triển sản phẩm xây dựng pipeline tối ưu chi phí ngay từ thiết kế ban đầu, không phải tối ưu sau khi hóa đơn đã vượt dự kiến.
Áp Dụng Prompt Caching Cho Đội Nhóm Việt Nam Năm 2026 Cần Lưu Ý Gì?
Phần này tổng hợp 3 lưu ý quan trọng khi áp dụng Prompt Caching cho đội nhóm phát triển sản phẩm tại Việt Nam. Mỗi lưu ý đều rút ra từ kinh nghiệm thực chiến của các đội nhóm đã triển khai thành công trong 6 tháng đầu năm 2026.
Lưu ý đầu tiên là về việc đánh giá đúng khối lượng request trước khi áp dụng Prompt Caching. Caching chỉ thực sự hiệu quả khi cùng một phần prompt được lặp lại nhiều lần trong khoảng thời gian ngắn. Đối với sản phẩm có khối lượng request thấp như chatbot tư vấn nội bộ chỉ có vài chục cuộc trò chuyện mỗi ngày, chi phí thiết lập caching cao hơn so với lợi ích tiết kiệm. Đối với sản phẩm có traffic lớn như chatbot chăm sóc khách hàng đại trà với hàng nghìn cuộc trò chuyện mỗi ngày, Prompt Caching là kỹ thuật bắt buộc để giữ chi phí ở mức hợp lý.
Lưu ý thứ hai là về việc thiết kế cấu trúc prompt để tối ưu cache hit rate. Cache hit rate là tỉ lệ phần trăm request có thể tận dụng được phần đã lưu trong cache. Để đạt tỉ lệ cao, System Prompt và các tài liệu tham khảo cần được đặt ở vị trí cố định trong cấu trúc prompt. Pattern khôn ngoan là xây dựng template prompt tiêu chuẩn cho toàn đội ngũ, mọi thành viên đều tuân thủ cấu trúc này khi gọi API. Cách làm này đảm bảo cache hit rate cao và ổn định, không phụ thuộc vào phong cách cá nhân của từng lập trình viên.
Lưu ý cuối cùng là về việc giám sát hiệu quả thực tế của Prompt Caching qua các chỉ số đo lường cụ thể. Mặc dù lý thuyết cho thấy caching tiết kiệm được 90% chi phí cho phần đã cache, nhưng thực tế có thể thấp hơn nhiều nếu cấu trúc prompt không phù hợp hoặc khoảng thời gian giữa các lần gọi quá lâu. Pattern khôn ngoan là thiết lập dashboard giám sát hiển thị cache hit rate hằng ngày, chi phí thực tế tiết kiệm được so với không dùng cache, và phân tích các trường hợp cache miss để tinh chỉnh cấu trúc prompt. Đầu tư 2-3 ngày thiết lập dashboard giám sát ban đầu giúp đội ngũ liên tục tối ưu hiệu quả của kỹ thuật này theo thời gian, đảm bảo lợi ích tiết kiệm chi phí được duy trì ổn định cho dự án production dài hạn của doanh nghiệp.
Câu Hỏi Thường Gặp
Prompt caching có hoạt động với mọi model Claude không?
Có, tất cả model Claude active đều support prompt caching: Opus 4.7, Opus 4.6, Sonnet 4.6, Haiku 4.5 và các phiên bản cũ hơn. Điểm khác nhau là minimum token threshold: Sonnet 4.6 cần tối thiểu 2,048 tokens, còn Opus 4.7 và Haiku 4.5 cần 4,096 tokens. Nếu prefix ngắn hơn threshold, API xử lý bình thường, không có lỗi nhưng cũng không có cache benefit.
Cache có bị share giữa các users hoặc workspace khác không?
Không. Từ ngày 5/2/2026, Anthropic đã chuyển sang workspace-level isolation: cache của bạn chỉ accessible trong cùng một workspace API. Nếu tổ chức có nhiều workspace (dev workspace và prod workspace riêng biệt), cache giữa chúng là hoàn toàn độc lập. Không có rủi ro về data leakage giữa users hay projects.
Nếu thay đổi 1 ký tự trong system prompt thì cache có bị mất không?
Có, cache sẽ miss hoàn toàn cho phần bị thay đổi và mọi content sau đó. Caching hoạt động theo exact prefix matching, không có fuzzy matching hay partial caching. Đây là lý do thiết kế prompt nên đặt phần ổn định (system instructions, documents, examples) trước phần dynamic (user input, timestamp, session-specific data) để tối đa hóa cache hit rate.
Prompt caching có giảm latency không, hay chỉ giảm cost?
Cả hai. Cache hit không chỉ tiết kiệm 90% cost mà còn nhanh hơn tới 80% về latency, vì model không cần process lại phần đã cache. Với document analysis dài 100,000 tokens (khoảng 75,000 từ), cache hit có thể giảm thời gian response từ 8-10 giây xuống 2-3 giây. Với real-time chatbot, latency giảm tạo ra trải nghiệm người dùng tốt hơn rõ rệt.
Tối đa bao nhiêu cache breakpoints trong 1 request?
4 explicit breakpoints mỗi request. Automatic caching sử dụng 1 slot và tự động quản lý. Trong thực tế, 4 breakpoints là đủ cho hầu hết use case: system prompt base, document lớn, few-shot examples, conversation history, mỗi phần là 1 breakpoint riêng. Nếu cần nhiều hơn 4, nên xem xét restructure prompt hoặc dùng system prompt ngắn gọn hơn.
Kết Luận
Cache-First Cost Formula là checklist 3 câu hỏi nhanh nhất để quyết định có nên implement prompt caching không: prefix ổn định? đủ dài (trên 2,048 tokens với Sonnet 4.6)? nhiều requests? Ba câu đều YES thì cache là bắt buộc, không phải tùy chọn.
Với Sonnet 4.6, cost math rất rõ ràng: cache read = $0.30/MTok thay vì $3/MTok. Một system prompt 10,000 tokens dùng 100 request mỗi ngày = tiết kiệm $79.95/tháng chỉ từ 1 dòng code thêm vào. Đây là tối ưu có ROI cao nhất và công sức thấp nhất trong toàn bộ stack API, không phụ thuộc vào model hay trường hợp sử dụng cụ thể nào.
Điều quan trọng cần nhớ: nếu bạn đang dùng Claude Code hàng ngày, tính năng này đã hoạt động tự động mà bạn không cần làm gì thêm. Còn nếu xây dựng ứng dụng dùng Claude API trực tiếp, thêm cache_control={"type": "ephemeral"} vào request là bước đầu tiên mình khuyên làm trước bất kỳ tối ưu nào khác.
Nếu bạn đang tối ưu chi phí toàn diện hơn, xem thêm 15 cách tiết kiệm token Claude Code: prompt caching là một trong nhiều chiến thuật giúp giảm từ $300 xuống $80/tháng.