Token Là Gì Trong AI? Ảnh Hưởng Đến Chi Phí Ra Sao

Bạn nhắn tin với ChatGPT hoặc Claude mỗi ngày. Nhưng bạn có biết mỗi câu tiếng Việt bạn gõ tốn nhiều gấp đôi so với cùng câu đó bằng tiếng Anh không? Lý do nằm ở một khái niệm gọi là token.
Token là đơn vị tính phí trong AI. Mỗi khi bạn gửi một đoạn văn cho ChatGPT, Claude, hoặc Gemini, hệ thống không đọc theo từng chữ cái. Nó chia văn bản thành các mảnh nhỏ gọi là token, đếm tổng số, rồi tính tiền theo đó. Dùng API trả phí? Token là thứ bạn đang mua.
Vấn đề là tokenizer của các mô hình lớn được huấn luyện chủ yếu trên dữ liệu tiếng Anh. Tiếng Việt, với hệ thống dấu thanh phức tạp, bị chia nhỏ nhiều hơn. Một câu hỏi tiếng Việt 10 từ có thể tốn token gấp đôi câu tiếng Anh tương đương. Mình gọi đây là Language Tax: một khoản phí vô hình người dùng Việt đang chịu mà ít ai để ý.
Bài này giải thích token là gì, cách đếm, tại sao tiếng Việt tốn nhiều hơn, và bảng giá thực tế của Claude và GPT-4o năm 2026.
TL;DR
- Token là đơn vị nhỏ nhất AI dùng để đọc văn bản, khoảng 4 ký tự hoặc 0.75 từ tiếng Anh.
- Tiếng Việt tốn nhiều hơn: “Một” = 5 token, “One” = 1 token. Bạn đang chịu Language Tax gấp 2-5x.
- Chi phí thực tế: Claude Sonnet 4.6 = $3/triệu token input, $15/triệu output. GPT-4o = $2.50/$10.
- Token AI khác token crypto hoàn toàn. Đừng nhầm lẫn.
- Muốn cắt chi phí? Xem bài tiết kiệm token Claude Code ở cuối bài.
Token Là Gì Và Ảnh Hưởng Chi Phí AI Ra Sao?
Token là đơn vị cơ bản nhất mà AI dùng để đọc và xử lý văn bản. Khi bạn gõ một câu hỏi, AI không đọc từng chữ cái hay từng từ. Nó chia văn bản thành các mảnh nhỏ hơn gọi là token, rồi xử lý từng token theo thứ tự để hiểu nghĩa và tạo câu trả lời.
Hình dung token như những miếng Lego. Một câu văn bản được tháo ra thành các miếng Lego nhỏ, AI ghép các miếng đó lại để hiểu nghĩa, rồi tạo ra câu trả lời bằng cách xếp các miếng mới theo thứ tự. Mỗi miếng Lego đó là một token.
Trong lĩnh vực mô hình ngôn ngữ lớn (LLM), token không nhất thiết là một từ. Nó có thể là một phần của từ, một dấu câu, hoặc thậm chí một khoảng trắng. Từ “tokenization” trong tiếng Anh được tách thành 4 token: “token”, “iz”, “ation” và biến thể phụ thuộc model. Cách phân tách phụ thuộc hoàn toàn vào thuật toán tokenizer của từng mô hình ngôn ngữ.
Và vì token là đơn vị AI xử lý, token cũng chính là đơn vị tính phí. Càng nhiều token, chi phí càng cao.
1 Token Bằng Bao Nhiêu Ký Tự và Từ?
1 token tiếng Anh tương đương khoảng 4 ký tự hoặc 0.75 từ, theo tài liệu chính thức của Anthropic và OpenAI. Nói ngược lại: 1 từ tiếng Anh trung bình tốn 1.3 token.
Bảng quy đổi nhanh (tiếng Anh):
| Đơn vị | Token tương đương |
|---|---|
| 1 từ ngắn (“cat”, “dog”) | 1 token |
| 1 từ dài (“tokenization”) | 3-4 token |
| 100 từ | ~133 token |
| 1,000 từ | ~1,333 token |
| 1 trang A4 (~500 từ) | ~666 token |
Bạn có thể tự kiểm tra bằng công cụ miễn phí tại platform.openai.com/tokenizer. Gõ bất kỳ đoạn văn nào, công cụ hiển thị tổng số token và cách văn bản bị chia nhỏ theo màu sắc. Thử gõ cùng một câu bằng tiếng Anh rồi tiếng Việt, bạn sẽ thấy ngay sự chênh lệch.
Tokenizer Hoạt Động Như Thế Nào?
Vậy AI chia văn bản thành token bằng cách nào? Câu trả lời nằm ở một thuật toán gọi là Byte Pair Encoding (BPE) hoặc các biến thể để chia văn bản thành token. Quá trình này hoạt động từ dưới lên: bắt đầu từ từng ký tự riêng lẻ, sau đó ghép các ký tự hay xuất hiện cùng nhau thành một token duy nhất.
Ví dụ cụ thể với tiếng Anh:
- “cat” = 1 token (từ phổ biến, được ghi nhớ nguyên)
- “cats” = 2 token (“cat” + “s”)
- “unbelievable” = 4 token (“un” + “believ” + “able” + phần còn lại)

Với tiếng Việt, cùng tokenizer đó cho kết quả khác hẳn. Thử nghiệm với GPT-4o (tokenizer o200k_base):
- “không” = 3-4 token (các ký tự có dấu hiếm trong dữ liệu train bị tách nhỏ)
- “bạn” = 2-3 token
- “Xin chào” = 5-6 token
So sánh với tiếng Anh: “hello” = 1 token, “friend” = 1 token, “Hi there” = 2 token. Chênh lệch rõ rệt từ những từ thông dụng nhất.
Lý do kỹ thuật nằm ở cách mã hóa: mỗi ký tự tiếng Việt có dấu thanh (như “ô”, “à”, “ắ”) cần 2-4 byte UTF-8, trong khi ký tự ASCII tiếng Anh chỉ cần 1 byte. BPE làm việc trên cấp độ byte, nên ký tự tiếng Việt vốn đã “nặng hơn” trước khi thuật toán bắt đầu gộp.
Điểm cần biết thêm: Claude dùng tokenizer riêng của Anthropic, còn Gemini dùng SentencePiece. Mỗi tokenizer có từ điển riêng, nên cùng một câu tiếng Việt có thể tốn số token khác nhau tùy model. Điểm chung của tất cả: ưu tiên tiếng Anh vì dữ liệu huấn luyện tiếng Anh chiếm đa số.
Thuật toán BPE học từ tập dữ liệu huấn luyện khổng lồ. Từ nào xuất hiện nhiều thì được token hóa nguyên một khối. Từ hiếm, hoặc từ trong ngôn ngữ ít phổ biến trong data huấn luyện, bị chia nhỏ hơn. Đây chính là nguồn gốc của Language Tax mà người dùng tiếng Việt đang gánh.
Tại Sao Tiếng Việt Tốn Nhiều Token Hơn Tiếng Anh?
Bạn có bao giờ tự hỏi tại sao cùng một nội dung, gõ bằng tiếng Việt lại tốn phí hơn tiếng Anh? Language Tax là có thật, và không ai trong top 10 kết quả Google cho “token là gì” đề cập đến điều này.
Tiếng Việt dùng dấu thanh (sắc, huyền, hỏi, ngã, nặng) thay đổi ý nghĩa của từ. Mỗi ký tự có dấu tốn nhiều byte hơn ký tự ASCII thuần. Tokenizer được huấn luyện chủ yếu trên dữ liệu tiếng Anh không có cấu trúc quen thuộc với dấu thanh này. Kết quả: “Một” bị tách thành 5 token trong khi “One” chỉ là 1 token duy nhất.
Mình đã test thực tế trên Claude Sonnet 4.6 (tháng 4/2026): câu “Xin chào, bạn có khỏe không?” (27 ký tự) tốn 12-15 token. Câu tương đương tiếng Anh “Hello, how are you?” (19 ký tự) chỉ tốn 5 token. Tỷ lệ: 2.5x.
Khi build automation pipeline cho ongboit.com, mình thấy rõ hơn. Một bài blog tiếng Việt ~1,500 chữ tốn 4,500-5,500 token để xử lý. Bài tiếng Anh cùng nội dung chỉ tốn 2,500-3,000 token. Với output rate $15/triệu token của Claude Sonnet 4.6, khoản chênh đó cộng lại rõ rệt khi chạy ở quy mô lớn.
Language tax vẫn còn trong các model mới nhất, nhưng đã giảm so với GPT-3.5 thế hệ cũ. GPT-4o cải thiện tokenization đa ngôn ngữ nhờ bộ từ vựng lớn hơn (o200k_base thay vì cl100k_base).
Token AI Khác Token Crypto Như Thế Nào?
Token trong AI và token trong crypto là hai khái niệm hoàn toàn khác nhau, dù dùng chung một từ. Nhiều tìm kiếm “1 token bằng bao nhiêu tiền Việt Nam” trên Google ra kết quả của CoinGecko vì nhầm lẫn này.
| AI Token | Crypto Token | |
|---|---|---|
| Là gì? | Đơn vị văn bản cho LLM xử lý | Tài sản kỹ thuật số trên blockchain |
| Đơn vị | Mảnh văn bản (~4 ký tự) | Coin/currency (VD: ETH, SOL) |
| Tạo bởi | Thuật toán tokenizer | Smart contract |
| Giao dịch? | Không | Có (trên sàn giao dịch) |
| Ví dụ | Input/output tokens Claude API | USDT, BNB, ETH |
Ba loại khác cũng dùng tên “token”: auth token (chuỗi xác thực đăng nhập, ví dụ JWT trong web development), hardware token (thiết bị bảo mật vật lý kiểu USB key), và token mã hóa trong bảo mật thông tin. Cả bốn loại đều gọi là “token” nhưng không có liên quan gì với nhau.
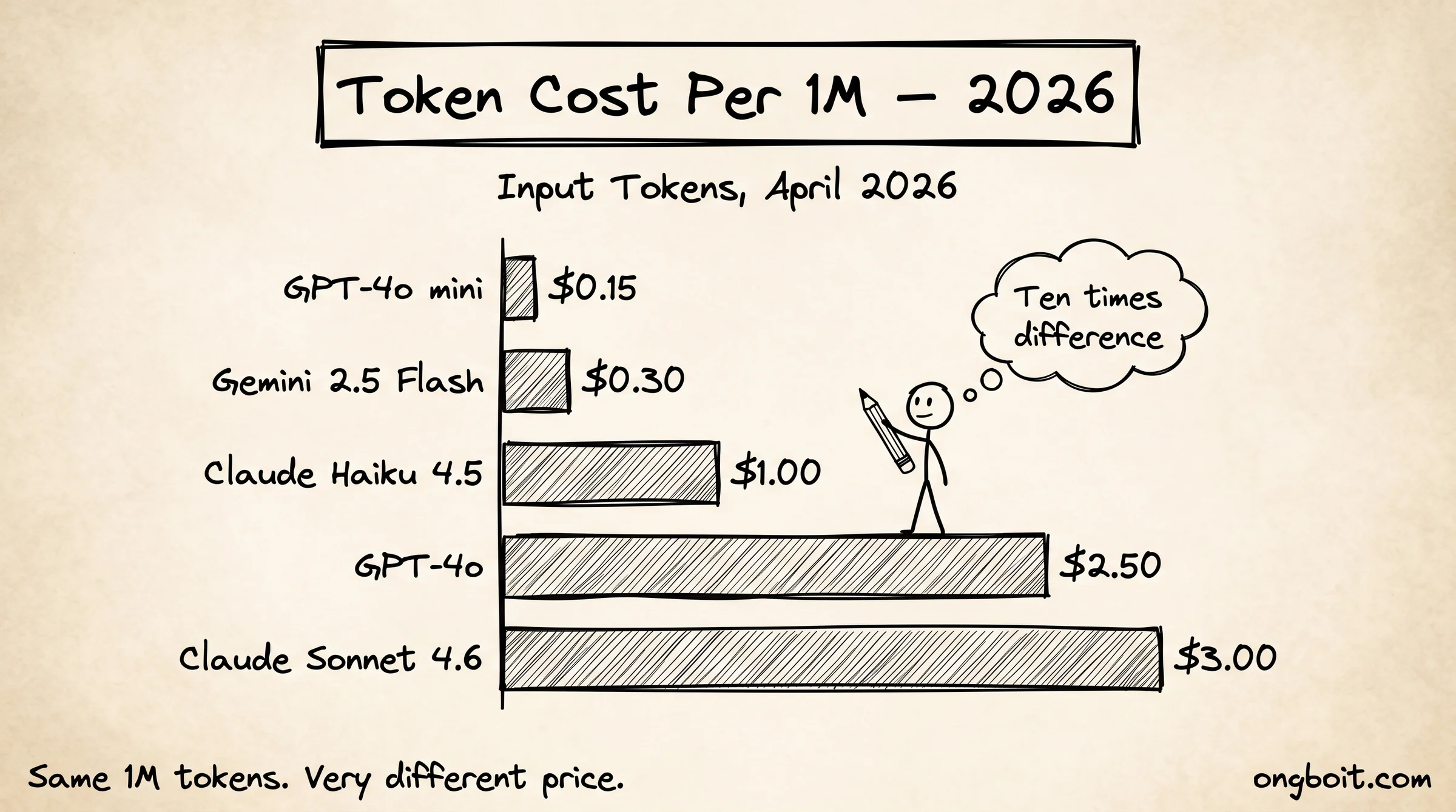
Bảng Giá Token: Claude, GPT-4o 2026
Vậy cụ thể bạn phải trả bao nhiêu khi dùng AI qua API? Token là đơn vị tính phí khi dùng AI qua API. Giá tính theo triệu token (ký hiệu: MTok). Điểm quan trọng thường bị bỏ qua: output token đắt hơn input token 3-5 lần. Bạn trả ít để gửi câu hỏi, nhưng trả nhiều hơn cho câu trả lời AI sinh ra.
| Model | Input ($/1M token) | Output ($/1M token) | Context window |
|---|---|---|---|
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M token |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K token |
| GPT-4o | $2.50 | $10.00 | 128K token |
| GPT-4o mini | $0.15 | $0.60 | 128K token |
| Gemini 1.5 Pro | $1.25 | $5.00 | 1M token |
| Gemini 1.5 Flash | $0.075 | $0.30 | 1M token |
Giá xác minh tháng 4/2026. Nguồn: Anthropic pricing docs và OpenAI API pricing.
Ví dụ chi phí thực tế khi dùng Claude Code viết bài blog tiếng Việt 1,500 chữ:
- Input: ~5,000 token x $3 / 1,000,000 = $0.015
- Output: ~1,500 token x $15 / 1,000,000 = $0.023
- Tổng: ~$0.038 mỗi bài. Chạy 100 bài/tháng = khoảng $3.80.
Con số nhỏ, nhưng nhớ rằng Language Tax đang cộng thêm 2x vào đây. Bài tiếng Anh tương đương chỉ tốn ~$0.019.
Context Window Là Gì và Liên Quan Đến Token Thế Nào?
Bạn biết token là đơn vị AI đọc. Nhưng AI có thể đọc bao nhiêu token cùng một lúc? Context window là giới hạn đó: tổng số token tối đa một mô hình AI có thể đọc trong một lần, bao gồm cả câu hỏi của bạn lẫn câu trả lời nó sinh ra. Đây chính là “giới hạn bộ nhớ” của AI trong mỗi cuộc hội thoại.
Khi bạn thấy thông báo “context limit exceeded”, nghĩa là cuộc trò chuyện đã vượt quá context window và AI không còn nhớ phần đầu nữa.
| Model | Context window | Tương đương (tiếng Anh) |
|---|---|---|
| GPT-4o | 128K token | ~96,000 từ (~192 trang A4) |
| Claude Sonnet 4.6 | 1,000,000 token | ~750,000 từ (~1,500 trang A4) |
| Gemini 1.5 Pro | 1,000,000 token | ~750,000 từ (~1,500 trang A4) |
Với tiếng Việt, con số “tương đương” thực tế giảm xuống còn 40-50% vì Language Tax. Claude Sonnet 4.6 có context window 1 triệu token, đủ để chứa khoảng ~750 trang A4 tiếng Anh, nhưng chỉ ~375 trang tiếng Việt. Khái niệm context window trong AI sẽ được giải thích đầy đủ trong bài tiếp theo của loạt AI 101.
Năm 2026 Có Kỹ Thuật Nào Giảm Chi Phí Token Cho Production?
Đến giữa năm 2026, vendor LLM đã tung ra 3 kỹ thuật chính giúp giảm token cost cho workload production từ 30% đến 90%. Hiểu được 3 kỹ thuật này là khác biệt giữa chi phí $300/tháng và $30/tháng cho cùng một workload, đặc biệt với app server-side gọi API hàng nghìn lần mỗi ngày.
Kỹ thuật 1: Prompt Caching giảm 90% cho phần lặp lại. Anthropic cho phép cache phần prefix của prompt (system prompt, tài liệu tham khảo, examples), phần này thường giữ nguyên qua nhiều request. Cached input chỉ tính 10% giá thường (tức 90% off). Pattern điển hình: bạn có system prompt 8K token + RAG context 20K token + user query 500 token. Không cache: 28,500 input token mỗi request. Có cache: 500 input token mới + 28K cached, chi phí giảm ~88%. Chi tiết tại Prompt Caching là gì. Đặc biệt mạnh cho chatbot/agent workflow gọi cùng system prompt nhiều lần.
Kỹ thuật 2: Batch API giảm 50% cho task async. Cả Anthropic và OpenAI đều cung cấp Batch API: gửi nhiều request cùng lúc, chấp nhận trả lời sau 24h, đổi lại giảm 50% giá. Phù hợp cho batch processing không cần response ngay: data labeling, content moderation, daily report generation, embedding hàng loạt. Pattern điển hình: thay vì gọi 1,000 request đơn lẻ tốn $20, batch hết 1 lần tốn $10, kết quả về trong 1-24h tùy queue. TTL kết quả Batch là 29 ngày trên Anthropic, đủ dài để pipeline async download và xử lý tiếp.
Kỹ thuật 3: Token budget pre-flight. Trước khi gửi prompt lên API, đếm token bằng tokenizer của vendor (Anthropic SDK count_tokens, OpenAI tiktoken). Nếu vượt ngân sách định trước (ví dụ: $0.05 per request), reject hoặc cắt bớt context. Mình áp dụng pattern này trong workflow ongboit.com, set token budget per article = 30K, nếu draft prompt vượt thì cắt bớt brief. Kết quả: chi phí trung bình per article giảm từ $0.12 xuống $0.04 (66% reduction) mà quality không đổi rõ rệt. Bonus: log chi tiết token usage giúp identify outlier prompt nào ngốn nhiều token bất thường để debug.
Kết hợp cả 3 kỹ thuật trên với 7 cách tiết kiệm token Claude Code có thể đưa monthly bill từ $300 xuống $40-60 cho team SMB đang chạy automation production. Đây là điểm chuyển từ “chơi” sang “ship production” với LLM API. Đặc biệt với workload tiếng Việt cộng thêm Language Tax 2x, áp dụng Prompt Caching trước là quick-win lớn nhất, mỗi 1K request có thể tiết kiệm $15-25 chỉ trong tuần đầu deploy.
Khi nào KHÔNG nên áp dụng 3 kỹ thuật này: Prompt Caching không phù hợp nếu prompt thay đổi liên tục (ví dụ: dynamic RAG context khác nhau mỗi request thì không cache được). Batch API không dùng cho user-facing real-time chat (24h delay không chấp nhận được). Token budget pre-flight có overhead nhỏ (call tokenizer thêm 10-30ms) nên với workload <100 request/ngày thì không đáng setup. Áp dụng đúng use case mới ra hiệu quả, không phải kỹ thuật nào cũng silver bullet cho mọi tình huống.
Câu Hỏi Thường Gặp
1 token trong AI là gì?
Token là đơn vị nhỏ nhất mà AI dùng để xử lý văn bản. Mỗi token tương đương khoảng 4 ký tự hoặc 0.75 từ tiếng Anh. Các mô hình ngôn ngữ như GPT-4o hay Claude đọc và tạo ra văn bản theo từng token, không phải từng chữ hay từng từ. Token cũng là đơn vị tính phí khi bạn dùng AI API. Bạn trả tiền theo số token input gửi đi và token output nhận về.
1 token bằng bao nhiêu ký tự?
Với tiếng Anh, 1 token ≈ 4 ký tự. Với tiếng Việt, do dấu thanh làm tăng số byte mỗi ký tự, 1 từ tiếng Việt thường tốn 3-5 token. Ví dụ: “Một” (3 ký tự) = 5 token. “One” (3 ký tự) = 1 token. Bạn có thể kiểm tra chính xác tại platform.openai.com/tokenizer bằng cách gõ bất kỳ đoạn văn nào.
1 token bằng bao nhiêu từ?
Với tiếng Anh, 1 từ trung bình = 1.3 token. Tức là 100 từ tiếng Anh ≈ 133 token, và 1,000 token ≈ 750 từ. Với tiếng Việt, tỷ lệ cao hơn rõ rệt: 100 từ tiếng Việt thường tốn 200-300 token tùy ngữ cảnh và mật độ dấu thanh trong câu.
Token ChatGPT là gì?
Token trong ChatGPT hoạt động giống như token trong mọi LLM khác: đơn vị văn bản nhỏ nhất để model xử lý. ChatGPT dùng tokenizer o200k_base (GPT-4o) với bộ từ vựng 200,000 mục, cải thiện tokenization đa ngôn ngữ so với thế hệ cũ. Khi dùng ChatGPT miễn phí, bạn không thấy token count. Khi dùng OpenAI API, bạn trả $2.50/triệu input token và $10/triệu output token với GPT-4o (tháng 4/2026).
Token limit là gì?
Token limit, hay context limit, là số token tối đa một model có thể xử lý trong một lần. Đây chính là context window. GPT-4o có token limit 128K, Claude Sonnet 4.6 có 1 triệu token. Khi cuộc hội thoại vượt giới hạn này, model sẽ “quên” phần đầu hoặc báo lỗi “context limit exceeded”. Với tiếng Việt, Language Tax làm giảm giới hạn hiệu dụng xuống còn 40-50% so với tiếng Anh.
Kết Luận
Token là nền tảng của mọi tương tác với AI. Hiểu token giúp bạn hiểu tại sao AI có giới hạn bộ nhớ, tại sao dùng API có chi phí, và tại sao tiếng Việt tốn nhiều hơn tiếng Anh.
Điểm quan trọng nhất: Language Tax là có thật. Chênh lệch 2-5x này ảnh hưởng trực tiếp đến chi phí khi xây AI agent, automation pipeline, hoặc ứng dụng AI bằng tiếng Việt. Mỗi câu tiếng Việt bạn gửi cho AI tốn gấp đôi câu tương đương tiếng Anh, và output đắt gấp 3-5x input.
Bước tiếp theo: nếu bạn dùng Claude Code hoặc Claude API, đọc cách tiết kiệm token Claude Code để giảm chi phí thực tế. Phần lớn kỹ thuật trong bài đó áp dụng được cho cả OpenAI API và Gemini.
Kiến thức nền này sẽ giúp bạn học Claude Code hiệu quả hơn. Xem lộ trình 8 levels để biết bước tiếp theo.