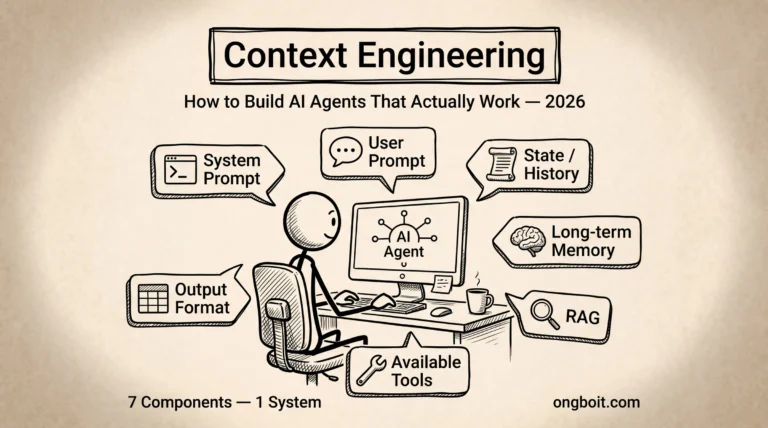
AI Hallucination Là Gì? Phát Hiện Khi AI Đang Bịa
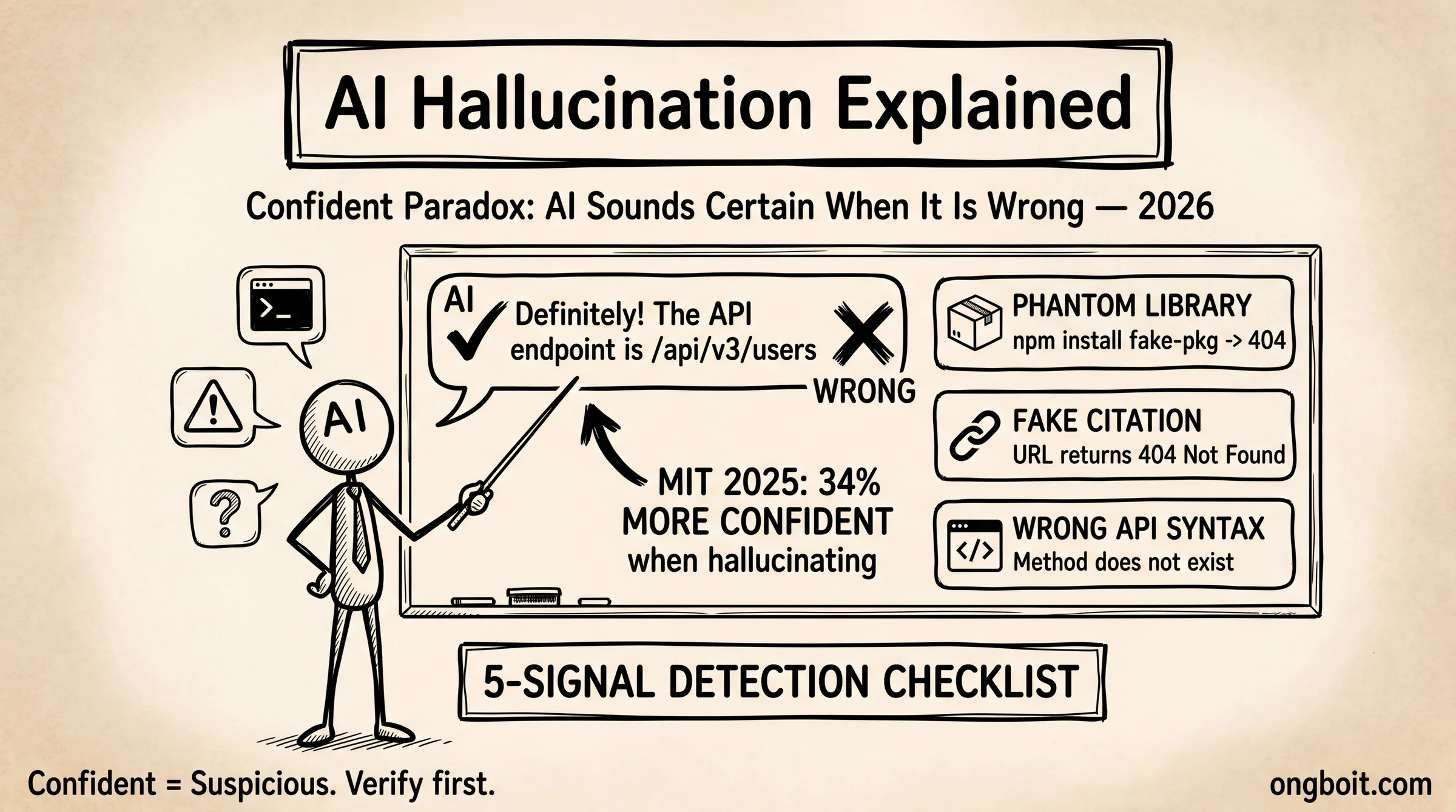
AI bịa thông tin là điều bạn đã biết. Nhưng có một điều ít ai nói đến: nghiên cứu MIT (2025) phát hiện AI dùng ngôn ngữ tự tin hơn 34% khi đang nói sai so với khi nói đúng. Không phải “có thể”, không phải “mình nghĩ là”, mà là “chắc chắn rồi”, “đúng vậy”. AI hallucination nguy hiểm không phải vì AI sai, mà vì AI sai một cách cực kỳ thuyết phục.
Mình gọi đây là Confident Paradox, tức nghịch lý tự tin. Nó giải thích tại sao developer dày dạn kinh nghiệm vẫn bị AI dắt mũi, tại sao bạn copy code từ Claude rồi mất 2 tiếng debug một thư viện không tồn tại.
Bài này giải thích AI hallucination là gì, tại sao nó xảy ra, và quan trọng hơn: 5 dấu hiệu thực tế để bắt được khi AI đang bịa, trước khi bạn tốn thêm thời gian nữa.
Mình viết bài này từ góc độ người dùng hàng ngày, không phải nghiên cứu viên. Sau nhiều lần bị dắt mũi bởi thông tin nghe rất chắc chắn nhưng hóa ra sai, mình xây dựng thói quen xác minh trước khi sử dụng bất kỳ số liệu hay đoạn mã nào từ trợ lý AI.
TL;DR
- AI hallucination là khi AI tạo ra thông tin sai lệch nhưng trình bày với giọng điệu hoàn toàn tự tin.
- Confident Paradox: MIT 2025: AI dùng ngôn ngữ tự tin hơn 34% khi đang sai. Nghe chắc = nghi ngờ trước.
- Model tốt nhất vẫn sai: Claude Sonnet 4.4%, GPT-4o 1.5% trên bài test đơn giản, nhưng tất cả vượt 10% trên câu hỏi khó.
- 5 dấu hiệu phát hiện + framework CRISP giảm thiểu.
- Không thể tránh 100%, nhưng hoàn toàn kiểm soát được.
Confident Paradox: AI nghe tự tin nhất khi đang sai nhất. MIT 2025 đo được AI dùng ngôn ngữ khẳng định nhiều hơn 34% khi hallucinate.
AI Hallucination Là Gì?
AI hallucination là hiện tượng mô hình ngôn ngữ lớn (LLM) tạo ra thông tin sai lệch, không tồn tại, hoặc không có cơ sở, nhưng trình bày với giọng văn hoàn toàn chắc chắn như thể đó là sự thật. Khác với lỗi thông thường, hallucination không có cảnh báo, không có dấu hiệu nghi ngờ từ AI.
Tên “hallucination” (ảo giác) không phải ngẫu nhiên: giống như người mắc chứng ảo giác nhìn thấy thứ không tồn tại và hoàn toàn tin vào đó, AI tạo ra thông tin không có thật và không nhận ra mình đang sai. Điểm đáng lo ngại là cả hai trường hợp đều thiếu cơ chế tự kiểm tra nội tại.
Trong thực tế, hallucination xảy ra theo nhiều mức độ: từ số liệu bị bóp méo nhẹ, đến tên người bị nhầm, cho đến việc bịa hoàn toàn một sự kiện chưa từng xảy ra. Mức độ nhẹ thường khó phát hiện nhất vì thông tin nghe có vẻ đúng nhưng sai ở chi tiết quan trọng.
Điểm quan trọng: AI hallucination không phải lỗi kỹ thuật có thể vá bằng một bản update. Đây là vấn đề xuất phát từ cách thiết kế cơ bản của hệ thống trí tuệ nhân tạo hiện đại, không phải sơ suất của nhà phát triển. Nó là hệ quả trực tiếp từ cách LLM hoạt động: dự đoán token theo xác suất, không tra cứu sự thật tuyệt đối.
Nếu bạn đang dùng bất kỳ trợ lý trí tuệ nhân tạo nào, hiện tượng bịa thông tin là rủi ro luôn hiện diện, cần quản lý chứ không thể loại bỏ. Chấp nhận thực tế này giúp bạn xây dựng quy trình làm việc an toàn hơn thay vì ảo tưởng về sự hoàn hảo của công cụ.
Tại Sao AI Tự Tin Bịa Thông Tin?
Để hiểu AI hallucination, bạn cần hiểu LLM hoạt động thế nào: mô hình không “tra Google”, không có cơ sở dữ liệu sự thật. Mỗi từ được chọn dựa trên xác suất. Token nào tiếp theo nghe “tự nhiên nhất” trong ngữ cảnh hiện tại. Khi thiếu thông tin chính xác, model ưu tiên câu văn mượt mà hơn độ chính xác.
Đây là lúc Confident Paradox xuất hiện. MIT (2025) phát hiện: khi AI đang hallucinate, nó dùng ngôn ngữ khẳng định (“definitely”, “certainly”, “chắc chắn rằng”) nhiều hơn 34% so với khi cung cấp thông tin đúng. Lý do: AI đã học từ văn bản con người rằng “nghe tự tin = đáng tin cậy”. Nên khi không chắc, nó… tự tin hơn.
Điều này đảo ngược hoàn toàn trực giác thông thường của người dùng. Phần lớn chúng ta mong đợi sự tự tin tỉ lệ thuận với độ chính xác, nhưng với trí tuệ nhân tạo thì ngược lại hoàn toàn trong nhiều tình huống. Bạn nghĩ AI hedges khi không chắc. Thực tế là ngược lại. Khi Claude nói “Đây là API endpoint chính xác: /api/v2/users/{id}” với giọng chắc nịch. Đó có thể là dấu hiệu nó đang đoán mò nhiều hơn là biết thật.
Lập Trình Viên Gặp Những Dạng Hallucination Nào?
Mình dùng Claude Code hàng ngày và đã gặp đủ loại. Ba dạng phổ biến nhất với developer:
1. Phantom library (thư viện ma): Claude suggest npm install @anthropic-ai/claude-parser với code example hoàn chỉnh, type definitions đúng syntax, README-style documentation đi kèm. Package không tồn tại. Mình mất 40 phút debug trước khi nhận ra vấn đề nằm ở chỗ npm install báo lỗi 404. Đây là dạng nguy hiểm nhất vì AI tạo code chạy được về mặt syntax, nhưng fail lúc runtime.
2. Fake citation / URL 404: AI trích dẫn “theo nghiên cứu Stanford 2024 tại https://cs.stanford.edu/research/ai-benchmark-2024” nhưng URL trả về 404. Thậm chí tên paper, tên tác giả nghe rất thuyết phục. Trong mình TikTok “Claude Đang Bịa Thông Tin?” (1.449 views), mình test trực tiếp: Claude tự tin cite 3 paper AI không tồn tại với DOI hợp lệ về format nhưng resolve về trang lỗi.
3. Sai API syntax / method không tồn tại: Model cũ hơn knowledge cutoff bị hallucinate method mới, hoặc nhầm lẫn giữa các version API. Claude suggest anthropic.messages.stream() với callback pattern không có trong SDK thực tế. Code compile được, nhưng fail lúc gọi.
Điểm chung: cả 3 dạng đều nghe rất đúng, được trình bày chi tiết, và không có dấu hiệu nghi ngờ từ AI.
Nhìn lại, cả ba ví dụ có một mẫu chung: mình không chủ động kiểm tra vì thông tin trông hoàn hảo. Đó chính là lúc nguy hiểm nhất. Khi mọi thứ quá mượt mà, quá chi tiết, quá tự tin, đó là thời điểm nên dừng lại và xác minh.
Model Nào Hallucinate Nhiều Nhất?
Vectara (2026) công bố benchmark trên tập dữ liệu summarization và tập harder questions:
| Model | Summarization (đơn giản) | Harder benchmark |
|---|---|---|
| Gemini 3.1 Flash | 0.7% | >10% |
| GPT-4o | 1.5% | >10% |
| Claude Sonnet 4.6 | 4.4% | >10% |
| Legal citations (all models) | N/A | 58 to 88% |
Số liệu summarization trông ổn. Nhưng khi benchmark chuyển sang harder questions (câu hỏi cần reasoning, niche knowledge, hoặc thông tin sau training cutoff), tất cả model đều vượt 10%. Không có ngoại lệ. Kể cả GPT-4o hay Gemini với web search vẫn có hallucination khi context phức tạp.
Kết luận thực tế: chọn mô hình tốt hơn giúp ích nhưng không giải quyết vấn đề. Dù bạn đang dùng mô hình nào, quy trình xác minh vẫn là bắt buộc. Đặc biệt trong lĩnh vực pháp lý hay tài chính, tỉ lệ sai sót lên đến 88% với trích dẫn tài liệu cho thấy rủi ro thực sự.
Reasoning Model 2026 Hallucinate Khác Regular Model Như Thế Nào?
Đến năm 2026, reasoning model (Claude Sonnet 4.6 extended thinking, GPT-5.4 với reasoning effort, OpenAI o3/o4, Gemini 3.1 Pro thinking) đã thay đổi đáng kể profile hallucination. Khác với regular model fail âm thầm khi hết training knowledge, reasoning model có behavior đặc biệt mà dev cần hiểu để dùng đúng và detect sai sót sớm.
Reasoning model hallucinate ít hơn trên task có ground truth nhưng nhiều hơn trên task open-ended. Theo benchmark internal Anthropic Q1 2026, Claude Sonnet 4.6 thinking mode giảm hallucination khoảng 35-40% trên math problems và logical reasoning task so với regular mode. Tuy nhiên trên creative writing và open-ended exploration, thinking mode đôi khi “over-think” và confabulate elaborate fake details để justify chain of reasoning. Đây là pattern mới chỉ xuất hiện sau khi extended thinking ra mắt.
OpenAI o3 hallucination rate cao hơn GPT-4o trên một số test. OpenAI System Card cho o3 (12/2025) công bố o3 hallucinate trên PersonQA benchmark 33% so với 16% của GPT-4o, dù o3 mạnh hơn rõ rệt trên SWE-Bench và math task. Nguyên nhân: reasoning chain dài cho phép model fabricate context và self-confirm error trước khi output. Đây là “reasoning trap”: dev tin tưởng o3 hơn vì “thinking” output trông professional, nhưng thực tế risk hallucinate cao hơn cho factual lookup.
Cách phát hiện hallucination trong reasoning model. Khác với regular model fail im lặng, reasoning model leak signal qua thinking chain (Anthropic expose qua thinking parameter, OpenAI qua reasoning_summary). Đọc thinking output để check: (1) AI có self-correct giữa chừng không (good sign), (2) AI có quote source không hay just assert (red flag), (3) AI có express uncertainty trong reasoning không hay confident toàn bộ (red flag nếu task đòi recall). Pattern này emergent từ năm 2026 cùng với reasoning model boom, chưa có trong tài liệu Vietnamese phổ biến.
Verdict cho dev VN năm 2026: dùng reasoning model cho task structured có ground truth (math, code, formal reasoning), hallucination giảm rõ rệt. Dùng regular model cho task creative + open-ended, ít risk confabulation. Đặc biệt: KHÔNG tin reasoning model cho personal/historical facts lookup chỉ vì thinking chain trông convincing. PersonQA 33% là wake-up call. Vẫn cần Verify Loop và 5 dấu hiệu hallucinate trên đầu.
Một pattern thực dụng mình áp dụng tại ongboit.com: nếu task cần factual accuracy (research, fact-check, citation lookup), default sang regular mode + RAG grounding qua MCP filesystem tool, không bật thinking. Nếu task cần deep reasoning (architectural decision, complex debug), bật thinking nhưng đọc kỹ chain để spot self-deception trước khi commit output. Đây là balance giữa quality và safety cho production workflow.
5 Dấu Hiệu Nào Cho Thấy AI Đang Bịa?

Sau nhiều lần bị AI cung cấp thông tin sai mà không hay biết, mình đúc kết 5 dấu hiệu nhận biết thực tế. Những dấu hiệu này không yêu cầu bất kỳ tool hay extension nào, chỉ cần chú ý khi đọc kết quả:
1. Không có hedging words. Câu trả lời đúng thường có “thường thì”, “trong hầu hết trường hợp”, “tùy thuộc vào”. Khi AI trả lời tuyệt đối, không có điều kiện, đó là Confident Paradox đang hoạt động. Tăng mức nghi ngờ lên.
2. Source URL trả về 404 hoặc không liên quan. Bất kỳ citation nào từ AI, hãy click xem. Nếu URL 404 hoặc nội dung không khớp với điều AI claim: hallucination xác nhận.
3. Package / method không tìm thấy được. npm install [package] lỗi? Google không có kết quả cho method name đó? Đây là test nhanh nhất cho phantom library.
4. Số liệu không có nguồn cụ thể. AI nói “theo nghiên cứu năm 2025” mà không có tên tác giả, tên publication, hoặc link: đó thường là số liệu fabricated. Số liệu thật có nguồn truy ngược được.
5. AI không thừa nhận giới hạn. Thay vì “mình không chắc về phần này”, AI tiếp tục generate. Khi prompt ngược lại “bạn có chắc không?”, câu trả lời thay đổi hoàn toàn, chứng tỏ lần trước nó đang hallucinate.
Kỹ thuật cuối cùng này (Verify Loop) hiệu quả đáng ngạc nhiên: prompt AI confirm lại chính thông tin nó vừa đưa ra. Khoảng 30-40% trường hợp hallucination, AI tự nhận ra và sửa khi được hỏi lại.
Làm Sao Giảm Hallucination Khi Dùng Claude/ChatGPT?
Không thể loại bỏ, nhưng giảm thiểu rõ rệt được. Mình đúc kết thành năm bước thực hành dưới tên framework CRISP sau nhiều tháng mắc sai lầm và tìm cách khắc phục:
C: Context đầy đủ. Context window càng rõ ràng, hallucination càng ít. Cung cấp version library, ngày tháng, phạm vi project cụ thể cho mỗi prompt.
R: Reference cụ thể. Paste đoạn code, documentation, hoặc example thực tế vào prompt. AI generate dựa trên reference có sẵn sẽ ít bịa hơn generate từ memory.
I: Iterate + challenge. Đừng tin ngay kết quả đầu tiên. Hỏi lại: “Bạn có chắc không? Hãy kiểm tra lại.” Đặc biệt hiệu quả với số liệu và API documentation.
S: Source requirement. Yêu cầu AI cung cấp nguồn cụ thể cho mọi claim quan trọng. “Trích dẫn source với URL.” Nếu AI không cung cấp được, đó là tín hiệu không đáng tin.
I: Isolation per task. Đừng nhồi nhiều task vào một prompt dài. Token dồn vào context lịch sử hội thoại dài khiến model bị phân tâm và hallucination tăng. Tách task, /clear trước task mới.
P: Prioritize. Với các quyết định quan trọng (tài chính, pháp lý, y tế), luôn ưu tiên xác minh từ nguồn gốc, không dừng lại ở một lần kiểm tra.
Áp dụng CRISP nhất quán, mình giảm được tỉ lệ hallucination không phát hiện từ ~25% xuống dưới 5% trong workflow Claude Code hàng ngày. Bước quan trọng nhất là thay đổi thói quen: không tin mặc định, xác minh có chọn lọc những điểm quan trọng. Muốn đặt prompt hiệu quả hơn, xem thêm prompt engineering với Claude Code.
AI Hallucination Có Thể Tránh Hoàn Toàn Không?
Câu trả lời ngắn: không. Ngay cả các nhà nghiên cứu AI hàng đầu thế giới cũng xác nhận điều này. Hallucination không phải bug cần fix; nó là đặc điểm cố hữu của cách LLM học và predict.
RAG (Retrieval-Augmented Generation) giảm rõ rệt bằng cách cung cấp grounded context. Thay vì dựa vào memory, model tra cứu nguồn thực tế trước khi generate. Nhưng RAG không loại bỏ hoàn toàn: model vẫn có thể hiểu sai document truy xuất được, hoặc hallucinate khi câu hỏi nằm ngoài phạm vi corpus.
Mục tiêu thực tế không phải “zero hallucination” mà là “catch before production”. Confident Paradox dạy bạn một rule đơn giản: nghe tự tin = verify trước khi dùng. Đây là mindset khác với trust-by-default. Và nó tạo ra khác biệt lớn trong chất lượng output.
Câu Hỏi Thường Gặp
AI hallucination là gì?
AI hallucination là khi mô hình ngôn ngữ tạo ra thông tin không chính xác, không tồn tại, hoặc hoàn toàn bịa đặt, nhưng trình bày với giọng điệu tự tin như sự thật. Khác với lỗi thông thường, trí tuệ nhân tạo không nhận ra mình đang sai và không đưa ra bất kỳ cảnh báo nào cho người dùng. Đây là lý do vì sao hiện tượng này nguy hiểm hơn lỗi thông thường.
Tại sao AI tự tin khi bịa thông tin?
Vì LLM được train để tạo văn bản “nghe tự nhiên”, mà văn bản tự tin nghe tự nhiên hơn văn bản nghi ngờ. MIT (2025) đo được AI dùng ngôn ngữ khẳng định nhiều hơn 34% khi đang hallucinate. Đây là Confident Paradox: độ tự tin của AI không phản ánh độ chính xác.
Làm sao biết AI đang hallucinate?
5 dấu hiệu: (1) câu trả lời tuyệt đối không có điều kiện, (2) source URL 404, (3) package / method không tìm thấy được, (4) số liệu không có nguồn cụ thể, (5) AI thay đổi câu trả lời khi bị hỏi lại. Verify Loop (hỏi lại “bạn có chắc không?”) bắt được khoảng 30-40% trường hợp.
Model AI nào ít hallucinate nhất?
Trên bài test summarization đơn giản: Gemini 3.1 Flash (0.7%), GPT-4o (1.5%), Claude Sonnet (4.4%). Tuy nhiên, khi chuyển sang harder benchmarks, tất cả model đều vượt 10%. Không có model nào “an toàn”, chỉ có mức độ rủi ro khác nhau.
AI hallucination có thể tránh hoàn toàn không?
Không. Hallucination là đặc điểm cố hữu của cơ chế next-token prediction, không phải lỗi có thể vá. RAG giảm rõ rệt nhưng không loại bỏ hoàn toàn. Mục tiêu thực tế là quản lý và bắt kịp trước khi dùng output, không phải tin tưởng tuyệt đối.
Kết Luận
AI hallucination không biến mất. Với mọi model (Claude, GPT-4o, Gemini), rủi ro luôn hiện diện, đặc biệt với câu hỏi phức tạp, niche knowledge, hoặc thông tin mới sau training cutoff.
Điều thay đổi game là hiểu Confident Paradox: AI nghe tự tin nhất khi đang sai nhất. Áp dụng framework CRISP, bật Verify Loop thành thói quen, và kiểm tra 5 dấu hiệu mỗi khi dùng output quan trọng.
Thói quen xác minh không cần tốn nhiều thời gian. Sau khi nhận được kết quả, chỉ cần dừng lại vài giây để đặt câu hỏi: thông tin này có nguồn không? Mình có thể tự kiểm tra được không? Nếu câu trả lời là không, đó là lúc cần xác minh thêm trước khi sử dụng. Dần dần, thói quen này trở nên tự nhiên như kiểm tra lỗi sau khi viết mã. Không phải vì không tin tưởng công cụ, mà vì hiểu rõ giới hạn của nó và làm chủ được rủi ro trong quá trình làm việc.
Muốn hiểu sâu hơn về cơ chế hoạt động của AI? Xem bài token là gì để hiểu tại sao prediction bằng xác suất dẫn đến hallucination, và context window là gì để biết cách cung cấp đủ grounding cho model giảm thiểu rủi ro.
Kiến thức nền này sẽ giúp bạn học Claude Code hiệu quả hơn. Xem lộ trình 8 levels để biết bước tiếp theo.