Machine Learning Là Gì? Giải Thích + 4 Loại Chính
Bạn dùng ChatGPT hay Claude hàng ngày thì bạn đã dùng Machine Learning rồi, có điều có thể không biết. ML là công nghệ nền tảng đứng sau mọi hệ thống AI hiện đại: từ gợi ý video Netflix, nhận diện khuôn mặt Facebook, đến reasoning của Claude Sonnet 4.6.
Bài này giải thích Machine Learning là gì theo cách đơn giản nhất, nhưng không bỏ qua chi tiết quan trọng. Mình cover 4 loại ML chính, phân biệt ML với AI, Deep Learning, và LLM (câu hỏi #1 của developer 2026), cộng với lộ trình thực tế nếu bạn muốn học ML từ zero để dùng trong công việc, không phải để làm nhà nghiên cứu.
TL;DR
- Machine Learning (ML) là nhánh của AI, cho phép máy tính tự học từ dữ liệu để dự đoán hoặc ra quyết định mà không cần lập trình rule cứng cho từng trường hợp.
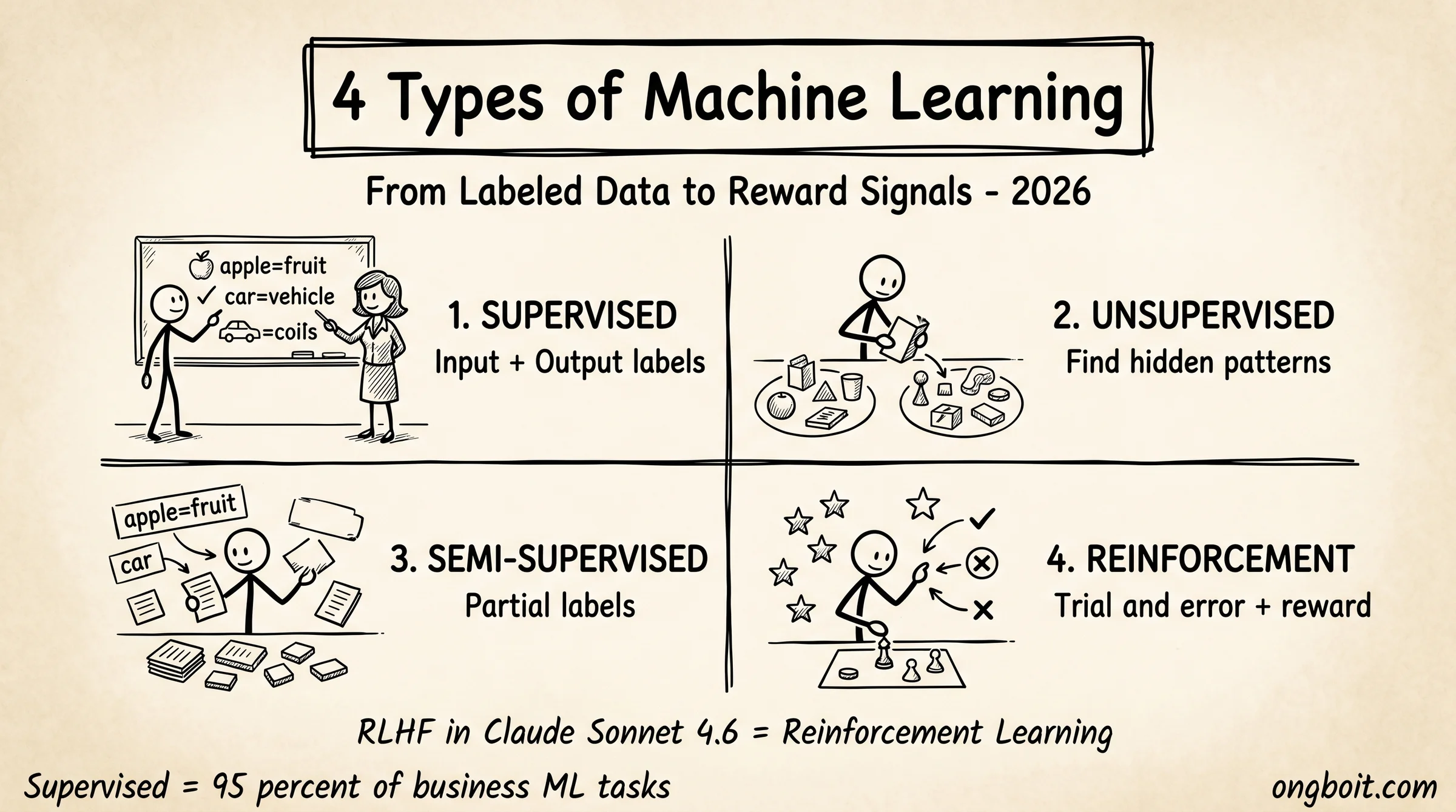
- 4 loại ML chính: Supervised (có giám sát), Unsupervised (không giám sát), Semi-supervised (bán giám sát), và Reinforcement Learning (học tăng cường).
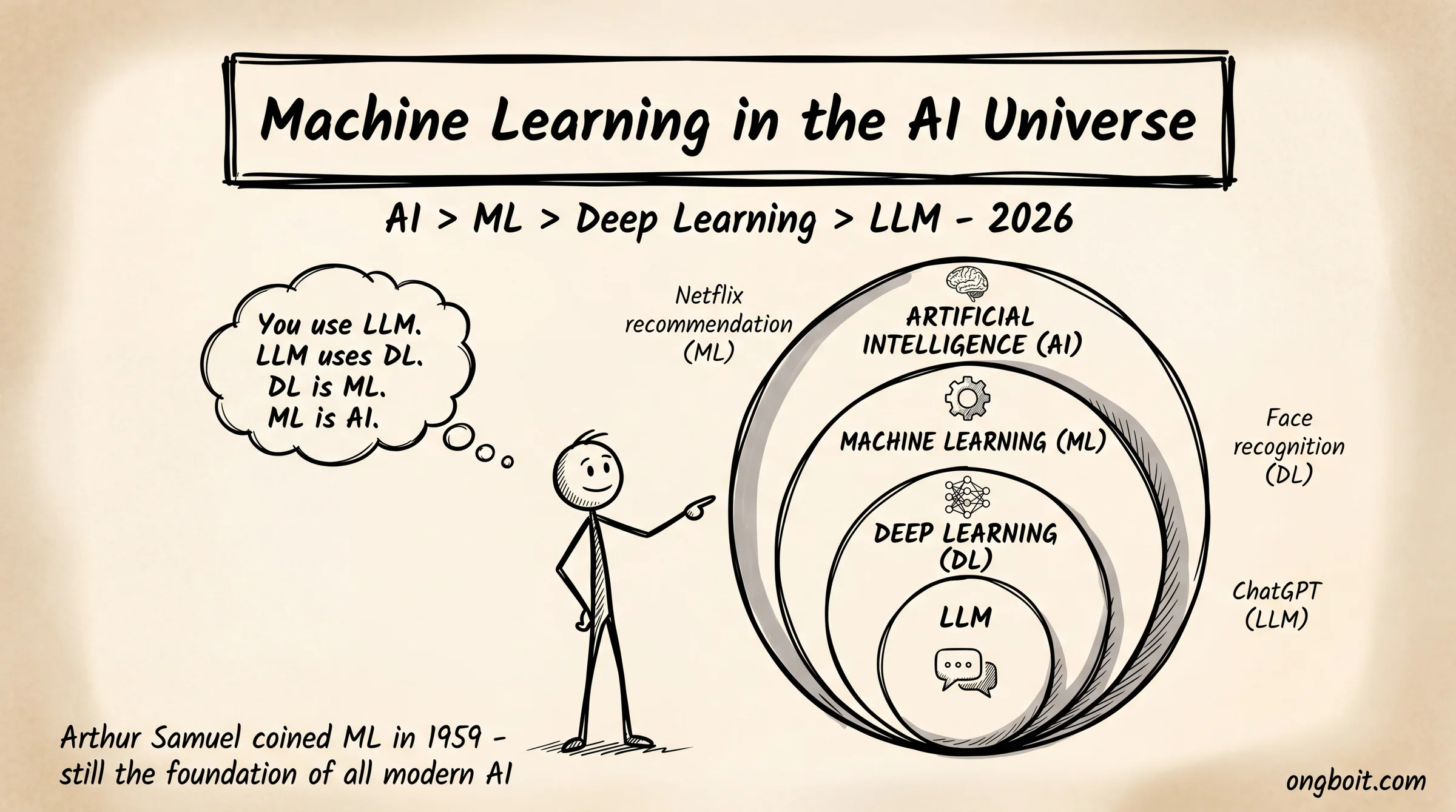
- ML vs AI vs DL vs LLM: AI là tổng thể, ML là một nhánh của AI, Deep Learning là một nhánh của ML, LLM là ứng dụng của Deep Learning cho ngôn ngữ. Pyramid từ rộng đến hẹp.
- Ứng dụng 2026: Recommendation, fraud detection, xe tự lái, LLM (Claude/GPT/Gemini), classical ML vẫn chạy song song với LLM trong production.
- Developer học gì: Python + numpy/pandas, scikit-learn cho classical ML, PyTorch cho deep learning. Không cần PhD toán để bắt đầu.
Machine Learning Là Gì?
Machine Learning (máy học, học máy) là một nhánh của trí tuệ nhân tạo (AI) cho phép máy tính tự học từ dữ liệu để cải thiện hiệu suất trên một task cụ thể, mà không cần lập trình rule cứng cho từng trường hợp. Thay vì developer viết câu lệnh “nếu khách hàng tuổi X và thu nhập Y thì duyệt vay”, ML học từ hàng triệu hồ sơ vay cũ và tự tìm ra pattern nào dự đoán khả năng trả nợ tốt nhất.
Thuật ngữ “Machine Learning” được Arthur Samuel, kỹ sư IBM, đặt năm 1959 khi ông phát triển chương trình chơi cờ đam có khả năng tự cải thiện qua mỗi ván chơi. Định nghĩa kinh điển của Samuel: ML là “field of study that gives computers the ability to learn without being explicitly programmed”. Định nghĩa này đúng đến hôm nay, dù công nghệ đã thay đổi rất nhiều.
Điểm cốt lõi phân biệt ML với lập trình truyền thống: developer không viết logic, developer chuẩn bị dữ liệu. Trong code thông thường bạn viết if condition then action. Trong ML bạn đưa cho máy 10,000 ví dụ (input, output) và máy tự học ra hàm dự đoán output từ input. Khi có input mới chưa từng thấy, ML áp dụng hàm học được để đoán.
ML không phải AI hoàn chỉnh, không phải robot thông minh, không phải con người máy tính. ML là kỹ thuật thống kê nâng cao kết hợp với sức mạnh tính toán hiện đại. Điểm làm ML ấn tượng là quy mô: model có thể học pattern từ hàng tỷ data point mà con người không bao giờ nhận ra được.
Machine Learning Hoạt Động Như Thế Nào?
ML hoạt động qua 4 bước cơ bản: thu thập dữ liệu, chọn thuật toán, training model, và inference (đưa ra dự đoán). Mỗi bước có chi phí và thách thức riêng, và chất lượng kết quả phụ thuộc nhiều vào chất lượng dữ liệu hơn là chọn thuật toán phức tạp.
Bước 1: Thu thập và chuẩn bị dữ liệu. Đây là bước tốn thời gian nhất, thường chiếm 70-80% công sức của data scientist. Dữ liệu phải được làm sạch (xử lý giá trị thiếu, loại bỏ outlier), chuẩn hóa (đưa về cùng thang đo), và chia thành tập training, validation, test. Câu ngạn ngữ trong giới ML: “garbage in, garbage out”, dữ liệu kém thì model dù tốt đến đâu cũng vô dụng.
Bước 2: Chọn thuật toán. Tùy bài toán mà chọn khác nhau. Phân loại email spam dùng logistic regression hoặc random forest. Dự đoán giá nhà dùng linear regression. Phân cụm khách hàng dùng k-means. Nhận diện khuôn mặt dùng neural network sâu. Scikit-learn cung cấp ~30 thuật toán classical ML sẵn có, developer chỉ cần gọi đúng hàm.
Bước 3: Training (huấn luyện). Model được feed data training và tự điều chỉnh các tham số nội bộ để giảm sai số. Quá trình này lặp nhiều lần (gọi là epoch), mỗi lần model giỏi hơn một chút. Classical ML train được trong vài phút trên CPU. Deep learning cần GPU và có thể chạy nhiều giờ hoặc ngày.
Bước 4: Inference. Sau khi train xong, model được deploy để dự đoán trên data mới. Đây là lý do AI thỉnh thoảng hallucinate: model không biết sự thật, nó chỉ biết pattern xác suất. Khi gặp input khác xa training data, dự đoán có thể sai mà model vẫn tự tin.
Có Bao Nhiêu Loại Machine Learning?
Machine Learning chia thành 4 loại chính dựa trên cách model học từ dữ liệu: Supervised (có giám sát), Unsupervised (không giám sát), Semi-supervised (bán giám sát), và Reinforcement Learning (học tăng cường). Mỗi loại phù hợp với một nhóm bài toán cụ thể.
| Loại | Dữ liệu input | Ví dụ bài toán | Thuật toán phổ biến |
|---|---|---|---|
| Supervised Learning | Có nhãn (input + output) | Phân loại email spam, dự đoán giá nhà, nhận diện ảnh | Linear/Logistic Regression, Random Forest, SVM |
| Unsupervised Learning | Không nhãn (chỉ input) | Phân cụm khách hàng, anomaly detection, dimensionality reduction | K-means, DBSCAN, PCA, Autoencoders |
| Semi-supervised | Một phần có nhãn | Phân loại ảnh y tế (ít ảnh có nhãn chuyên gia) | Self-training, Co-training, GANs |
| Reinforcement Learning | Không có nhãn, có phần thưởng/phạt | Game AI (AlphaGo), xe tự lái, RLHF cho LLM | Q-Learning, DQN, PPO, Actor-Critic |
Supervised Learning là phổ biến nhất trong production. Bạn đưa cho model 10,000 email gắn nhãn “spam” hoặc “không spam”, model học cách phân loại. 95% bài toán ML trong doanh nghiệp (credit scoring, churn prediction, demand forecasting) là supervised.
Unsupervised Learning tìm pattern ẩn không cần nhãn. Spotify phân cụm người dùng theo sở thích nghe nhạc để gợi ý playlist. Ngân hàng phát hiện giao dịch bất thường (anomaly detection) không cần ai gắn nhãn “giao dịch gian lận” trước.
Reinforcement Learning là loại thú vị nhất năm 2026 vì nó chính là kỹ thuật đứng sau RLHF (Reinforcement Learning from Human Feedback), giúp Claude Sonnet 4.6 và GPT-5.4 biết cách trả lời theo ý con người. Model tạo response, human đánh giá tốt hay kém, model học để tạo nhiều response được đánh giá tốt hơn.
Machine Learning Khác AI và Deep Learning Thế Nào?
AI là khái niệm rộng nhất, Machine Learning là một nhánh của AI, Deep Learning là một nhánh của ML. Pyramid từ rộng đến hẹp: AI bao gồm ML và các phương pháp khác (như hệ chuyên gia rule-based), ML bao gồm DL và classical ML, DL chuyên dùng neural networks nhiều lớp.
AI (Artificial Intelligence) là mục tiêu tổng thể: làm cho máy tính có khả năng “thông minh” như con người. AI có thể được build bằng nhiều cách: rule-based (hệ chuyên gia cổ điển), symbolic AI (reasoning logic), hoặc learning-based (ML/DL). Chatbot Eliza năm 1966 là AI rule-based, không có ML.
ML (Machine Learning) là cách tiếp cận AI thông qua học từ dữ liệu. Tất cả model bạn nghe đến ngày nay (GPT, Claude, Gemini, random forest, XGBoost) đều là ML. Classical ML như logistic regression, SVM, random forest vẫn chạy rất tốt cho dữ liệu dạng bảng (tabular) và thường nhanh + rẻ hơn deep learning.
Deep Learning (DL) là nhánh ML dùng neural networks nhiều lớp (deep = sâu, nhiều lớp ẩn). DL mạnh với dữ liệu phi cấu trúc: hình ảnh, âm thanh, văn bản. Khi data đủ lớn (>100K mẫu) và đủ compute (GPU), DL thường vượt classical ML. Nhưng với data nhỏ, classical ML vẫn thắng vì ít overfitting hơn.
Ví dụ cụ thể: Netflix gợi ý phim dùng classical ML (collaborative filtering, matrix factorization). Tesla xe tự lái dùng DL (convolutional neural networks cho nhận diện ảnh). Credit scoring dùng XGBoost (classical ML). Google Translate dùng DL (transformer networks).
Machine Learning Khác LLM Thế Nào?
LLM (Large Language Model) là một loại ứng dụng cụ thể của Deep Learning, chuyên để xử lý ngôn ngữ tự nhiên. Nói cách khác: LLM là ML, nhưng ML không chỉ là LLM. Đây là câu hỏi developer 2026 nhầm lẫn nhiều nhất vì LLM quá phổ biến qua ChatGPT, làm nhiều người tưởng ML = LLM.
Hierarchy chính xác: AI ⊃ ML ⊃ Deep Learning ⊃ LLM. LLM là một dạng cụ thể của Deep Learning (dùng kiến trúc Transformer) được train chuyên biệt cho ngôn ngữ tự nhiên. GPT-5.4, Claude Opus 4.7, Gemini 3.1 Pro đều là LLM. Nhưng model nhận diện khối u trong ảnh X-quang cũng là Deep Learning, không phải LLM. Và model dự đoán tỷ lệ chuyển đổi khách hàng là classical ML (XGBoost), không phải Deep Learning cũng không phải LLM.
Tại sao phân biệt quan trọng? Vì nhiều bài toán production không cần LLM. Credit scoring, churn prediction, fraud detection, demand forecasting, recommendation vẫn dùng classical ML tốt hơn + rẻ hơn 100 lần. Nếu bạn lôi GPT-5.4 ra dùng cho bài toán phân loại email 10 triệu email/tháng, chi phí $15/1M output token sẽ phá ngân sách. XGBoost chạy free trên laptop làm cùng việc với accuracy tương đương.
Quan hệ giữa ML và LLM: LLM vẫn cần ML classical để hoạt động tốt trong production. Embeddings (biến text thành vector) là ML. Vector search trong RAG là ML. Fine-tuning LLM trên data domain-specific là ML. LLM không thay thế ML, LLM là một tầng cao hơn cộng thêm.
Ứng Dụng Machine Learning Trong Thực Tế
Machine Learning đã tích hợp vào gần như mọi sản phẩm công nghệ bạn dùng hàng ngày, từ chat AI đến ngân hàng, y tế, và logistics. Dưới đây là những ứng dụng phổ biến nhất, cộng với việc chúng dùng loại ML nào.
Recommendation systems. Netflix, YouTube, Spotify, TikTok, Shopee đều dùng ML để gợi ý nội dung. Thuật toán chính là collaborative filtering (unsupervised) kết hợp content-based filtering (supervised). TikTok algorithm nổi tiếng vì ML của nó học từ mili-giây mỗi lần bạn vuốt video, tạo feed siêu cá nhân hóa.
Fraud detection và anomaly detection. Ngân hàng Việt Nam (Vietcombank, Techcombank, MB Bank) dùng ML phát hiện giao dịch bất thường realtime. Model học pattern giao dịch bình thường của khách hàng, flag giao dịch lệch pattern để kiểm tra. Đây là unsupervised learning (anomaly detection) hoặc supervised (phân loại legitimate/fraud).
Xe tự lái. Tesla, Waymo, VinFast dùng Deep Learning để nhận diện làn đường, xe, người đi bộ, biển báo từ camera. Kết hợp Reinforcement Learning để điều khiển (tăng/giảm ga, đánh lái). Xe tự lái là một trong những ứng dụng ML phức tạp nhất vì đòi hỏi realtime + độ chính xác cực cao.
LLM và AI Agent. ChatGPT, Claude, Gemini, Grok đều là LLM (Deep Learning). AI Agent như Claude Code dùng LLM làm “brain” cộng thêm tools và memory. RLHF (Reinforcement Learning from Human Feedback) là kỹ thuật ML biến LLM base thành trợ lý hữu ích.
Healthcare. ML phân tích ảnh X-quang, MRI để phát hiện khối u (Deep Learning). Dự đoán nguy cơ bệnh từ hồ sơ y tế (classical ML). Tại Việt Nam, Vinmec và Medlatec đã triển khai AI chẩn đoán hình ảnh trong production.
Pricing và forecasting. Uber/Grab tính giá động dùng ML dựa trên cung cầu thời gian thực. Shopee dự đoán nhu cầu để tối ưu kho. Đây là classical ML (gradient boosting, time series models), không cần LLM.
Machine Learning Cho Developer Cần Học Gì?
Developer muốn làm ML trong 2026 không cần PhD toán, chỉ cần Python căn bản + 3 thư viện chính (numpy, pandas, scikit-learn) cho classical ML, thêm PyTorch nếu làm deep learning. Lộ trình thực tế 3-6 tháng là đủ để build model production.
Tháng 1-2: Foundation. Python vững (list, dict, function, class), numpy (array operations), pandas (DataFrame, cleaning data). Khóa học miễn phí: Kaggle Learn, Google ML Crash Course. Làm 3-5 project nhỏ: phân tích data CSV, visualize với matplotlib.
Tháng 3-4: Classical ML. Scikit-learn là thư viện duy nhất bạn cần cho bước này. Học 5 thuật toán quan trọng: Linear Regression, Logistic Regression, Random Forest, XGBoost, K-means. Làm Kaggle competition beginner (Titanic, House Prices). Hiểu cross-validation, train/test split, overfitting.
Tháng 5-6: Deep Learning (optional). Nếu muốn làm DL, học PyTorch hoặc TensorFlow. Build một CNN nhận diện ảnh, một RNN/Transformer xử lý text. Thực tế 90% dự án ML không cần DL, nên nếu bạn chỉ muốn apply ML vào công việc backend/data thì có thể skip bước này.
Kinh nghiệm cá nhân khi học ML: Mình bắt đầu học ML năm 2020 và đã mất 2 tháng loanh quanh PyTorch vì tưởng Deep Learning là “thứ xịn” để bắt đầu. Kết quả: toàn bộ bài toán thực tế mình gặp (phân loại bài viết, clustering keyword, fraud detection) đều chạy bằng scikit-learn tốt hơn + nhanh hơn. Lời khuyên: học classical ML trước, đến khi gặp bài toán bắt buộc cần Deep Learning (ảnh, âm thanh, ngôn ngữ phức tạp) mới học PyTorch. Thứ tự ngược lại tốn ít nhất 1-2 tháng không cần thiết.
Kỹ năng bonus quan trọng: Hiểu token và embeddings (nền tảng của LLM + vector search). Dùng Claude Code để học code ML (Claude Sonnet 4.6 rất giỏi giải thích thuật toán ML từng dòng). Đọc paper gốc của thuật toán bạn dùng (XGBoost paper ngắn và đọc được cho developer).
Sai lầm phổ biến cần tránh: không học math trước code (học ngược: code trước, math khi cần hiểu sâu). Không cố build LLM from scratch (dùng API Claude/GPT đã đủ cho 99% use case). Không tập trung quá vào accuracy cuối cùng mà bỏ qua data quality (data tốt quyết định 80% kết quả).
Machine Learning Kết Nối Với Hệ Sinh Thái AI Hiện Đại Năm 2026 Ra Sao?
Phần này giúp người đọc hiểu rõ vị trí của học máy trong toàn bộ hệ sinh thái trí tuệ nhân tạo năm 2026. Hiểu được mối liên kết giữa các khái niệm giúp lập trình viên chọn đúng công nghệ cho từng tình huống cụ thể, tránh việc lạm dụng kỹ thuật phức tạp khi không cần thiết.
Machine Learning là khái niệm cha của LLM. Mọi LLM hiện nay đều là một dạng ML cụ thể, sử dụng kiến trúc Transformer và phương pháp deep learning với hàng tỷ tham số. Hiểu được mối quan hệ này giúp lập trình viên tránh nhầm lẫn giữa các khái niệm, đặc biệt khi tham gia thảo luận chuyên môn với đồng nghiệp có nền tảng AI truyền thống. Pattern khôn ngoan là tiếp cận từ khái niệm cha ML trước, sau đó đi sâu vào các nhánh cụ thể như LLM hoặc Computer Vision tùy theo nhu cầu công việc.
Đối với pipeline NLP hiện đại, ML được áp dụng qua cơ chế tokenization để biến văn bản thành dạng số mà model có thể xử lý. Đây là bước quan trọng quyết định chất lượng output của language model. ML cũng quyết định kích thước context window mà model có thể xử lý trong một lần gọi, tùy thuộc vào kiến trúc và phương pháp training cụ thể của từng model.
Đối với các ứng dụng automation quy trình kinh doanh, ML thường được kết hợp với pattern AI Agent. AI Agent thế hệ mới sử dụng LLM được trang bị thêm các tool và self-reasoning loop để tự động hoàn thành các tác vụ phức tạp. Kỹ thuật như Chain-of-Thought và System Prompt giúp AI Agent đưa ra response chính xác và phù hợp với business context cụ thể.
Học Máy Cho Đội Nhóm Việt Nam Năm 2026 Cần Lưu Ý Gì Quan Trọng?
Phần này tổng hợp ba lưu ý quan trọng khi tiếp cận học máy cho đội nhóm phát triển sản phẩm tại Việt Nam năm 2026. Mỗi lưu ý đều rút ra từ kinh nghiệm thực chiến của các đội nhóm đã triển khai thành công trong sáu tháng đầu năm 2026.
Lưu ý đầu tiên là về việc cân nhắc giữa tự xây dựng ML model và sử dụng API có sẵn. Đối với phần lớn đội nhóm phát triển sản phẩm vừa và nhỏ, sử dụng các API có sẵn từ các nhà cung cấp lớn là lựa chọn khôn ngoan hơn nhiều so với tự training model từ đầu. Chi phí training ML model lớn có thể lên đến hàng trăm nghìn đô la, trong khi API tốt chỉ tốn vài chục đến vài trăm đô la mỗi tháng cho workload tương đương. Pattern khôn ngoan là chỉ tự xây dựng model khi có yêu cầu đặc thù về data security hoặc cần độ chính xác cực kỳ cao cho lĩnh vực chuyên môn cụ thể của doanh nghiệp.
Lưu ý thứ hai là về tầm quan trọng của data quality trong mọi dự án ML. Data kém chất lượng cho ra model kém chất lượng, không quan trọng kiến trúc model tinh vi đến đâu. Đối với doanh nghiệp Việt Nam đang xây dựng sản phẩm AI cho thị trường nội địa, đầu tư vào việc thu thập và làm sạch data tiếng Việt chất lượng cao là yếu tố quyết định thành công. Pattern khôn ngoan là dành ít nhất 70% thời gian dự án cho việc chuẩn bị data, chỉ 30% cho việc training và fine-tuning model. Cách phân bổ này ngược với suy nghĩ thông thường của người mới, nhưng phản ánh đúng thực tế của ngành ML hiện đại.
Lưu ý cuối cùng là về việc đào tạo đội ngũ hiểu rõ giới hạn của ML hiện tại. ML không phải là phép màu giải quyết mọi bài toán, có nhiều tình huống cần thuật toán truyền thống đơn giản hơn cho kết quả tốt hơn nhiều. Đặc biệt là các tình huống yêu cầu logic chắc chắn không có chỗ cho sai sót như tính toán tài chính hoặc kiểm tra tuân thủ pháp luật. Pattern khôn ngoan là kết hợp ML cho các phần cần khả năng học từ data, với thuật toán truyền thống cho các phần cần độ chắc chắn tuyệt đối. Cách kết hợp này tạo ra sản phẩm chất lượng cao hơn nhiều so với việc cố gắng áp dụng ML cho mọi thành phần của hệ thống.
Câu Hỏi Thường Gặp
Machine Learning khác gì với lập trình truyền thống?
Lập trình truyền thống là developer viết logic trực tiếp, Machine Learning là máy tính tự học logic từ dữ liệu. Trong code bình thường bạn viết “if age > 60 then discount 20%”, trong ML bạn đưa 100,000 giao dịch cũ và máy tự tìm ra rule tối ưu. ML phù hợp khi logic quá phức tạp để viết tay (nhận diện ảnh) hoặc khi logic thay đổi theo thời gian (giá nhà).
ML có thay thế lập trình viên không?
Không thay thế, nhưng thay đổi skill set. Developer 2026 dùng Claude Code viết code nhanh hơn 3-5 lần, nhưng vẫn cần hiểu logic, debug, review code. ML Engineer và Data Scientist là hai vai trò mới xuất hiện nhờ ML, không phải thay thế Frontend/Backend developer. Theo Stack Overflow 2025, tỷ lệ developer sử dụng hoặc đang lên kế hoạch dùng AI tools trong workflow đã tăng từ 44% (2023) lên 84% (2025), chứng tỏ AI là công cụ chứ không phải người thay thế.
Cần học toán gì để làm ML?
Đại số tuyến tính cơ bản (vector, matrix), xác suất thống kê cơ bản, và một chút giải tích là đủ cho 90% bài toán. Bạn không cần hiểu chứng minh định lý để dùng scikit-learn. Hiểu trung bình, phương sai, Bayes’ theorem là đủ. Nếu muốn đi sâu vào Deep Learning, học thêm gradient descent và backpropagation. Các khóa học miễn phí như Andrew Ng Machine Learning Specialization hoặc fast.ai teach toán khi cần, không buộc học trước.
Classical ML và Deep Learning, cái nào mạnh hơn?
Tùy bài toán và dữ liệu. Với data dạng bảng (tabular) và dưới 100K mẫu, classical ML như XGBoost thường thắng Deep Learning về accuracy + tốc độ + dễ debug. Với ảnh, âm thanh, văn bản và data lớn (>1M mẫu), Deep Learning vượt trội rõ rệt. Kaggle competition cho data tabular vẫn do XGBoost/LightGBM thống trị, Deep Learning chỉ thắng ở image/text.
Machine Learning có nguy hiểm không?
Rủi ro chính là bias (thiên lệch) và hallucinate của LLM. Model học từ data, nếu data có bias (ví dụ chỉ có ảnh đàn ông da trắng), model sẽ bias theo. Amazon từng scrap hệ thống tuyển dụng AI vì nó bias chống nữ. Developer cần hiểu trách nhiệm đạo đức: test model trên đa dạng dữ liệu, document giới hạn, không deploy ML cho quyết định quan trọng mà không có con người review.
Kết Luận
Machine Learning là nền tảng của mọi AI hiện đại, không phải công nghệ futuristic mà là kỹ thuật đã ứng dụng production rộng rãi từ 2015. Nếu bạn dùng ChatGPT, Netflix, Google Maps, hay app ngân hàng hàng ngày, bạn đã là user của ML.
Với developer năm 2026, ML không còn là lựa chọn “có thể học” mà là skill cơ bản như Git hay Docker. Classical ML (scikit-learn + XGBoost) vẫn giải quyết 80% bài toán production rẻ hơn và nhanh hơn LLM. Deep Learning và LLM là tầng cao hơn, thêm khả năng xử lý ngôn ngữ và ảnh, không thay thế classical ML. Lộ trình 3-6 tháng với Python + scikit-learn là đủ để build model production thực sự. Đọc tiếp LLM là gì để hiểu tầng trên cùng của pyramid AI/ML, và AI Agent là gì để biết cách ghép ML vào workflow tự động hóa production.