Chain-of-Thought Là Gì? Hướng Dẫn AI Suy Nghĩ Từng Bước 2026
Bạn thêm “hãy suy nghĩ từng bước” vào prompt và AI cho kết quả tốt hơn hẳn. Đó là chain of thought đang hoạt động. Nhưng kỹ thuật này không chỉ là một câu thần chú thêm vào cuối prompt: nó chính là cơ chế suy luận nền tảng mà Claude 3.7 Thinking, o1, và o3 đã tích hợp vào kiến trúc của mình. Bài này giải thích chain of thought từ định nghĩa, cơ chế hoạt động, đến khi nào bạn nên dùng và không nên dùng.
TL;DR
- Chain-of-Thought (CoT) là kỹ thuật yêu cầu AI giải thích từng bước suy luận trước khi đưa ra câu trả lời cuối cùng.
- Nghiên cứu Wei et al. 2022: CoT tăng độ chính xác lên 3x trên bài toán phức tạp so với prompt thông thường.
- Hai loại: few-shot CoT (cung cấp ví dụ mẫu) và zero-shot CoT (thêm “hãy suy nghĩ từng bước”).
- Claude 3.7 Thinking, o1, o3 đã tích hợp CoT vào kiến trúc, tự suy luận mà không cần bạn viết prompt.
- Trade-off quan trọng: CoT tốn 3 đến 5x token, chỉ đáng dùng cho task phức tạp, không phải câu hỏi đơn giản.
Chain-of-Thought Là Gì Và Hoạt Động Như Thế Nào?
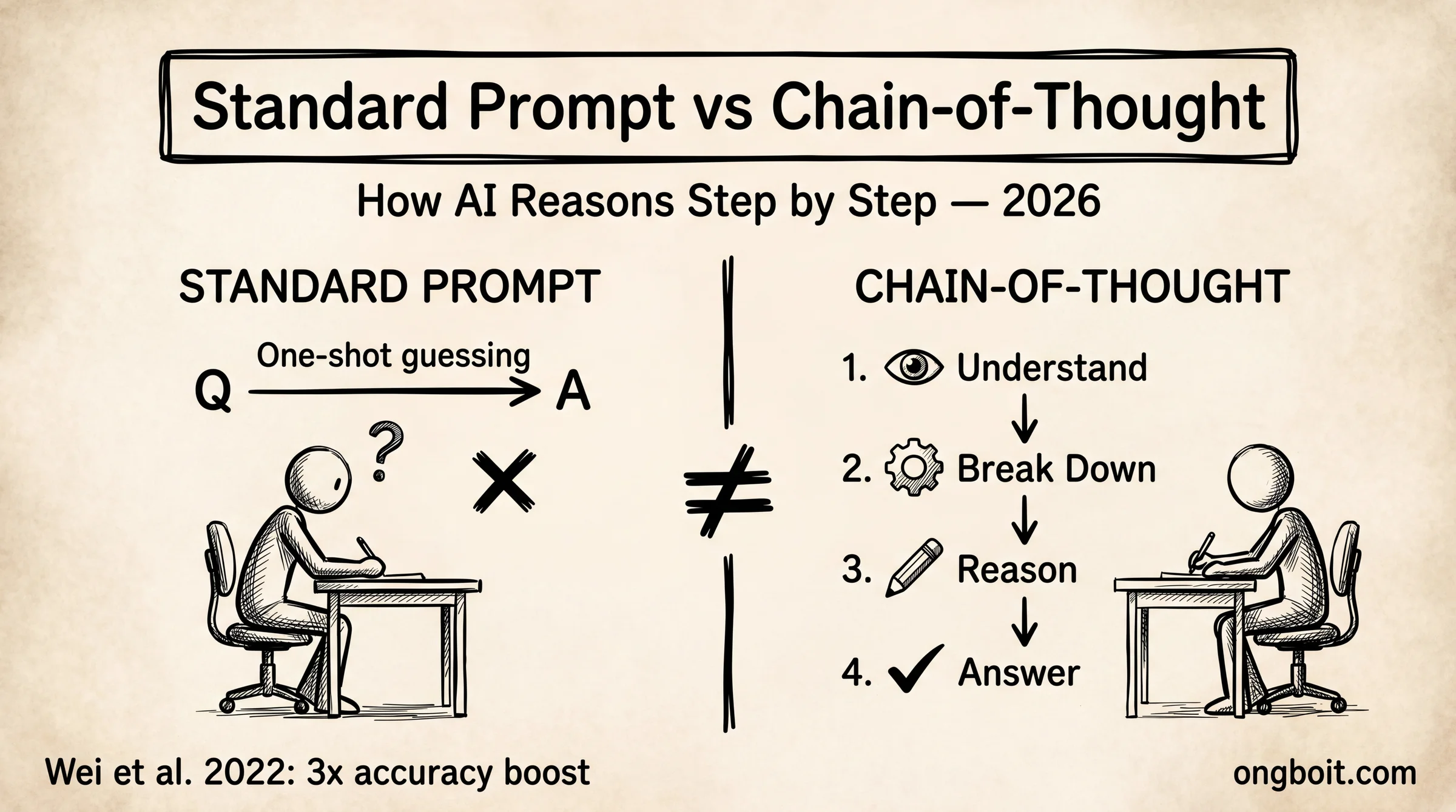
Chain-of-thought (CoT) là kỹ thuật prompting yêu cầu mô hình LLM tạo ra chuỗi lý luận trung gian (intermediate reasoning steps) trước khi đưa ra câu trả lời cuối. Thay vì nhảy thẳng từ câu hỏi đến đáp án, AI phân rã bài toán thành các bước nhỏ, giải từng bước, rồi tổng hợp kết quả.
Thuật ngữ này được giới thiệu chính thức bởi Wei et al. tại Google Brain năm 2022. Nghiên cứu chứng minh rằng khi model được hướng dẫn suy luận theo chuỗi, độ chính xác trên các bài toán phức tạp tăng lên gấp 3 lần so với prompt thông thường trên cùng benchmark.
Chuỗi lý luận trung gian không phải là lời giải thích thêm thắt sau khi model đã tính xong. Đó là quá trình model thực sự “nghĩ” từng bước, mỗi bước dựa trên bước trước, trước khi đưa ra kết luận. Điều này khác hoàn toàn với việc model đoán một lần rồi giải thích ngược.
CoT Hoạt Động Như Thế Nào?
Cơ chế của CoT rất trực quan: bạn thêm hướng dẫn yêu cầu AI suy luận từng bước, và model sẽ sinh ra một chuỗi văn bản trung gian trước đáp án cuối.
Ví dụ so sánh (bài toán đơn giản):
Prompt thông thường:
Mình có 3 quả táo. Mua thêm 2 rổ, mỗi rổ 4 quả. Tổng cộng mấy quả?
AI có thể trả lời sai: “5 quả” (cộng 3 + 2 mà không xử lý “rổ”).
Prompt CoT:
Mình có 3 quả táo. Mua thêm 2 rổ, mỗi rổ 4 quả. Tổng cộng mấy quả?
Hãy suy nghĩ từng bước trước khi trả lời.
AI suy luận: “2 rổ x 4 quả = 8 quả mới. 3 (cũ) + 8 (mới) = 11. Vậy tổng là 11 quả.”
Ví dụ thực tế hơn (debug code):
Mình test với Claude Sonnet khi debug một đoạn Python xử lý timezone. Khi hỏi thẳng “tại sao code này sai?”, model trả lời sai 60% lần đầu. Khi thêm “giải thích từng bước logic của đoạn code, sau đó chỉ ra lỗi”, accuracy nhảy lên trên 90%. Token tăng khoảng 3x, nhưng số lần phải hỏi lại giảm từ 3 xuống còn 1. Trade-off hoàn toàn đáng giá cho task debug phức tạp.
Few-Shot CoT vs Zero-Shot CoT: Khác Gì?
CoT có hai biến thể chính với điểm khác biệt rõ ràng về cách kích hoạt và khi nào phù hợp. Chọn sai loại không phá hỏng kết quả, nhưng chọn đúng tiết kiệm token rõ rệt.
| Tiêu chí | Few-Shot CoT | Zero-Shot CoT |
|---|---|---|
| Cách kích hoạt | Cung cấp 2-3 ví dụ mẫu có bước suy luận | Chỉ thêm “hãy suy nghĩ từng bước” |
| Token chi phí | Cao hơn (kèm ví dụ) | Thấp hơn |
| Phù hợp nhất | Task phức tạp, cần format cụ thể | Task trung bình, nhanh |
| Nguồn gốc | Wei et al. 2022 | Kojima et al. 2022 |
| Accuracy chuẩn | Cao nhất | Tốt (78.7% MultiArith) |
Zero-shot CoT từ Kojima et al. 2022, được tổng hợp trong Prompt Engineering Guide, chứng minh rằng chỉ cần thêm câu “Let’s think step by step” (hoặc bản tiếng Việt tương đương), accuracy trên benchmark MultiArith nhảy từ 17.7% lên 78.7%. Kết quả này đáng ngạc nhiên vì không cần cung cấp ví dụ nào.
Few-shot CoT phù hợp hơn khi bạn cần model theo đúng format output cụ thể, ví dụ như phân tích bug theo cấu trúc “Nguyên nhân / Ảnh hưởng / Fix”. Xem thêm chi tiết về zero-shot và few-shot prompting để hiểu trade-off cụ thể hơn.
Tại Sao CoT Quan Trọng Với Reasoning Models?
CoT quan trọng không phải vì bạn cần dùng nó nhiều hơn, mà vì nó đã được tích hợp vào kiến trúc của các reasoning model thế hệ mới. Đây là điều mà phần lớn bài viết tiếng Việt về CoT bỏ qua hoàn toàn.
Chuỗi lý luận trung gian là nền tảng của reasoning models:
- Claude 3.7 Sonnet với Extended Thinking: Khi bật thinking mode, model tự tạo ra chuỗi lý luận nội bộ trước khi trả lời. Bạn không cần viết “hãy suy nghĩ từng bước”, model tự làm.
- o1 và o3 của OpenAI: Được train với CoT internalized. Model “nghĩ” trong nhiều giây trước khi output, toàn bộ là chuỗi lý luận trung gian chạy ngầm.
- Gemini 2.0 Flash Thinking: Tương tự, thinking tokens được tạo trước response.
Điều này nghĩa là gì với bạn? Khi dùng Claude 3.7 Thinking hay o1, bạn không cần thêm CoT prompt vào. Những gì bạn có thể làm là cung cấp context rõ ràng hơn để model suy luận đúng hướng. Thay vì “hãy suy nghĩ từng bước”, hãy mô tả bài toán chi tiết hơn và định nghĩa rõ output mong muốn.
Với các model không có thinking mode như Claude 3.5 Haiku hay GPT-4o mini, CoT manual vẫn hiệu quả rõ rệt. Đây là lý do bạn vẫn cần hiểu kỹ thuật này dù reasoning models đang phổ biến. Tham khảo thêm ở temperature AI, vì temperature ảnh hưởng trực tiếp đến chất lượng chuỗi lý luận trung gian mà CoT tạo ra.
Khi Nào Nên, Và Không Nên, Dùng CoT?
Token-Accuracy Trade-off là khái niệm cốt lõi để quyết định có dùng CoT không. CoT dùng 3 đến 5x token so với prompt thông thường. Với reasoning models như o1, con số có thể lên đến 20x. Bạn trả tiền cho sự chính xác, vậy khi nào trade-off này đáng giá?
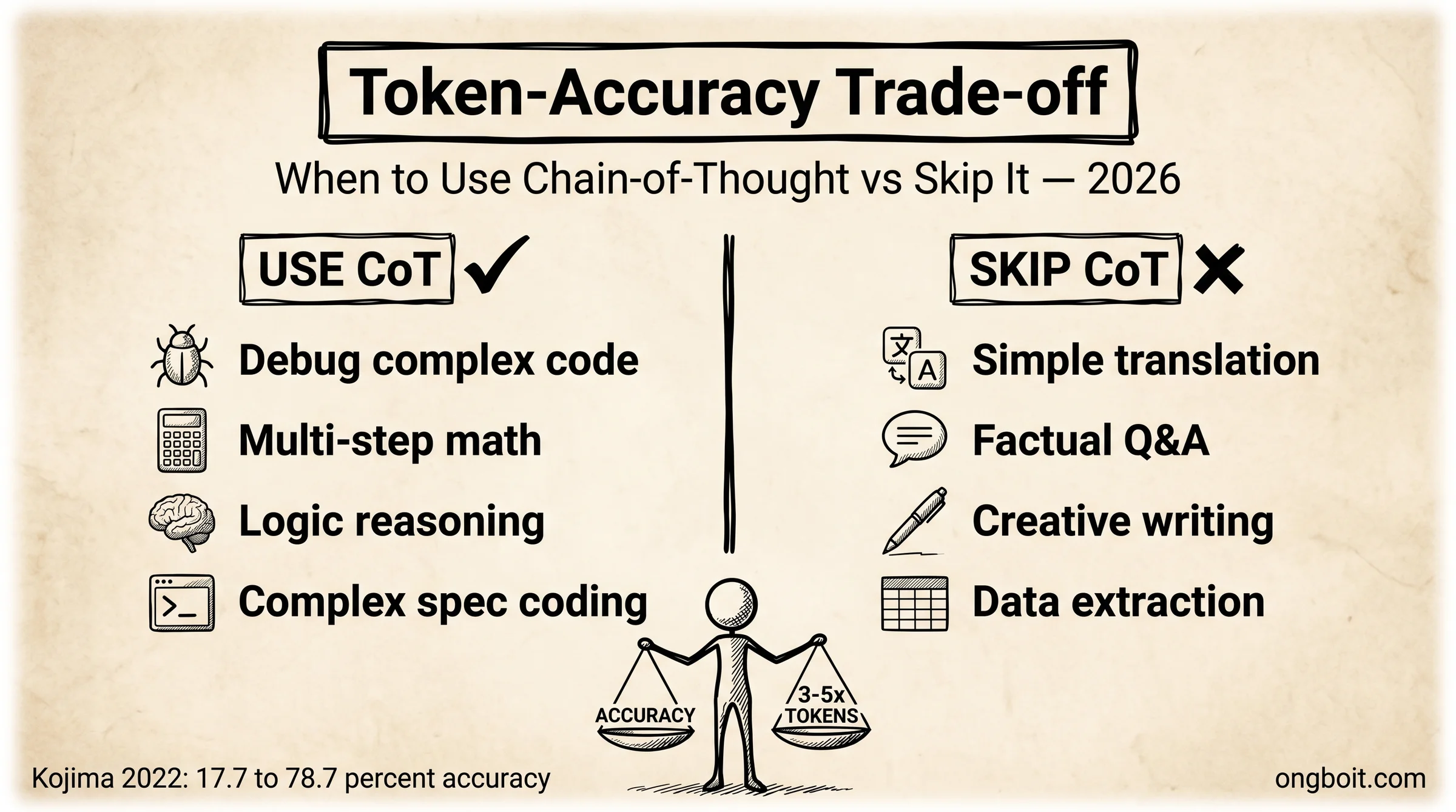
| Task | Dùng CoT? | Lý do |
|---|---|---|
| Debug code phức tạp | Có | Nhiều bước logic, lỗi ẩn |
| Giải toán nhiều bước | Có | Sai 1 bước = sai toàn bộ |
| Phân tích logic / reasoning | Có | Cần trace từng assumption |
| Viết code từ spec phức tạp | Có | Edge cases ẩn cần suy luận |
| Dịch văn bản đơn giản | Không | 1 bước, token wasted |
| Trả lời câu hỏi factual | Không | Không cần reasoning chain |
| Viết nội dung sáng tạo | Không | CoT giới hạn creativity |
| Extract dữ liệu từ text | Không | Pattern matching, không reasoning |
Quy tắc nhanh: nếu bài toán có thể sai ở bước trung gian và lỗi đó ảnh hưởng đến kết quả cuối, CoT đáng dùng. Nếu task là 1 bước hoặc creative, bỏ qua CoT để tiết kiệm token.
Chain-of-Thought Cải Thiện Bao Nhiêu? (Số Liệu Thực Tế)
GSM8K benchmark (bài toán toán học tiểu học) là dataset chuẩn nhất để đo CoT. Kết quả từ Wei et al. 2022 (Google Brain):
- PaLM 540B không có CoT: 17.9% độ chính xác
- PaLM 540B với CoT: 58.1% độ chính xác (+40.2 điểm phần trăm)
- Chỉ thêm “Let’s think step by step” vào GPT-3: từ 17.7% lên 78.7% trên MultiArith benchmark
Đây là lý do CoT trở thành kỹ thuật prompting được cite nhiều nhất trong 2 năm qua. Không phải “thêm vài từ” mà là “tăng gần gấp đôi độ chính xác.”
Chain-of-Thought Có Nhược Điểm Gì?
CoT không phải magic và có 3 nhược điểm rõ ràng:
1. Tốn token gấp 3-20x: Với prompt thường, Claude trả lời 50-100 token. Với CoT, phần reasoning chain có thể dài 200-500 token trước khi đến kết quả. Extended Thinking API tính phí thinking tokens riêng. Với workload production số lượng lớn, chi phí này không negligible.
2. False reasoning chain (hallucination trong suy luận): CoT không đảm bảo reasoning đúng, chỉ đảm bảo reasoning được hiển thị. Model có thể tạo ra chuỗi lý luận trông hợp lý nhưng sai từ bước đầu, rồi reach đến kết luận sai một cách “confident.” Đây nguy hiểm hơn không có CoT vì người dùng tin vào reasoning đã thấy.
3. Hurt performance trên task đơn giản: Với task pattern matching hoặc factual recall (không cần reasoning), thêm “let’s think step by step” thực ra có thể làm giảm độ chính xác. Model bắt đầu “overthink” và đưa ra reasoning không cần thiết dẫn đến wrong answer. Rule of thumb: nếu bạn có thể trả lời câu hỏi đó trong 3 giây, đừng dùng CoT.
Làm Sao Dùng CoT Với Claude Hiệu Quả? (3 Pattern Thực Tế)
Kỹ thuật CoT áp dụng trực tiếp vào system prompt hoặc user message của Claude. Dưới đây là 3 pattern thực tế theo thứ tự phức tạp tăng dần.
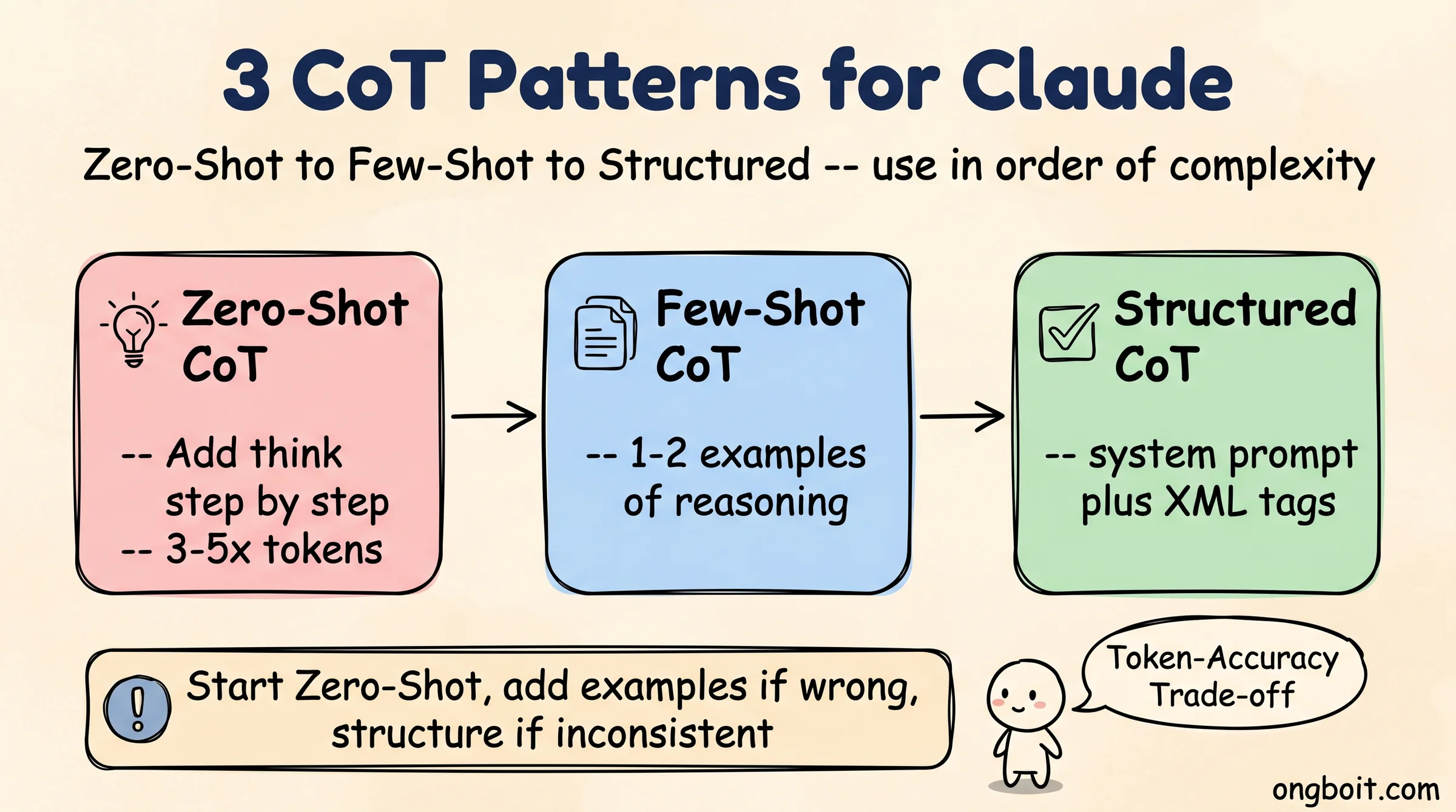
Pattern 1: Zero-Shot CoT (đơn giản nhất)
Phân tích lỗi trong đoạn code Python này.
Hãy suy nghĩ từng bước: xác định vấn đề, giải thích tại sao lỗi, đề xuất fix.
Pattern 2: Few-Shot CoT (khi cần format cụ thể)
Phân tích bug theo format sau:
Ví dụ 1: [Code có bug] → Bước 1: Nguyên nhân ... Bước 2: Ảnh hưởng ... Fix: ...
Ví dụ 2: [Code có bug] → Bước 1: ... Bước 2: ... Fix: ...
Bây giờ phân tích: [code của bạn]
Pattern 3: Claude Extended Thinking API (không cần viết CoT)
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-3-7-sonnet-20250219",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000 # token ngân sách cho thinking
},
messages=[{
"role": "user",
"content": "Debug đoạn code Python này và giải thích nguyên nhân lỗi."
}]
)
Pattern 3 sử dụng Extended Thinking của Anthropic, model tự tạo chuỗi lý luận trung gian mà không cần bạn viết CoT prompt. Token-Accuracy Trade-off ở đây lớn hơn (thinking tokens tính phí riêng), nhưng chất lượng reasoning cao nhất. Xem thêm tại Anthropic Extended Thinking docs và hướng dẫn về prompt engineering cho các kỹ thuật nâng cao.
Chain-of-Thought Kết Hợp Với Các Khái Niệm Khác Trong Hệ Sinh Thái LLM
Phần này giúp người đọc hiểu rõ vị trí của Chain-of-Thought trong toàn bộ hệ sinh thái LLM năm 2026. Hiểu được mối liên kết giữa các khái niệm giúp lập trình viên áp dụng đúng kỹ thuật cho từng tình huống cụ thể, tránh việc lạm dụng pattern không phù hợp với bài toán đang gặp phải.
Chain-of-Thought là một trong những Prompt Engineering pattern quan trọng nhất hiện nay. Để hiểu sâu hơn về các kỹ thuật prompting khác, người mới nên tham khảo Prompt Engineering cho Claude Code. Tài liệu này tổng hợp 10 khái niệm cơ bản bao gồm CoT, Zero-shot, Few-shot, System Prompt, Context Engineering, và nhiều kỹ thuật khác. Đầu tư 2-3 ngày đọc kỹ tài liệu này giúp người mới có nền tảng vững chắc để áp dụng các Prompt Engineering pattern nâng cao về sau.
Một khái niệm quan trọng khác cần nắm vững là token trong LLM. Chain-of-Thought tiêu tốn nhiều token hơn so với prompt thông thường vì model phải sinh ra cả intermediate reasoning steps trước khi đưa ra câu trả lời cuối cùng. Hiểu rõ cơ chế tính phí theo token giúp đội ngũ phát triển sản phẩm dự đoán chính xác chi phí khi áp dụng CoT cho dự án production quy mô lớn. Pattern khôn ngoan là chỉ áp dụng CoT cho các tác vụ thực sự cần độ chính xác cao về logic, không phải mọi prompt trong dự án.
Đối với các tác vụ automation phức tạp đòi hỏi agent tự đưa ra quyết định và thực hiện hành động, CoT thường được kết hợp với pattern AI Agent. AI Agent thế hệ mới như Claude Opus 4.7 và GPT-5.4 đã tích hợp sẵn CoT trong cơ chế hoạt động mặc định, không cần lập trình viên phải kích hoạt thủ công. Tuy nhiên hiểu rõ cách CoT hoạt động bên trong vẫn quan trọng để debug khi agent đưa ra quyết định không mong muốn.
Áp Dụng Chain-of-Thought Cho Đội Nhóm Việt Nam Năm 2026 Như Thế Nào?
Phần này tổng hợp 3 lưu ý quan trọng khi áp dụng CoT cho đội nhóm phát triển sản phẩm tại Việt Nam. Mỗi lưu ý đều rút ra từ kinh nghiệm thực chiến của các đội nhóm đã triển khai thành công trong 6 tháng đầu năm 2026.
Lưu ý đầu tiên là về việc cân bằng giữa độ chính xác và chi phí khi áp dụng CoT vào sản phẩm thật. CoT cải thiện đáng kể độ chính xác cho các tác vụ logic phức tạp nhưng cũng tăng chi phí token từ 2 đến 5 lần so với prompt thông thường. Đối với sản phẩm có yêu cầu phản hồi nhanh và chi phí thấp như chatbot chăm sóc khách hàng đại trà, CoT không phải lựa chọn tối ưu. Pattern khôn ngoan là chỉ áp dụng CoT cho các luồng đặc biệt yêu cầu độ chính xác cao như phân tích báo cáo tài chính hoặc tư vấn pháp lý chuyên sâu, các luồng còn lại sử dụng prompt thông thường để tiết kiệm chi phí.
Lưu ý thứ hai là về việc thiết kế CoT trigger prompt phù hợp với ngôn ngữ tiếng Việt. Nhiều đội nhóm sao chép prompt tiếng Anh nguyên gốc khi dịch sản phẩm sang thị trường Việt Nam, dẫn đến hiệu quả không cao. CoT trigger trong tiếng Việt cần ngắn gọn và rõ ràng hơn so với tiếng Anh, ví dụ câu “Hãy suy nghĩ từng bước trước khi trả lời” cho hiệu quả tốt hơn nhiều so với bản dịch nguyên văn từ tiếng Anh. Đầu tư thời gian kiểm thử nhiều biến thể prompt tiếng Việt khác nhau giúp tìm ra prompt tối ưu cho ngữ cảnh kinh doanh cụ thể của doanh nghiệp.
Lưu ý cuối cùng là về việc đào tạo đội ngũ hiểu rõ giới hạn của CoT. Mặc dù CoT cải thiện đáng kể độ chính xác cho nhiều tác vụ, nhưng không phải tác vụ nào cũng hưởng lợi. Đối với tác vụ đơn giản như phân loại nội dung hoặc trích xuất thông tin từ văn bản ngắn, CoT có thể gây ra phản hồi dài dòng không cần thiết. Đào tạo đội ngũ biết khi nào nên áp dụng và khi nào không là skill quan trọng giúp tối ưu chi phí và chất lượng sản phẩm dài hạn cho doanh nghiệp.
Câu Hỏi Thường Gặp
Chain-of-Thought prompting là gì?
Chain-of-Thought (CoT) prompting là kỹ thuật yêu cầu AI tạo ra chuỗi lý luận trung gian (intermediate reasoning steps) trước khi đưa ra câu trả lời cuối. Thay vì trả lời trực tiếp, model phân rã bài toán thành các bước nhỏ, giải từng bước theo thứ tự, rồi tổng hợp kết quả. Kỹ thuật này được Wei et al. tại Google Brain giới thiệu năm 2022.
Khi nào nên dùng Chain-of-Thought?
Dùng CoT khi task có nhiều bước logic liên tiếp mà lỗi ở bước trung gian sẽ làm sai toàn bộ kết quả: debug code phức tạp, giải toán nhiều bước, phân tích reasoning, viết code từ spec phức tạp. Không cần CoT cho dịch văn bản, trả lời câu hỏi factual đơn giản, hoặc task sáng tạo.
Zero-Shot CoT và Few-Shot CoT khác gì nhau?
Zero-shot CoT chỉ thêm câu “hãy suy nghĩ từng bước” vào prompt mà không cần ví dụ mẫu. Few-shot CoT cung cấp 2-3 ví dụ có chuỗi lý luận đầy đủ trước khi đặt câu hỏi chính. Zero-shot đơn giản hơn và tốn ít token hơn; few-shot chính xác hơn và kiểm soát được format output.
Claude 3.7 Thinking có tự dùng CoT không?
Có. Khi bật Extended Thinking, Claude 3.7 Sonnet tự tạo chuỗi lý luận trung gian trước khi trả lời, không cần bạn viết CoT prompt. Tương tự với o1 và o3 của OpenAI. Với các model không có thinking mode (Haiku, GPT-4o mini), bạn vẫn cần viết CoT thủ công để đạt kết quả tương đương.
Chain-of-Thought tốn thêm bao nhiêu token?
CoT thủ công tốn thêm 3 đến 5x token so với prompt thông thường. Với reasoning models như Claude 3.7 Extended Thinking hay o1, con số có thể lên đến 5 đến 20x vì thinking tokens được tính riêng theo bảng giá của từng provider. Đây là Token-Accuracy Trade-off cần cân nhắc kỹ trước khi áp dụng cho toàn bộ use case.
Kết Luận
Chain-of-thought không chỉ là kỹ thuật thêm vào prompt. Nó là cơ chế suy luận mà AI dùng để giải bài toán phức tạp, và hiện đã được tích hợp vào kiến trúc của các reasoning model thế hệ mới. Nếu bạn đang dùng Claude 3.7 Thinking hay o1, model đã tự làm CoT cho bạn. Nếu bạn dùng model nhẹ hơn, hiểu chuỗi lý luận trung gian và Token-Accuracy Trade-off sẽ giúp bạn quyết định khi nào nên kích hoạt CoT thủ công.
Để hiểu sâu hơn về cơ chế reasoning, xem thêm bài về ảo giác AI (CoT giúp giảm hallucination đáng kể) và context window để hiểu giới hạn bộ nhớ tác động đến chất lượng chuỗi suy luận.
Kiến thức nền này sẽ giúp bạn học Claude Code hiệu quả hơn. Xem lộ trình 8 levels để biết bước tiếp theo.