LLM Là Gì? So Sánh 16 Model AI Mới Nhất Cho Developer

Bạn search “LLM là gì” trên Google ra hai kết quả hoàn toàn khác nhau: một nửa trang nói về bằng Thạc sĩ Luật (LL.M., Master of Laws), một nửa nói về AI. Dấu hai chấm trong LL.M. tách biệt hai thứ đó, nhưng Google xếp chung vào một trang kết quả vì viết tắt giống nhau.
Bài này nói về cái thứ hai: LLM trong AI là Large Language Model, mô hình ngôn ngữ lớn. Đây là công nghệ đứng sau ChatGPT, Claude, Gemini và mọi trợ lý AI bạn dùng hàng ngày. Mình sẽ giải thích LLM hoạt động thế nào, so sánh 16 model mới nhất tháng 4/2026 (Claude Opus 4.7, GPT-5.4, Gemini 3.1 Pro, Grok 4.1, DeepSeek V3.2, Qwen 3.5, GLM-5.1, Kimi K2.5, Gemma 4, Llama 4…), và chia sẻ kinh nghiệm chọn model cho workflow lập trình thực tế.
TL;DR
- LLM (Large Language Model) là mô hình AI deep learning được train trên hàng tỷ token văn bản để dự đoán token tiếp theo theo xác suất. KHÔNG phải bằng luật LL.M.
- Công nghệ lõi: Kiến trúc Transformer. GPT, Claude, Gemini, Llama đều là LLM khác nhau về kích thước, dữ liệu train, và fine-tuning.
- 16 model mới nhất 4/2026: Claude Opus 4.7 + Sonnet 4.6 + Haiku 4.5; GPT-5.4 + 5.3 Codex + o3-mini; Gemini 3.1 Pro + 2.5 Pro/Flash/Flash-Lite; Grok 4.1 (2M context); DeepSeek V3.2; Qwen 3.5; GLM-5.1; Kimi K2.5; Gemma 4; Llama 4. Giá chênh 50 lần (từ $0.10 đến $5.00/1M input).
- Developer chọn: Opus 4.7 hoặc GPT-5.4 cho task khó, Sonnet 4.6 hoặc 5.3 Codex cho code, Grok 4.1 cho frontier rẻ, DeepSeek V3.2 hoặc Qwen 3.5 cho khối lượng lớn.
- Claude Code là ví dụ LLM chạy production: terminal + tools + sub-agents, không cần framework phức tạp.
LLM trong AI (Large Language Model) khác hoàn toàn với LL.M. (Master of Laws, bằng Thạc sĩ Luật). Google xếp chung vì viết tắt giống, nhưng nội dung hai lĩnh vực.
LLM Là Gì Và Tại Sao Quan Trọng Với Developer?
LLM trong AI là viết tắt của Large Language Model (mô hình ngôn ngữ lớn). LL.M. có hai dấu chấm là viết tắt của Legum Magister trong tiếng Latinh, nghĩa là Master of Laws (Thạc sĩ Luật). Khi bạn search “llm” trên Google tại Việt Nam, kết quả hàng đầu thường là về bằng luật vì từ khóa “llm master of laws” có 8,100 lượt tìm/tháng, gấp hơn 3 lần so với “llm là gì” (2,400/tháng, theo DataForSEO tháng 4/2026).
Hai lĩnh vực này không liên quan gì đến nhau. LL.M. xuất hiện khi bạn tìm chương trình học luật quốc tế tại các trường như Harvard, Yale, hay Oxford. LLM xuất hiện khi bạn tìm hiểu về ChatGPT, Claude, hoặc công nghệ AI tạo sinh. Cách phân biệt nhanh nhất: nếu thấy hai dấu chấm giữa các chữ (L.L.M. hoặc LL.M.) thì đó là về luật, còn LLM viết liền là về AI.
Bài viết này tập trung 100% vào LLM trong AI. Nếu bạn đang tìm thông tin về bằng luật, bài này không dành cho bạn. Nếu bạn đang build sản phẩm AI, viết code với Claude, hay tò mò công nghệ đứng sau ChatGPT, đọc tiếp.
LLM Là Gì Trong AI?
LLM (Large Language Model) là một loại mô hình trí tuệ nhân tạo học sâu được train trên hàng tỷ token văn bản để hiểu, dự đoán, và tạo ra ngôn ngữ tự nhiên giống con người. “Large” trong tên không chỉ nói về dữ liệu train mà còn về số tham số (parameters) của mô hình, thường từ vài tỷ đến vài nghìn tỷ. GPT-4, Claude Sonnet 4.6, Gemini 1.5 Pro, và Llama 4 đều là LLM.
Cốt lõi kỹ thuật của LLM là kiến trúc Transformer được Google công bố năm 2017 trong paper “Attention is All You Need”. Transformer cho phép mô hình hiểu mối quan hệ giữa các từ cách xa nhau trong câu, điều mà các kiến trúc cũ như RNN không làm tốt. Cơ chế attention (chú ý) giúp mô hình “nhìn” đồng thời toàn bộ context để chọn từ tiếp theo.
Quan trọng: LLM không “hiểu” theo nghĩa con người. Nó dự đoán token tiếp theo có khả năng xuất hiện cao nhất dựa trên pattern học được từ dữ liệu train. Đó là lý do AI đôi khi hallucinate sai lệch: khi prediction khác xa sự thật, mô hình không có cơ chế tự kiểm tra vì nó không biết đâu là đúng, chỉ biết đâu là xác suất cao.
LLM Hoạt Động Như Thế Nào?
LLM hoạt động qua ba giai đoạn: Pretraining (huấn luyện ban đầu trên tập dữ liệu khổng lồ), Fine-tuning (điều chỉnh cho task cụ thể), và Inference (suy luận khi bạn gửi prompt). Mỗi giai đoạn có chi phí và đặc điểm khác nhau.
Pretraining là giai đoạn tốn kém nhất. Mô hình đọc hàng trăm tỷ đến hàng nghìn tỷ token từ Internet: sách, bài báo, Wikipedia, code trên GitHub, và văn bản công khai. Quá trình này có thể chạy nhiều tuần trên hàng nghìn GPU và tốn từ vài triệu đến trăm triệu USD. Kết quả là mô hình có weights (trọng số), dãy số khổng lồ lưu trữ pattern ngôn ngữ.
Fine-tuning (tinh chỉnh) là giai đoạn biến mô hình base thành công cụ hữu ích. Claude Sonnet 4.6 được tune để tuân thủ hướng dẫn, từ chối nội dung có hại, và xuất code chất lượng cao. Kỹ thuật RLHF (Reinforcement Learning from Human Feedback) cho phép mô hình học từ đánh giá của con người: người đánh giá chọn response tốt hơn, mô hình điều chỉnh để tạo nhiều response như vậy hơn.
Inference là giai đoạn bạn thực sự dùng. Khi gõ prompt vào ChatGPT hay Claude, mô hình dự đoán token tiếp theo có khả năng cao nhất, rồi token kế tiếp, và tiếp tục cho đến khi hoàn thành response. Mỗi token dự đoán tốn một lượng compute, đó là lý do API tính phí theo số token bạn dùng. Bản chất xác suất là nguyên nhân chính gây ra hallucinate: khi không có đủ dữ liệu đúng, mô hình vẫn chọn token có xác suất cao nhất, dù thông tin sai.
RAG (Retrieval-Augmented Generation) là kỹ thuật mở rộng khả năng LLM bằng cách kết hợp retrieval engine với generation. Thay vì chỉ dựa vào weights được train trước, RAG tìm kiếm tài liệu liên quan từ knowledge base (vector database) và đưa vào context mỗi lần inference. Kết quả: LLM trả lời chính xác hơn về thông tin mới hoặc domain cụ thể mà không cần retrain tốn kém. Đây là kiến trúc phổ biến nhất để build chatbot doanh nghiệp tiếng Việt dùng LLM.
10 Khái Niệm LLM Cơ Bản Mọi Developer Cần Biết
Trước khi đi sâu vào so sánh model, mình tổng hợp 10 khái niệm nền tảng mà mọi developer làm việc với LLM cần nắm vững. Đây là vocabulary cốt lõi quyết định bạn đọc hiểu tài liệu kỹ thuật của Anthropic, OpenAI, Google, hay debug được production issue khi tích hợp LLM vào sản phẩm. Mỗi khái niệm có bài giải thích riêng đi sâu hơn, bài viết này chỉ tóm gọn để bạn nắm bản chất nhanh.
1. Machine Learning là khái niệm cha của LLM. Học máy là nhánh trí tuệ nhân tạo nghiên cứu cách máy tính tự học từ dữ liệu thay vì lập trình từng quy tắc cụ thể. LLM là một dạng học máy cụ thể dùng kiến trúc Transformer và phương pháp học sâu (deep learning) với hàng tỷ tham số. Hiểu nền tảng học máy giúp bạn không bị bối rối khi đọc tài liệu kỹ thuật của các hãng AI.
2. Token là đơn vị nhỏ nhất mà LLM xử lý. Khi bạn gửi câu “Tôi yêu Việt Nam” cho Claude, hệ thống chia câu thành 6-8 token tùy tokenizer. Tiếng Việt tốn nhiều token hơn tiếng Anh vì chữ có dấu được encode thành nhiều byte. API tính phí theo token nên hiểu cơ chế này giúp tiết kiệm chi phí đáng kể khi build sản phẩm ở thị trường Việt.
3. Context window là độ dài tối đa của input + output mà model xử lý được trong một lần gọi. Claude Opus 4.7 có context 1 triệu token, Grok 4.1 có context 2 triệu, Llama 4 Scout có 10 triệu. Vượt quá ngưỡng này thì model quên đầu cuộc hội thoại hoặc cắt mất thông tin quan trọng. Chọn model context lớn khi cần đọc codebase dài hoặc phân tích tài liệu hàng trăm trang.
4. Temperature là tham số điều khiển độ ngẫu nhiên của LLM khi sinh token. Temperature thấp (0.0-0.3) cho output ổn định, phù hợp tác vụ cần độ chính xác cao như viết code hoặc trả lời câu hỏi factual. Temperature cao (0.7-1.0) cho output đa dạng, phù hợp viết sáng tạo, brainstorm ý tưởng. Hầu hết API mặc định 0.7 nhưng cho code thì giảm xuống 0.2-0.3 sẽ ổn định hơn nhiều.
5. System prompt là phần hướng dẫn được đặt ở đầu hội thoại, định nghĩa vai trò và quy tắc hành xử của LLM. Ví dụ “Bạn là chuyên gia DevOps, trả lời ngắn gọn bằng tiếng Việt, không dùng jargon nếu không cần thiết”. System prompt áp dụng cho toàn bộ phiên làm việc và có trọng số cao hơn user prompt. Đây là kỹ thuật quan trọng nhất khi build chatbot doanh nghiệp.
6. Session là khái niệm phiên làm việc trong Claude Code và các công cụ LLM hiện đại. Mỗi session có context riêng, lịch sử hội thoại riêng, và bộ tool có thể truy cập riêng. Hiểu vòng đời session quan trọng khi debug production issue hoặc tối ưu chi phí API vì mỗi session mới phải gửi lại toàn bộ system prompt và context, tốn token đáng kể.
7. Chain-of-Thought (CoT) là kỹ thuật prompt khuyến khích LLM “suy nghĩ ra giấy” trước khi trả lời cuối cùng. Khi thêm câu “Hãy suy nghĩ từng bước trước khi trả lời” vào prompt, độ chính xác trên các bài toán logic phức tạp tăng từ 30-40% lên 70-80%. Claude Opus 4.7 và GPT-5.4 đều có chế độ reasoning tích hợp sẵn dùng CoT mặc định.
8. Zero-shot và Few-shot Learning là hai cách dạy LLM giải bài toán mới qua prompt. Zero-shot là yêu cầu trực tiếp không kèm ví dụ. Few-shot là cung cấp 2-5 ví dụ mẫu trước khi đưa bài toán thực. Few-shot thường cho kết quả tốt hơn 20-40% nhưng tốn nhiều token hơn. Hiểu cách chọn giữa hai pattern này tiết kiệm chi phí đáng kể khi gọi API ở quy mô lớn.
9. Prompt caching là kỹ thuật Anthropic và OpenAI hỗ trợ để giảm chi phí cho prompt lặp lại nhiều lần. Khi bật caching, phần system prompt và context tĩnh được lưu vào bộ nhớ tạm của hãng, lần gọi sau chỉ tính phí phần thay đổi. DeepSeek V3.2 giảm tới 90% chi phí với caching. Đây là technique quan trọng nhất khi build chatbot có traffic lớn.
10. Context engineering là nghệ thuật thiết kế context window hiệu quả cho LLM. Khác với prompt engineering tập trung vào câu lệnh, context engineering quản lý toàn bộ thông tin model “thấy” mỗi lần inference: system prompt, lịch sử hội thoại, tài liệu tham khảo, kết quả tool call. Context engineering tốt là kỹ năng phân biệt developer làm AI hời hợt với chuyên gia thực thụ trong giai đoạn 2026-2027.
Mười khái niệm trên là vocabulary tối thiểu mà mọi developer Việt làm việc với LLM cần thuộc lòng. Mình đã viết bài chi tiết cho từng khái niệm, có thể click vào anchor để đọc sâu hơn. Học vững mười thuật ngữ này giúp bạn giao tiếp hiệu quả với đội nhóm AI quốc tế, đọc nhanh tài liệu vendor, và debug được production issue khi tích hợp LLM vào sản phẩm thực tế.
16 Model LLM Mới Nhất So Sánh Thế Nào?
Thị trường LLM tháng 4/2026 biến động rất nhanh: Gemini 3 Pro đã discontinued, GPT-5.4 ra tháng 3, Claude Opus 4.7 ra 16/4, Grok 4.1 có giá frontier rẻ nhất, và nhiều model Trung Quốc (GLM-5.1, Kimi K2.5, Qwen 3.5, DeepSeek V3.2) đang thu hẹp khoảng cách với closed-source. Bảng dưới tổng hợp 16 model mới nhất chia 4 tầng, giá xác minh từ trang pricing chính thức tính đến 22/4/2026.
| Model | Nhà phát triển | Context | Input ($/1M) | Output ($/1M) | Thế mạnh |
|---|---|---|---|---|---|
| 🏆 Tầng Flagship: reasoning + chất lượng cao nhất (2026-04) | |||||
| Claude Opus 4.7 🆕 | Anthropic (16/4) | 1M | $5.00 | $25.00 | SWE-bench 80.8%, dẫn đầu code + agentic task khó |
| GPT-5.4 🆕 | OpenAI (3/2026) | 1M+ | $2.50 | $15.00 | Computer Use 75% OSWorld, 5-level reasoning control |
| Gemini 3.1 Pro 🆕 | Google (2/2026) | 1M | $2.00 | $12.00 | Thay Gemini 3 Pro đã discontinued 26/3/2026, agentic mạnh |
| Grok 4.1 🆕 | xAI | 2M | $0.20 | $0.50 | Frontier rẻ nhất + context 2M lớn nhất thị trường |
| ⚖️ Tầng Cân Bằng: best giá/chất lượng | |||||
| Claude Sonnet 4.6 | Anthropic | 1M | $3.00 | $15.00 | Code production, agentic workflow, Claude Code |
| GPT-5.3 Codex | OpenAI | 400K | $1.75 | $14.00 | Chuyên code-specialized, thay GPT-4o cho developer |
| Gemini 2.5 Pro | 1M | $1.25 | $10.00 | Cân bằng context dài + chi phí thấp | |
| ⚡ Tầng Fast/Budget: khối lượng lớn, chi phí thấp | |||||
| Claude Haiku 4.5 | Anthropic | 200K | $1.00 | $5.00 | Sub-agents, task đơn giản, Claude Code tier rẻ |
| o3-mini | OpenAI | 200K | $0.55 | $2.20 | Reasoning chuyên biệt, chi phí trung bình |
| Gemini 2.5 Flash | 1M | $0.30 | $2.50 | Context dài giá rẻ, response nhanh | |
| Gemini 2.5 Flash-Lite | 1M | $0.10 | $0.40 | Rẻ nhất còn actively supported của Google | |
| 🌏 Tầng Open/Chinese: open-weights hoặc alternative mới nhất | |||||
| DeepSeek V3.2 🆕 | DeepSeek (TQ) | 128K | $0.28 | $0.42 | MIT license, ~90% chất lượng GPT-5.4, 90% cache discount |
| Qwen 3.5 🆕 | Alibaba (TQ) | 128K | $0.10 | $0.40 | Reasoning 397B params, top Chinese benchmark |
| GLM-5.1 🆕 | Zhipu AI (TQ) | 128K | $0.30 | $1.10 | #1 BenchLM Chinese leaderboard (score 84) |
| Kimi K2.5 🆕 | Moonshot (TQ) | 256K | $0.60 | $2.50 | 1T params / 384 MoE experts, dẫn đầu open-source SWE-rebench, agent-native |
| Gemma 4 🆕 | Google (open) | 128K | Self-host | Self-host | MoE 26B params, 14GB, 85 tok/s consumer hardware |
| Llama 4 Scout | Meta (open) | 10M | $0.11* | $0.34* | Open-weights, context 10M, self-host miễn phí |
🆕 = model ra mắt trong 3 tháng gần nhất (Feb-Apr 2026). *Llama 4 Scout: giá API qua third-party (Groq, Together). Giá xác minh 22/4/2026 từ Anthropic pricing, OpenAI API, Google Gemini, Vellum LLM Leaderboard 2026, BenchLM Chinese Leaderboard.
Lưu ý về các model mới ra mắt (GPT-5.4, Gemini 3.1 Pro, Grok 4.1): những model này đã công bố qua trang chính thức của vendor trong Feb-Apr 2026 (OpenAI blog, Google Vertex AI, xAI docs) nhưng chưa xuất hiện đầy đủ trên các leaderboard bên thứ ba tại thời điểm bài viết. Nếu bạn đang build production, verify trực tiếp trên trang pricing vendor trước khi quyết định chọn model.
Bảng này được tổng hợp từ announcement chính thức của các hãng và benchmark leaderboard tính đến tháng 4/2026, có thể thay đổi khi model mới ra mắt.
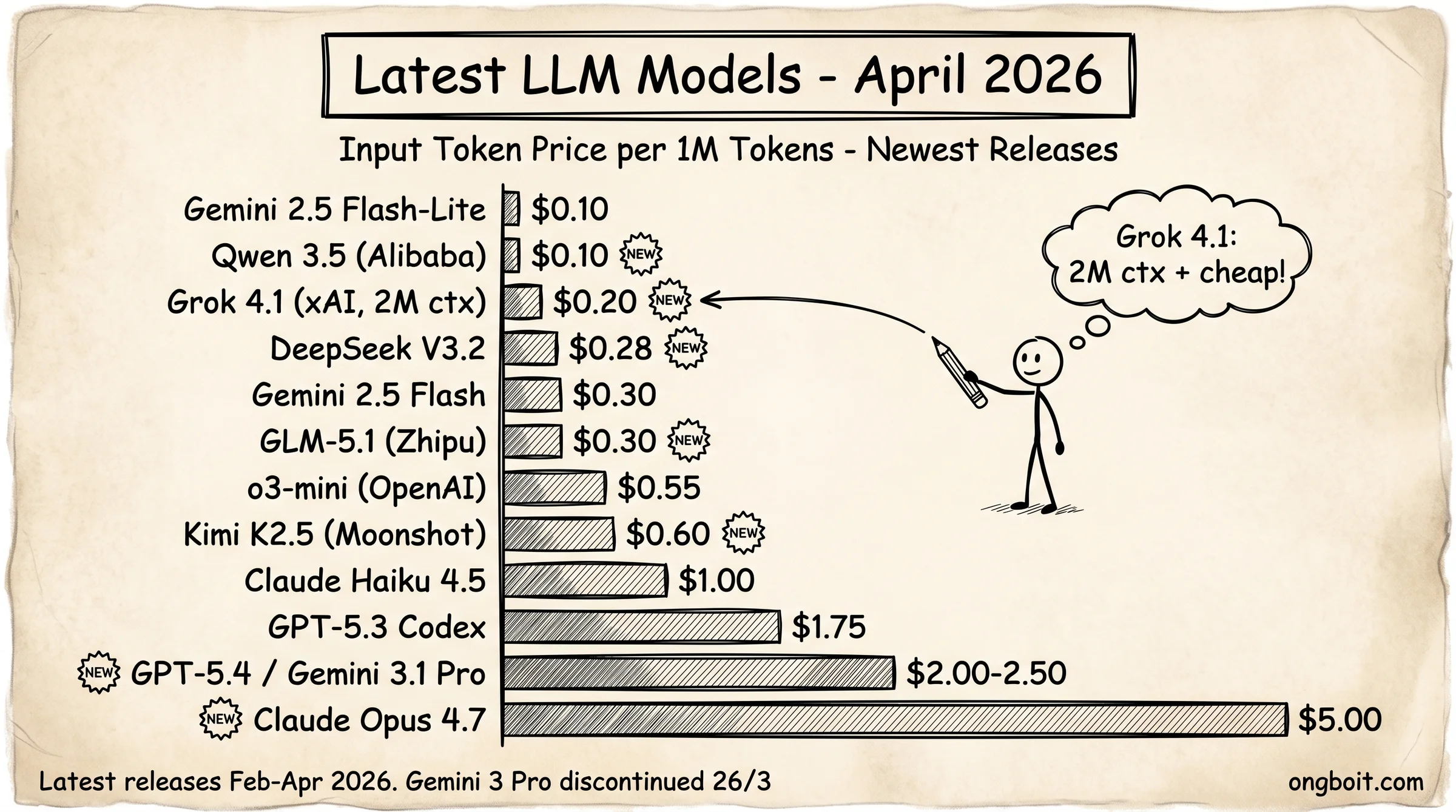
Chênh lệch giá giữa các model lên đến 50 lần trong số API public: Gemini 2.5 Flash-Lite tốn $0.10/1M input token, Claude Opus 4.7 tốn $5.00/1M. Context window cũng chênh lớn: Grok 4.1 dẫn đầu với 2M token, Llama 4 Scout có 10M (context siêu dài), còn DeepSeek V3.2 và GLM-5.1 chỉ 128K. Context window rộng quan trọng với task đọc codebase lớn hay phân tích tài liệu dài, nếu bạn chưa hiểu context window, đọc bài context window là gì.
Góc nhìn cho developer: 90% bài LLM là gì tiếng Việt KHÔNG nhắc đến chi phí. Nhưng với tokenizer English-first, tiếng Việt tốn gấp 2 lần token so với cùng đoạn tiếng Anh. Nghĩa là thực tế chi phí API bạn trả cho 1,000 chữ tiếng Việt bằng chi phí ~2,000 chữ tiếng Anh. Điều này làm chi phí thực tế của Sonnet 4.6 cho nội dung tiếng Việt gần với GPT-5 hơn so với quảng cáo, mình đo chi tiết trong bài token là gì.
Đây là lý do nhiều team dùng model nhỏ hơn cho các task đơn giản và chỉ gọi model mạnh khi thực sự cần reasoning phức tạp.
Tại sao nhiều model thế? Mỗi provider tối ưu cho use case khác nhau: Anthropic ưu tiên code quality + agentic workflow (Claude Code build trên Sonnet, Opus 4.7 dẫn đầu SWE-bench 80.8%). OpenAI ưu tiên general purpose + Computer Use (GPT-5.4 đạt 75% OSWorld). Google ưu tiên context window dài + giá rẻ (Gemini 3.1 Pro thay Gemini 3 đã discontinued). xAI với Grok 4.1 bất ngờ tung giá frontier rẻ nhất + context 2M. Hệ sinh thái Trung Quốc (DeepSeek, Qwen, GLM, Kimi) thu hẹp khoảng cách với quality 90% closed-source ở chi phí 1/10. Meta và Google (Gemma 4) đẩy mạnh open-source để self-host.
Điều thú vị là mỗi hãng chọn tối ưu hóa cho một use case khác nhau, nên không có model nào thực sự “tốt nhất” cho mọi tình huống. Không có model “tốt nhất” tuyệt đối, chỉ có model phù hợp nhất với workflow cụ thể.
LLM Khác Chatbot và AI Agent Thế Nào?
LLM là công nghệ nền, Chatbot là sản phẩm giao diện, AI Agent là LLM được bổ sung công cụ và vòng lặp tự động. Ba khái niệm dễ bị nhầm nhưng thực ra là ba tầng khác nhau trong stack AI.
LLM là tầng thấp nhất. Nó chỉ là model, một dãy weights được host trên server và trả về token prediction khi bạn gửi prompt qua API. LLM không có giao diện, không có memory giữa các cuộc hội thoại, không có tool để tương tác thế giới thực. Claude Sonnet 4.6 là LLM thuần túy.
Chatbot là LLM cộng thêm giao diện chat và session management. ChatGPT là chatbot dùng model GPT-4o. Claude.ai là chatbot dùng Claude Sonnet 4.6. Người dùng gõ câu hỏi, chatbot gọi LLM, hiển thị response. Chatbot có thêm memory cuộc hội thoại, nhưng vẫn chỉ trả lời trong phạm vi text.
AI Agent là LLM cộng thêm tools và vòng lặp hành động. Agent có thể dùng Bash (chạy lệnh), Read/Write (đọc/ghi file), gọi API, dispatch sub-agent. Agent chạy vòng lặp Perceive → Plan → Act → Learn cho đến khi đạt mục tiêu. Khi nhiều agent phối hợp thông qua orchestrator, đó là Agentic AI. Claude Code là ví dụ: dùng Claude Sonnet 4.6 làm LLM nền, thêm terminal tools, và khả năng dispatch sub-agents qua Task tool.
Giá LLM: Chi Phí Thực Tế Là Bao Nhiêu?
Token đầu ra (output) luôn đắt hơn token đầu vào (input) từ 3 đến 5 lần. Với Claude Sonnet 4.6, bạn trả $3 cho 1M input và $15 cho 1M output, chênh 5 lần. Hiểu điều này quan trọng vì phần lớn chi phí thực sự đến từ output khi bạn yêu cầu AI sinh code hoặc viết bài dài.
Chi phí thực tế từ ongboit.com: Mình dùng Claude Sonnet 4.6 cho workflow sản xuất nội dung + debugging code + orchestration sub-agents tại ongboit.com, tốn khoảng $180-220/tháng API cho 15+ Claude Code skills + automation pipeline. Trong đó, 65% chi phí là output token (Sonnet trả lời dài) và 35% là input (đọc code repo + context). Với developer cá nhân viết script nhỏ, chi phí có thể chỉ $5-15/tháng.
Ví dụ cụ thể chi phí viết một bài blog tiếng Việt 1,500 chữ với Claude Code: – Input: ~5,000 token (prompt + brief + research data) × $3/1M = $0.015 – Output: ~3,500 token tiếng Việt (gấp 2x token tiếng Anh tương đương) × $15/1M = $0.052 – Tổng: ~$0.067/bài. Chạy 100 bài/tháng hết khoảng $6.70.
Switch Haiku vs Sonnet trong thực tế: Mình thử tách workflow thành hai tầng: sub-agent đơn giản (file reading, lint check, format validation) dùng Claude Haiku 4.5 ($1/$5), còn orchestrator và task cần reasoning dùng Sonnet 4.6 ($3/$15). Kết quả tiết kiệm ~3x chi phí sub-agent task mà chất lượng vẫn đủ, Haiku đủ thông minh cho task rule-based, chỉ Sonnet cần cho plan phức tạp. Nếu bạn muốn tối ưu thêm, đọc mẹo tiết kiệm token.
LLM Dùng Trong Lập Trình: Claude Code Là Ví Dụ
Claude Code là AI Agent dùng Claude Sonnet 4.6 làm LLM nền, chạy trực tiếp trong terminal với khả năng đọc/ghi file, chạy bash, và dispatch sub-agents qua Task tool. Đây là cách LLM chuyển từ “trợ lý chat” thành “developer tool production” không cần LangChain hay framework Python phức tạp.
Workflow thực tế mình dùng Claude Code hàng ngày tại ongboit.com:
1. Viết code mới: Mô tả feature → Claude đọc codebase, hiểu pattern hiện có, viết code khớp style. LLM quyết định dùng hàm nào, Claude Code thực thi đọc file và ghi file.
2. Debug production: Paste error log → Claude phân tích stack trace, tìm file liên quan, đề xuất fix. Nếu cần chạy test để xác nhận, Claude Code chạy bash ngay trong terminal.
3. Refactor lớn: Dispatch 3-5 sub-agents qua Task tool, mỗi sub-agent xử lý một phần của codebase song song. Sub-agent đơn giản dùng Haiku 4.5, orchestrator dùng Sonnet 4.6. Kết quả tổng hợp về main agent.
Điểm khác biệt giữa Claude Code và gọi LLM API trực tiếp: Claude Code có tool access mặc định (Bash, Read, Write, Task), có permission mode để kiểm soát hành động, và có hooks để tự động hóa workflow. Bạn không cần code retry logic, context management, hay tool dispatching, Anthropic đã xây hết vào trong Claude Code.
LLM Được Ứng Dụng Như Thế Nào Tại Việt Nam?
Thị trường ứng dụng LLM tại Việt Nam phát triển nhanh, tập trung vào ba nhóm: doanh nghiệp lớn tự xây, startup tích hợp API, và developer cá nhân build tool. Khác với thị trường quốc tế, Việt Nam có đặc thù là tiếng Việt tốn gấp 2 lần token so với tiếng Anh, làm chi phí thực tế cao hơn và đòi hỏi lựa chọn model kỹ hơn.
FPT AI Engage là chatbot chăm sóc khách hàng của FPT dùng LLM kết hợp fine-tuning tiếng Việt để xử lý hàng nghìn ticket/ngày cho ngân hàng, bảo hiểm, và viễn thông. VNPT Smartbot tích hợp vào hệ thống hành chính công, giúp công dân hỏi thủ tục giấy tờ 24/7. Cả hai đều dùng kiến trúc RAG để cập nhật chính sách mà không cần retrain model từ đầu mỗi lần luật thay đổi.
Với developer cá nhân và startup, workflow phổ biến nhất là: Claude API hoặc OpenAI API + RAG (LangChain hoặc LlamaIndex) + vector database (Pinecone, Qdrant). Chi phí tối thiểu để build một chatbot tiếng Việt cho 100 người dùng/ngày vào khoảng $50-200/tháng, tùy context window và số lượt gọi API.
LLM Có Ưu Điểm Và Nhược Điểm Gì?
LLM mạnh ở tính linh hoạt và khả năng tổng quát hóa, nhưng có điểm yếu cố hữu là hallucination, thiếu domain expertise chuyên sâu, và chi phí training cao. Biết rõ ưu và nhược điểm giúp bạn chọn đúng use case thay vì kỳ vọng sai.
Ưu điểm nổi bật:
- Đa nhiệm không cần retrain: Cùng một LLM viết code, dịch thuật, phân tích văn bản, và chat hỗ trợ mà không cần train lại từ đầu.
- Zero-shot/few-shot learning: LLM hiểu task mới chỉ qua vài ví dụ trong prompt mà không cần finetune, nhờ in-context learning học được từ pretraining.
- Tổng hợp kiến thức đa domain: Từ pháp lý, y tế, đến kỹ thuật, LLM tổng hợp thông tin từ nhiều lĩnh vực mà một chuyên gia đơn lẻ không bao phủ được.
Nhược điểm cần biết:
- Hallucination: LLM tạo ra thông tin sai nhưng trình bày tự tin. Tỷ lệ hallucination của model tốt nhất vẫn ở mức 3-8% với câu hỏi factual theo benchmark TruthfulQA. Không dùng LLM cho task cần độ chính xác 100% về sự kiện mà không có RAG hoặc verification layer.
- Knowledge cutoff: LLM bị giới hạn bởi thời điểm kết thúc dữ liệu train. Claude Sonnet 4.6 có cutoff tháng 8/2025, hỏi về sự kiện sau đó sẽ không biết.
- Chi phí phần cứng: Train GPT-4 ước tính tốn $50-100M USD. Self-host model trên 70B params cần ít nhất 4 GPU A100 80GB.
LLM Sẽ Phát Triển Theo Hướng Nào Trong Tương Lai?
Ba xu hướng lớn định hình LLM 2026-2027: multimodality (xử lý nhiều dạng media), specialization (model chuyên ngành), và agentic reasoning (LLM tự lập kế hoạch và thực thi tác vụ phức tạp). Những xu hướng này thay đổi cách developer tích hợp AI vào sản phẩm.
Multimodality: LLM không còn chỉ xử lý text. GPT-5.4, Gemini 3.1 Pro, và Claude Opus 4.7 đều xử lý được text, hình ảnh, audio, và video trong cùng một prompt. Xu hướng tiếp theo là real-time multimodal: nhận input video stream và trả về action ngay lập tức, mở khả năng cho robot, xe tự lái, và AR/VR assistant.
Specialization: Thay vì model chung, thị trường chuyển sang model fine-tuned cho domain cụ thể: y tế (Med-PaLM 2 đạt điểm Expert trên USMLE), pháp lý (Harvey AI cho luật sư), tài chính (Bloomberg GPT). Mô hình Mixture-of-Experts (MoE) như Kimi K2.5 (1T params, 384 experts) cho phép một model “giả vờ” là nhiều specialist mà không tốn compute cho toàn bộ params mỗi inference.
Agentic Reasoning: LLM kết hợp reasoning chain dài + tool use + self-reflection đang thay thế workflow pipeline truyền thống. Claude Opus 4.7 đạt 80.8% SWE-bench, nghĩa là tự resolve được 4/5 bug GitHub từ issue description mà không cần hướng dẫn từng bước. Xu hướng này đẩy LLM từ “trợ lý trả lời câu hỏi” thành “agent tự chạy workflow end-to-end” với sự giám sát tối thiểu của con người.
Câu Hỏi Thường Gặp
LLM là viết tắt của từ gì?
Trong AI, LLM là viết tắt của Large Language Model (mô hình ngôn ngữ lớn). Trong luật, LL.M. (có hai dấu chấm) là viết tắt của Legum Magister (tiếng Latinh), nghĩa là Master of Laws (Thạc sĩ Luật). Hai nghĩa hoàn toàn khác nhau nhưng viết tắt tương tự nên Google thường trộn kết quả. Khi đọc bài viết về AI mà thấy LLM, luôn hiểu là Large Language Model.
LLM và ChatGPT khác nhau thế nào?
LLM là công nghệ nền, ChatGPT là sản phẩm chatbot dùng LLM. ChatGPT dùng model GPT-4o (một LLM do OpenAI phát triển) cộng với giao diện chat, session management, và các plugin. Tương tự, Claude.ai là chatbot dùng Claude Sonnet 4.6 làm LLM nền. Một LLM có thể phục vụ nhiều chatbot khác nhau, và một chatbot có thể chuyển đổi giữa các LLM.
Nên chọn LLM nào cho developer?
Phụ thuộc workflow: Claude Opus 4.7 hoặc GPT-5.4 cho task khó nhất, Sonnet 4.6 hoặc GPT-5.3 Codex cho code production, Haiku 4.5 hoặc o3-mini cho sub-agent reasoning, DeepSeek V3.2 hoặc Qwen 3.5 cho khối lượng lớn. Nếu làm Claude Code hay agentic workflow phức tạp, Sonnet 4.6 là mặc định.
Nếu cần scale với chi phí cực thấp (chatbot khách hàng, content moderation, batch processing), Qwen 3.5 rẻ gấp 50 lần so với Opus 4.7. Grok 4.1 là bất ngờ 2026 với context 2M + giá frontier rẻ nhất ($0.20/$0.50).
Llama 4 Scout phù hợp khi cần context 10M cho tài liệu siêu dài hoặc self-host privacy (Gemini 3 Pro đã bị discontinued 26/3/2026, Gemini 3.1 Pro thay thế chỉ có 1M context).
LLM có thay thế lập trình viên không?
Không thay thế, nhưng thay đổi cách làm việc căn bản. Theo khảo sát Stack Overflow 2025 (n=33,662), 84% developer dùng AI tools hàng ngày nhưng chỉ 3% tin AI có thể thay thế họ. LLM giỏi sinh code theo pattern có sẵn, debug syntax, refactor đơn giản. LLM kém trong hiểu business context, đưa ra quyết định kiến trúc dài hạn, và giao tiếp với stakeholder. Developer dùng LLM làm công cụ, không phải thay thế.
LLM open source là gì?
LLM có weights công khai để cộng đồng tải về, chạy local, hoặc fine-tune tự do. Các model open-weights mới nhất 2026: Gemma 4 (Google, MoE 26B, chỉ 14GB RAM, chạy 85 tok/s trên hardware consumer), Llama 4 Scout (Meta, context 10M), DeepSeek V3.2 (MIT license), Qwen 3.5 (Alibaba), Kimi K2.5 (Moonshot, 1T params MoE).
Ưu điểm: không tốn phí API, chạy offline, kiểm soát dữ liệu privacy. Nhược điểm: cần hardware GPU 24GB+ VRAM cho model lớn, chất lượng flagship closed-source (Opus 4.7, GPT-5.4, Grok 4.1) vẫn dẫn đầu trên benchmark khó nhất.
Phù hợp cho startup muốn tự host, task yêu cầu privacy cao, hoặc workflow batch chi phí cực thấp.
Tại sao có nhiều LLM mới ra liên tục?
Thị trường LLM đang trong giai đoạn cạnh tranh gay gắt về giá và chất lượng. Từ 2024 đến 2026, giá API LLM đã giảm khoảng 80% trung bình. Riêng đầu 2026: Anthropic ra Opus 4.7 (16/4), Google ra Gemini 3.1 Pro (Feb), OpenAI ra GPT-5.4 (Mar), Moonshot ra Kimi K2.5, Zhipu ra GLM-5.1, DeepSeek ra V3.2, Qwen ra 3.5, Google ra Gemma 4.
Tốc độ ra model mới khoảng 1 model/tuần buộc cả thị trường cạnh tranh. Gemini 3 Pro Preview đã bị discontinued 26/3/2026 chỉ sau vài tháng để thay bằng 3.1 Pro.
Developer nên xem LLM như thị trường hàng hóa đang trưởng thành: đừng lock-in một model duy nhất, thiết kế workflow có thể swap model (LiteLLM, OpenRouter giúp điều này).
Code with Claude London 5/2026: 3 Cập Nhật LLM Cho Developer
Anthropic tổ chức sự kiện Code with Claude tại London ngày 19-20 tháng 5 năm 2026, sự kiện thường niên dành cho developer cộng product builder. Ba cập nhật quan trọng cho developer làm việc với LLM trong giai đoạn 2026-2027.
1. Karpathy Gia Nhập Anthropic Ngay Trước Sự Kiện
Andrej Karpathy, cựu founding member OpenAI và là người tạo ra thuật ngữ vibe coding, chính thức gia nhập đội ngũ Anthropic trước thềm Code with Claude London. Karpathy là nhà nghiên cứu hàng đầu thế giới về kiến trúc Transformer và LLM, từng dẫn dắt team Computer Vision tại Tesla. Sự gia nhập này là tín hiệu mạnh về hướng đi mới của Anthropic: đẩy mạnh trải nghiệm developer-first cho Claude Code và sản phẩm Cowork. Với developer Việt, news này có ý nghĩa thực tế là sẽ có thêm tutorial dài hơi từ chính Karpathy về cách dùng LLM hiệu quả trong sáu đến mười hai tháng tới.
2. Cowork Được Build Hoàn Toàn Bằng Claude Code Via Vibe Coding
Boris Cherny, creator của Claude Code, xác nhận trên sân khấu sự kiện rằng toàn bộ phần mềm Claude Cowork được Claude Code tự generate qua pattern vibe coding trong dưới 2 tuần. Theo Cherny: “Default isn’t ‘I’m going to prompt Claude’ anymore, default is now ‘I’m going to have Claude prompt itself'”. Đây là proof point quan trọng cho developer đang cân nhắc dùng LLM cho production workflow thực tế. Khi chính đội ngũ Anthropic dùng LLM để build sản phẩm thương mại serve hàng triệu user, lập trình viên thông thường có cơ sở vững chắc để áp dụng pattern này vào dự án của mình. Vibe coding pattern dựa trên reasoning chain dài kết hợp tool use và self-reflection, không phải là magic mà là kỹ thuật cần học.
3. Cowork Pricing 2026: Bao Trong Pro $17-20/Tháng
Anthropic công bố Cowork không có gói riêng mà bao luôn trong Claude Pro với giá $17-20/tháng (annual billing) hoặc Claude Max $100/tháng cho power user. So với HubSpot CRM $50/tháng, Mailchimp $40/tháng, Zapier $30/tháng, một thuê bao Claude Pro $20 thay thế được nhiều SaaS tool cho developer làm việc với LLM. Với 11 plugin chính thức từ Anthropic (sales, finance, legal, marketing) cộng integration native với Microsoft 365, Google Workspace, Slack, Jira, đây là giai đoạn LLM chuyển từ công cụ chuyên biệt sang nền tảng tích hợp đa dụng.
Kết Luận
LLM là nền tảng công nghệ của mọi trợ lý AI hiện đại, và khác hoàn toàn với LL.M. trong luật. Khi nói về AI, LLM luôn nghĩa là Large Language Model, công nghệ dự đoán token dựa trên xác suất học từ dữ liệu văn bản khổng lồ.
Với developer năm 2026, lựa chọn nhiều hơn hẳn so với 2024: 16 model mới nhất chia 4 tầng rõ rệt. Claude Opus 4.7 (ra 16/4/2026) hay GPT-5.4 cho reasoning khó, Sonnet 4.6 hay GPT-5.3 Codex cho workflow code production, Haiku 4.5 hay DeepSeek V3.2 cho sub-agent tiết kiệm, Qwen 3.5 hay Gemma 4 cho khối lượng lớn hoặc self-host. Grok 4.1 là bất ngờ lớn nhất 2026 với context 2M + giá frontier rẻ nhất thị trường.
Chênh lệch giá giữa model lên đến 50 lần (từ $0.10 đến $5/1M input), và tokenizer làm tiếng Việt tốn gấp 2 lần token so với tiếng Anh, hai yếu tố này quyết định chi phí thực tế nhiều hơn là chất lượng model. Đọc tiếp token là gì để hiểu cách tokenizer ảnh hưởng bill API, và context window là gì để biết giới hạn bộ nhớ của từng model.
Kiến thức nền này sẽ giúp bạn học Claude Code hiệu quả hơn. Xem lộ trình 8 levels để biết bước tiếp theo.