n8n AI Agent: Xây Workflow Thông Minh Không Cần Code (2026)
Bạn đã nghe về AI agent, đã thử một vài automation tool, đã biết n8n là gì, và đang nghĩ: “Kết hợp n8n với AI agent thì làm thế nào?”
Câu trả lời ngắn: khả thi hoàn toàn, không cần code, và mình đã chạy production trên hệ thống xử lý 200 email mỗi ngày trong 3 tháng qua. 51% doanh nghiệp toàn cầu đang triển khai AI agent trong môi trường production theo khảo sát LangChain 2025, và n8n đang là platform phổ biến nhất cho use case này nhờ 6,500+ template AI trong cộng đồng.
Nhưng hầu hết tutorial bỏ qua 4 thứ quan trọng: chi phí thực tế của từng LLM, cách bộ nhớ hoạt động giữa các session, tích hợp MCP mới nhất, và khi nào bạn KHÔNG nên dùng n8n. Bài này cover đủ cả 4.
TL;DR
- n8n AI agent = workflow có thể “suy nghĩ” và tự quyết định bước tiếp theo, khác với automation chạy theo flow cố định
- Chọn Gemini Flash 2.0 nếu ưu tiên tốc độ và giá rẻ; Claude Sonnet 4.6 nếu cần chất lượng output cao
- Bộ nhớ mặc định chỉ tồn tại trong 1 session, cần PostgreSQL để lưu lịch sử lâu dài
- MCP (Model Context Protocol) cho phép Claude Code hoặc Cursor trigger n8n workflow trực tiếp
- Chi phí thực tế: $13-30/tháng cho 500 runs/ngày (infra + LLM API)

AI Agent Trong n8n Là Gì? (Và Khác Gì Automation Thông Thường?)
n8n AI agent là workflow sử dụng LLM để tự quyết định hành động tiếp theo thay vì chạy theo chuỗi bước cố định. Điểm khác biệt cốt lõi: agent có thể lặp lại, xử lý kết quả không mong đợi, và chọn tool phù hợp từ danh sách. Automation thông thường chỉ chạy tuần tự từ A đến Z, không có khả năng tự điều chỉnh.
n8n implement AI agent theo chuẩn ReAct (Reasoning + Acting): mỗi bước, LLM nhận context, quyết định có cần dùng tool không, gọi tool nếu cần, đọc kết quả, rồi quyết định tiếp theo. Vòng lặp này chạy cho đến khi agent đủ thông tin để trả lời, hoặc đạt giới hạn iteration.
| Tiêu chí | Automation Thông Thường | n8n AI Agent |
|---|---|---|
| Luồng xử lý | Fixed steps A → B → C | Reasoning loop, tự quyết định |
| Xử lý ngoại lệ | Crash hoặc error path cố định | LLM tự adjust theo context |
| Bộ nhớ | Stateless per run | Tùy cấu hình (session / permanent) |
| Tool selection | Hard-coded | Chọn động từ danh sách |
| Best for | ETL, data pipeline, notification | Q&A, classification, multi-step decision |
Ví dụ thực tế: một workflow “nhận email → forward lên Slack” là automation thông thường. Còn “nhận email → đọc nội dung → quyết định reply ngay hoặc escalate lên manager → ghi nhớ context từng khách hàng” là AI agent. n8n xử lý được trường hợp thứ hai mà không cần viết một dòng code nào.
Đây cũng là lý do mình bắt đầu từ việc tìm hiểu n8n cơ bản rồi build AI agent ngay trên nền đó thay vì chuyển sang platform khác.
n8n Hỗ Trợ Những LLM Nào? Chi Phí Thực Tế Là Bao Nhiêu?
n8n hỗ trợ 30+ LLM provider thông qua LangChain integration: OpenAI, Google Gemini, Anthropic Claude, Groq, Mistral, Azure OpenAI, Ollama (local), và nhiều hơn. Nhưng “hỗ trợ” không đồng nghĩa với “phù hợp cho mọi use case”. Áp dụng Ngưỡng Quyết Định (framework chọn LLM: nếu giá trị nhận lại từ model premium không đủ bù chi phí cao hơn, xuống model rẻ hơn).
Mình đã test 5 option phổ biến nhất trên cùng 1 workflow n8n với prompt 500 tokens, chạy trên Hetzner CX21 ($7/tháng):
| LLM | Cost/1K tokens (input+output) | Latency | Chất lượng | Best for |
|---|---|---|---|---|
| GPT-4o | $0.0025 + $0.010 | 3-8s | Cao nhất | Complex reasoning, code gen |
| Gemini Flash 2.0 | $0.000075 + $0.0003 | 1-3s | Tốt | Speed + cost, most use cases |
| Claude Sonnet 4.6 | $0.003 + $0.015 | 2-5s | Rất cao | Long context, nuanced output |
| Groq Llama3-70b | $0.00059 + $0.00079 | 0.5-1.5s | Khá | Low latency, simple classification |
| Ollama (local) | $0 | 5-30s | Tùy model | Privacy, zero API cost |
Ở mức 500 runs/ngày với 500 tokens/run: Gemini Flash tốn khoảng $0.19/ngày ($5.7/tháng), GPT-4o tốn khoảng $6.25/ngày ($187.5/tháng). Chênh nhau 33 lần cho cùng khối lượng công việc. Với task phân loại email đơn giản, mình không thấy lý do phải dùng GPT-4o.
Ollama caveat: free và chạy hoàn toàn local, nhưng chậm hơn 5-30x so với cloud provider và cần GPU để đạt chất lượng tốt. Phù hợp cho môi trường development và dữ liệu nhạy cảm, không phù hợp cho production agent cần respond trong 1-2 giây.
Làm Thế Nào Để Tạo AI Agent Đầu Tiên Với n8n?
Tạo AI agent đầu tiên với n8n mất khoảng 15-20 phút qua 5 bước: Chat Trigger → AI Agent node → kết nối LLM → test cơ bản → thêm tool đầu tiên. Không cần viết một dòng code nào. Kết quả cuối: 1 agent nhận tin nhắn từ người dùng, gọi API external nếu cần, và trả về câu trả lời tự nhiên.
Phần này giả định bạn đã có n8n đang chạy. Nếu chưa, setup theo hướng dẫn tự host n8n trên VPS bằng Docker hoặc dùng Coolify để deploy nhanh hơn trong khoảng 15 phút.
Step 1: Tạo workflow mới, thêm Chat Trigger
Trong n8n, tạo workflow mới. Thêm node “Chat Trigger” (tìm trong node panel, category “Triggers”). Node này tạo một webhook URL và giao diện chat để test. Cấu hình:
- Authentication: none (cho môi trường test)
- Mode: Webhook
Step 2: Thêm và cấu hình AI Agent node
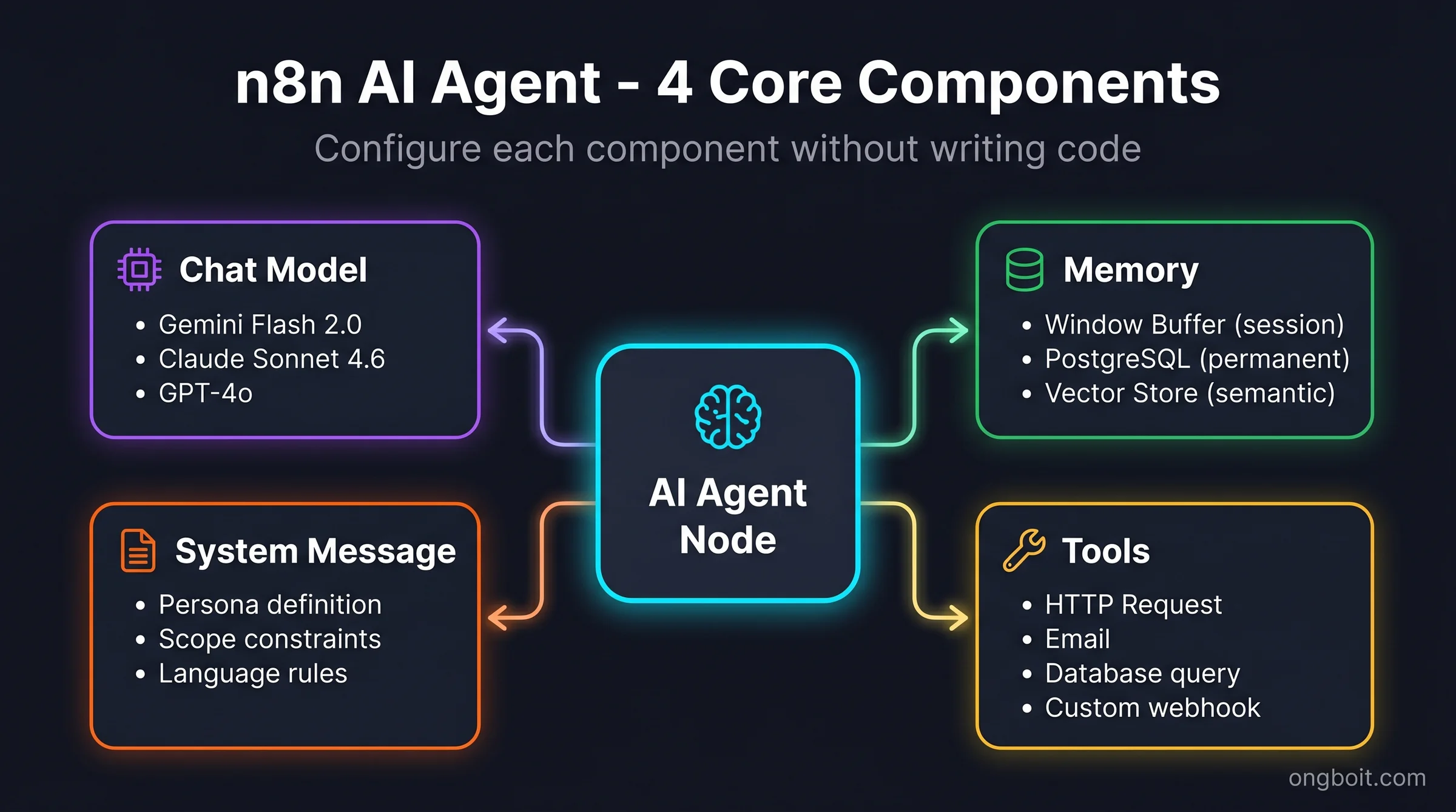
Thêm node “AI Agent” kết nối từ Chat Trigger. Node này có 4 thành phần cần cấu hình:
Chat Model: kết nối LLM. Click “+” bên cạnh “Chat Model”, chọn provider. Ví dụ với Google Gemini:
- Credential: thêm API key từ Google AI Studio (miễn phí)
- Model:
gemini-2.0-flash-exp
Memory: để trống trước (dùng Window Buffer Memory mặc định, session only).
System Message: định nghĩa persona và giới hạn hành vi của agent:
Bạn là assistant hỗ trợ kỹ thuật cho ongboit.com.
Trả lời bằng tiếng Việt, ngắn gọn, dưới 200 từ.
Chỉ trả lời các câu hỏi liên quan đến lập trình, DevOps, và AI tools.
Nếu câu hỏi ngoài phạm vi, từ chối lịch sự và gợi ý tìm nguồn khác.Tools: để trống trước, thêm sau khi test cơ bản xong.
Step 3: Test agent cơ bản
Kết nối Chat Trigger → AI Agent → End. Kích hoạt workflow (toggle “Active” ở góc phải trên). Mở chat window qua URL mà n8n tạo ra (dạng your-domain/webhook/[id]/chat). Gõ câu hỏi thử.
Nếu agent trả lời được, bạn đã có AI agent chạy. Latency thường 1-5 giây tùy LLM và độ dài prompt.
Step 4: Thêm tool đầu tiên
Tool biến agent từ “chatbot trả lời câu hỏi” thành “agent thực sự làm việc”. Trong phần Tools của AI Agent node, click “+”, thêm “HTTP Request” node với cấu hình sau (ví dụ: tool check thời tiết):
{
"name": "get_weather",
"description": "Lấy thông tin thời tiết hiện tại cho một thành phố",
"url": "https://api.openweathermap.org/data/2.5/weather",
"method": "GET",
"queryParameters": {
"q": "={{ $fromAI('city', 'tên thành phố cần check thời tiết') }}",
"appid": "YOUR_OPENWEATHER_API_KEY",
"units": "metric",
"lang": "vi"
}
}Agent sẽ tự gọi tool này khi user hỏi về thời tiết, parse kết quả JSON, và trả lời bằng tiếng Việt tự nhiên mà không cần bạn viết thêm bất kỳ code parse nào.
Step 5: Thêm Respond to Webhook
Thêm node “Respond to Webhook” sau AI Agent, set response body = output của AI Agent node. Bước này cần thiết để chat interface hiển thị đúng response.
Bộ Nhớ Trong n8n AI Agent Hoạt Động Như Thế Nào? (3 Kiểu Memory)
Đây là điểm mà hầu hết tutorial bỏ qua, và cũng là lý do nhiều người phàn nàn trên Reddit: “agent không nhớ gì cả sau khi tắt workflow”. Mặc định, n8n AI Agent dùng Window Buffer Memory, chỉ giữ lịch sử trong session hiện tại và reset sau khi conversation kết thúc.
Mình đã dùng cả 3 loại memory trên production, dưới đây là so sánh thực tế:
| Memory Type | Persistence | Best For | Chi phí ước tính | Setup |
|---|---|---|---|---|
| Window Buffer | Session only (reset khi workflow end) | Chatbot demo, Q&A đơn lẻ | $0 | Built-in |
| PostgreSQL Chat Memory | Vĩnh viễn, lưu vào DB | Customer support, multi-turn | $0-10/tháng (Supabase free tier) | 15-30 phút |
| Vector Store (Pinecone/Qdrant) | Semantic, tìm kiếm theo nghĩa | RAG, knowledge base lớn | $0-70/tháng | 1-2 giờ |
Mình đã build agent phân loại và xử lý email support với PostgreSQL Chat Memory trên Supabase. Workflow chạy khoảng 200 email mỗi ngày, agent nhớ context từng khách hàng qua các email khác nhau ở các ngày khác nhau. Chi phí PostgreSQL: $3/tháng trên Supabase free tier. Kết quả: từ 2 giờ xử lý email mỗi ngày xuống còn 15 phút review và approve.
Cách thêm PostgreSQL Memory: Trong phần Memory của AI Agent node, chọn “PostgreSQL Chat Memory”. Thêm credential kết nối PostgreSQL, đặt Session ID = {{ $('Chat Trigger').item.json.sessionId }} để mỗi conversation riêng biệt. n8n tự tạo bảng lưu trữ:
-- n8n auto-creates this table on first run
CREATE TABLE IF NOT EXISTS n8n_chat_histories (
id SERIAL PRIMARY KEY,
session_id VARCHAR(255) NOT NULL,
message JSONB NOT NULL,
created_at TIMESTAMP DEFAULT NOW()
);
CREATE INDEX IF NOT EXISTS idx_session_id ON n8n_chat_histories(session_id);Vector Store (RAG) phù hợp khi agent cần tra cứu knowledge base theo ngữ nghĩa: ví dụ, agent hỗ trợ documentation với hàng nghìn bài viết. Pinecone có free tier 1 index. Qdrant có thể self-host miễn phí trên cùng VPS với n8n.
MCP + n8n: Khi AI Agent Có Thể Dùng Mọi Tool
MCP (Model Context Protocol) là chuẩn mở cho phép LLM client kết nối với bất kỳ tool hoặc server nào theo interface thống nhất. n8n implement MCP từ tháng 4/2025 qua 2 node: MCP Server Trigger (n8n đóng vai server) và MCP Client Tool (n8n gọi MCP server khác).MCP biến n8n từ automation tool thành AI tool hub. Thay vì mỗi LLM cần integration riêng, MCP Server Trigger cho phép bất kỳ MCP-compatible client nào (Claude Code, Cursor, hay Windsurf) trigger cùng workflow. 1 workflow, nhiều AI clients dùng chung.
Ví dụ thực tế mình đang dùng: Claude Code trên laptop kết nối đến n8n qua MCP. Khi cần trigger CI/CD hoặc gửi notification, Claude Code gọi n8n MCP endpoint, n8n xử lý và trả kết quả về. Xem chi tiết setup trong bài về tích hợp Claude Code qua MCP.
Setup MCP Server trong n8n:
- Thêm node “MCP Server Trigger” vào workflow mới
- n8n tạo URL dạng:
https://your-n8n.com/mcp/[workflow-id] - Định nghĩa các tools bạn muốn expose (mỗi tool là 1 n8n node hoặc sub-workflow)
- Trong MCP client (ví dụ Claude Code), thêm vào
.mcp.json:
{
"mcpServers": {
"n8n-tools": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-http-proxy"],
"env": {
"SERVER_URL": "https://your-n8n.com/mcp/[workflow-id]",
"AUTH_HEADER": "Bearer YOUR_N8N_API_KEY"
}
}
}
}Production consideration: MCP endpoint cần auth (Bearer token). n8n chưa có built-in rate limiting cho MCP endpoint, cần cấu hình rate limit ở reverse proxy (nginx hoặc Caddy) phía trước n8n nếu expose public.
Khi Nào Cần Multi-Agent Thay Vì 1 n8n Agent?
Khi use case phức tạp, 1 agent đơn lẻ thường không đủ: context window overflow với task dài, cần 2 LLM khác nhau cho 2 sub-task, hoặc cần parallel processing để giảm latency. Trước khi đi multi-agent, áp dụng Ngưỡng Quyết Định: nếu 1 agent với GPT-4o (128K context window) xử lý được, đừng thêm complexity không cần thiết.
Pattern phổ biến nhất trong n8n là Orchestrator-Specialist:
- 1 orchestrator agent nhận input từ user và quyết định route
- N specialist agents, mỗi cái phụ trách 1 domain (research, writing, review, coding)
- Orchestrator collect kết quả từ các specialist, synthesize và trả về
Implement trong n8n: orchestrator AI Agent node có tool “Execute Workflow” để gọi sub-workflows. Mỗi sub-workflow là 1 specialist agent chạy độc lập.
User input → Orchestrator Agent
|
+---------+---------+
| |
[Execute: Research] [Execute: Writer]
| |
+---------+---------+
|
Orchestrator tổng hợp → Final outputDùng n8n monitoring để track execution time, token cost, và error rate từng agent trong chain. Với multi-agent, chi phí LLM tăng tuyến tính theo số agent và số round-trip.
Honest caveat: Multi-agent tăng debugging difficulty đáng kể. Khi 1 agent trong chain fail, trace back root cause tốn nhiều thời gian hơn single-agent. Chỉ dùng khi single-agent thực sự không đủ capacity.
Khi Nào KHÔNG Nên Dùng n8n Cho AI Agent?
n8n AI agent giải quyết được nhiều bài toán, nhưng không phải tất cả. Ngưỡng Quyết Định: nếu bạn phải viết >50 dòng code trong “Code” node để workaround n8n limitation, thì viết code trực tiếp từ đầu có khi nhanh hơn và bảo trì dễ hơn.
3 trường hợp rõ ràng nên bỏ qua n8n:
1. Cần fine-tuning hoặc custom model training n8n chỉ call LLM API, không support fine-tuning. Nếu use case cần model được train trên data riêng của bạn, phải dùng Python cùng LangChain hoặc Hugging Face trực tiếp.
2. Sub-millisecond latency cho production API n8n có overhead từ workflow engine: trung bình thêm 200-500ms so với gọi LLM API trực tiếp. Với các hệ thống cần latency cực thấp như trading hay real-time notification, n8n không phải lựa chọn đúng. Các lỗi liên quan đến timeout và performance được cover trong bài xử lý lỗi trong n8n.
3. Complex stateful logic cần custom memory architecture Window Buffer và PostgreSQL Memory của n8n có hạn chế về cách lưu trữ và retrieve state. Nếu cần memory hierarchy phức tạp (episodic + semantic + procedural layers như trong các AI agent system nghiên cứu), implement trong Python sẽ linh hoạt hơn nhiều.
Dấu hiệu cụ thể bạn đang cố workaround n8n: bạn tạo hơn 5 sub-workflow chỉ để handle edge cases của 1 flow đơn giản, hoặc bạn spend hơn 1 ngày debug 1 bug mà code thuần sẽ fix trong 1 giờ. Đó là lúc Ngưỡng Quyết Định nói “chuyển sang code”.
AI Agent Trong n8n Liên Kết Với Phần Còn Lại Của Ecosystem Ra Sao?
Phần này giúp bạn hiểu rõ vị trí của AI agent trong toàn bộ hệ sinh thái n8n và cách nó kết nối với các thành phần khác để xây dựng pipeline sản xuất hoàn chỉnh. Hiểu được kiến trúc tổng thể giúp đội nhóm phát triển sản phẩm thiết kế hệ thống hợp lý ngay từ đầu, tránh việc phải refactor sau khi đã đầu tư công sức vào các pattern không phù hợp với cơ chế hoạt động thực tế.
Một, Khái Niệm Nền Tảng Là LLM
Trước khi xây dựng AI agent trong n8n, người mới nên nắm vững khái niệm cơ bản về LLM (Large Language Model) và cách chúng hoạt động. AI agent về bản chất là một LLM được trang bị thêm khả năng dùng tool và vòng lặp tự suy luận. Không hiểu LLM thì khó debug khi agent đưa ra quyết định không mong muốn hoặc lặp đi lặp lại các sai lầm tương tự. Đầu tư 2-3 ngày đọc kỹ về cơ chế token prediction, temperature, context window là khoản đầu tư xứng đáng cho mọi team bắt đầu xây dựng AI agent quy mô lớn.
Hai, So Sánh Với Khái Niệm AI Agent Tổng Quát
AI agent trong n8n là một dạng triển khai cụ thể của khái niệm AI agent nói chung. Sự khác biệt chính là agent trong n8n có giao diện kéo thả trực quan, dễ debug và sửa đổi mà không cần viết code phức tạp. Tuy nhiên đổi lại là độ linh hoạt thấp hơn so với agent code thủ công dùng các framework như LangChain hay AutoGPT. Hiểu rõ ưu nhược điểm của từng cách tiếp cận giúp đội ngũ chọn đúng công cụ cho từng tình huống cụ thể.
Ba, Khi Workflow Phức Tạp Cần Queue Mode
AI agent thường có thời gian xử lý dài do phụ thuộc vào latency của API LLM, từ vài giây đến vài phút mỗi execution. Khi triển khai trên môi trường sản xuất với nhiều agent chạy đồng thời, đội ngũ cần chuyển sang queue mode cho n8n để tránh tình trạng nghẽn cổ chai. Queue mode tách worker process riêng biệt cho phép nhiều agent chạy song song độc lập, đảm bảo throughput cao ngay cả khi từng agent riêng lẻ chậm do gọi API tốn thời gian. Đây là pattern bắt buộc cho mọi triển khai production có khối lượng công việc lớn.
Bốn, Chi Phí Vận Hành Cần Tính Toán Kỹ
AI agent tiêu thụ token API LLM nhiều hơn nhiều so với workflow thông thường, chi phí có thể tăng nhanh chóng nếu không kiểm soát chặt. Khi quyết định ngân sách cho dự án, đội ngũ nên đọc kỹ phân tích chi tiết về các gói n8n pricing để hiểu cấu trúc chi phí đầy đủ. Pattern khôn ngoan là bắt đầu với gói Cloud Starter để thử nghiệm, sau khi xác định được pattern thực tế mới quyết định chuyển sang gói cao hơn hoặc tự host trên VPS riêng.
Bài Học Vận Hành AI Agent Sau Sáu Tháng Production
Phần này tổng hợp ba bài học quan trọng nhất rút ra từ sáu tháng vận hành AI agent trên môi trường sản xuất cho nhiều dự án khách hàng. Đây là kinh nghiệm thực chiến đáng được chia sẻ cho người mới bắt đầu xây dựng AI agent cho doanh nghiệp.
Bài Học Một: Đừng Tin Tưởng Hoàn Toàn Vào Đầu Ra Của AI Agent
AI agent có thể đưa ra quyết định sai lầm bất ngờ ngay cả khi đã được kiểm thử kỹ lưỡng trong giai đoạn phát triển. Pattern bảo vệ tốt nhất là thêm bước kiểm tra của con người cho các quyết định quan trọng, đặc biệt là các quyết định liên quan đến tài chính hoặc dữ liệu khách hàng. Đầu tư thêm hai đến ba phút mỗi quyết định cho việc kiểm tra của con người tiết kiệm hàng giờ khắc phục hậu quả khi agent đưa ra quyết định sai lầm. Đặc biệt quan trọng trong giai đoạn ba tháng đầu vận hành khi agent chưa được tinh chỉnh đầy đủ cho từng tình huống cụ thể của doanh nghiệp.
Bài Học Hai: Logging Chi Tiết Từng Quyết Định Của Agent
Khác với workflow thông thường có flow rõ ràng, AI agent có nhiều bước suy luận trung gian khó debug nếu không có log chi tiết. Pattern khôn ngoan là logging từng prompt gửi đến LLM, từng response trả về, và từng tool call được agent thực hiện. Log này không chỉ giúp debug khi có sự cố mà còn là nguồn dữ liệu quý giá để cải thiện agent qua thời gian. Sau ba tháng vận hành, đội ngũ có thể phân tích log để xác định các pattern hoạt động kém hiệu quả và tinh chỉnh prompt hoặc thêm tool mới để cải thiện hiệu suất.
Bài Học Ba: Giới Hạn Số Bước Tối Đa Mỗi Agent Run
AI agent có thể bị mắc kẹt trong vòng lặp vô hạn nếu prompt không được thiết kế cẩn thận, tiêu tốn nhiều token và gây chi phí cao bất ngờ. Pattern bảo vệ tốt nhất là đặt giới hạn số bước tối đa cho mỗi agent run, thường mười đến hai mươi bước là đủ cho phần lớn tác vụ thông thường. Khi đạt đến giới hạn mà agent chưa hoàn thành tác vụ, hệ thống tự động dừng và thông báo cho đội ngũ kiểm tra. Cơ chế này đảm bảo chi phí trong tầm kiểm soát và phát hiện sớm các pattern hoạt động không hiệu quả cần được tinh chỉnh.
Câu Hỏi Thường Gặp
AI agent trong n8n khác gì so với automation thông thường?
Automation thông thường chạy theo bước cố định, không thể tự điều chỉnh khi gặp kết quả ngoài kịch bản. AI agent trong n8n dùng LLM để “suy nghĩ” qua từng bước, tự chọn tool phù hợp từ danh sách, và xử lý output không mong đợi. Khác biệt cốt lõi: agent có reasoning loop, automation thì không.
n8n AI agent có thể nhớ cuộc hội thoại trước không?
Có, nhưng phụ thuộc vào loại memory bạn cấu hình. Window Buffer Memory mặc định chỉ nhớ trong session hiện tại, reset sau khi workflow kết thúc. PostgreSQL Chat Memory lưu lịch sử vĩnh viễn vào database, agent nhớ ngay cả khi bạn tắt workflow rồi bật lại sau nhiều ngày. Cần cấu hình thêm, không tự động.
Mình cần tự host n8n để dùng AI agent không?
Không bắt buộc. n8n Cloud Starter (khoảng €24/tháng) hỗ trợ đầy đủ AI Agent node và các LLM integration. Nhưng self-host tiết kiệm 60-80% chi phí khi scale: Hetzner CX21 ($7/tháng) đủ cho 500 runs/ngày. Bù lại bạn phải tự quản lý update, backup, và uptime.
Chi phí chạy AI agent với n8n là bao nhiêu mỗi tháng?
Chia 2 phần: infra và LLM API. Infra: $0 nếu dùng n8n Cloud, $7-10/tháng nếu self-host trên Hetzner. LLM API: $0.02-0.15 mỗi lần chạy tùy model và độ dài prompt. Ví dụ thực tế: 500 runs/ngày với Gemini Flash = khoảng $5.7/tháng LLM + $7/tháng VPS = $13/tháng tổng.
n8n hỗ trợ LLM nào ngoài ChatGPT?
n8n hỗ trợ hơn 30 provider: Google Gemini, Anthropic Claude, Groq, Mistral, Perplexity, Azure OpenAI, AWS Bedrock, Cohere, và Ollama (để chạy model local). Với Ollama, bạn chạy model như Llama3 hay Phi-3 hoàn toàn trên server của mình, không cần API key, không mất phí per-token.
Kết Luận
n8n AI agent là lựa chọn thực tế nếu bạn cần: kết nối nhiều tool (email, calendar, database, HTTP API), không muốn viết code từ đầu, và workflow đủ phức tạp để cần LLM reasoning. Với 6,500+ template AI trong cộng đồng n8n và hỗ trợ 30+ LLM, điểm xuất phát không thiếu.
Một lời khuyên từ kinh nghiệm thực tế: bắt đầu với Gemini Flash 2.0 (free tier trên Google AI Studio) và Window Buffer Memory mặc định. Khi workflow chạy ổn định, nâng lên PostgreSQL Memory nếu cần lịch sử, và thêm MCP nếu muốn kết nối với Claude Code hoặc các AI client khác. Đừng over-engineer từ bước đầu tiên.
Bước tiếp theo cho người đang tự host n8n: xem n8n toolkit để tự động hóa monitoring, backup, và update n8n chỉ với 1 lệnh command.