Multi-Agent Research System: Top Anthropic Architecture
Tháng sáu năm 2025, Anthropic Engineering công bố bài “How We Built Our Multi-Agent Research System”, mô tả chi tiết kiến trúc backend production-grade đang vận hành tính năng deep research của Claude (tham khảo bài đăng gốc Anthropic Engineering). Bài đăng được cộng đồng kỹ thuật chia sẻ rộng với 3.247 lượt vote trên Hacker News, trở thành reference quan trọng cho mọi đội đang build research workflow tự động hoá. Bài đăng gốc bằng tiếng Anh, chưa có bản dịch tiếng Việt đủ chất lượng.
Bài viết này dịch và mở rộng kiến trúc multi-agent research system với context Việt Nam, phân tích cách Anthropic chia research task thành các subtask song song, mô tả pattern orchestrator-workers cụ thể trong production, đưa ra 5 lessons learned thực dụng cho đội xây dựng research workflow của riêng mình, và phần FAQ về implementation phổ biến.
TL;DR
- Multi-agent research system Anthropic: kiến trúc Orchestrator-Workers với 1 lead agent điều phối, 3-10 subagent chạy research song song.
- Workflow 4 phase: Plan (lead chia task), Research (worker fetch + analyze), Synthesize (lead gộp findings), Report (final output).
- Kết quả production multi-agent research system: trung bình 3-5 phút mỗi query deep research, nhanh hơn 3-5 lần so với single-shot Claude theo kiến trúc Anthropic Engineering.
- 5 lessons: dynamic subagent count, structured handoff format, parallel by default, cache reused fetches, fail gracefully khi 1 worker timeout.
Đọc Xây dựng AI agent hiệu quả 6 pattern trước để biết Orchestrator-Workers pattern. Bài này deep-dive vào case study production thực tế của Anthropic.
- Query đơn giản (fact lookup): không cần multi-agent, single Claude với web search là đủ.
- Query phức tạp đa khía cạnh (compare 5 product, analyze trend): multi-agent research giảm thời gian 3-5 lần.
- Query yêu cầu domain expertise (legal, medical): kết hợp specialized agent cho mỗi domain với reviewer agent.
- Internal knowledge base research: thay web fetch bằng RAG, giữ nguyên kiến trúc orchestrator-workers.
- Nguồn: Anthropic Engineering “How We Built Our Multi-Agent Research System” 13/6/2025.
- Hands-on: tác giả đã build prototype multi-agent research cho dự án khách hàng tháng 4/2026.
- Không cover: implementation deep research feature chi tiết của Claude.ai (closed-source).
- Freshness: kiến trúc Anthropic evolve nhanh, có thể đã update từ Jun 2025.
- Vendor influence: không có quan hệ thương mại.
Vì Sao Multi-Agent Research Tốt Hơn Single-Shot Claude?
Single-shot Claude khi nhận query research phải làm mọi thứ tuần tự: parse query, identify subtopics, fetch sources cho từng subtopic, đọc và summarize, gộp findings. Tất cả trong một context window duy nhất, dẫn tới ba vấn đề. Một, context window 200K token cạn nhanh khi fetch nhiều source. Hai, deep reasoning trên long context giảm chất lượng (lost in middle problem). Ba, latency tuyến tính theo số subtopic.
Multi-agent research system giải cả ba vấn đề. Orchestrator-Workers pattern: lead agent chia query thành 3-5 subtopic, dispatch subagent song song cho mỗi subtopic. Mỗi subagent có context window riêng dành 100 phần trăm cho subtopic của mình, không bị nhiễu bởi context khác. Latency tổng thể giảm 3-5 lần vì các subagent chạy parallel.
Đọc thêm về Parallelization pattern trong Xây dựng AI agent hiệu quả 6 pattern.
Kiến Trúc Multi-Agent Research System Anthropic Có Gì?
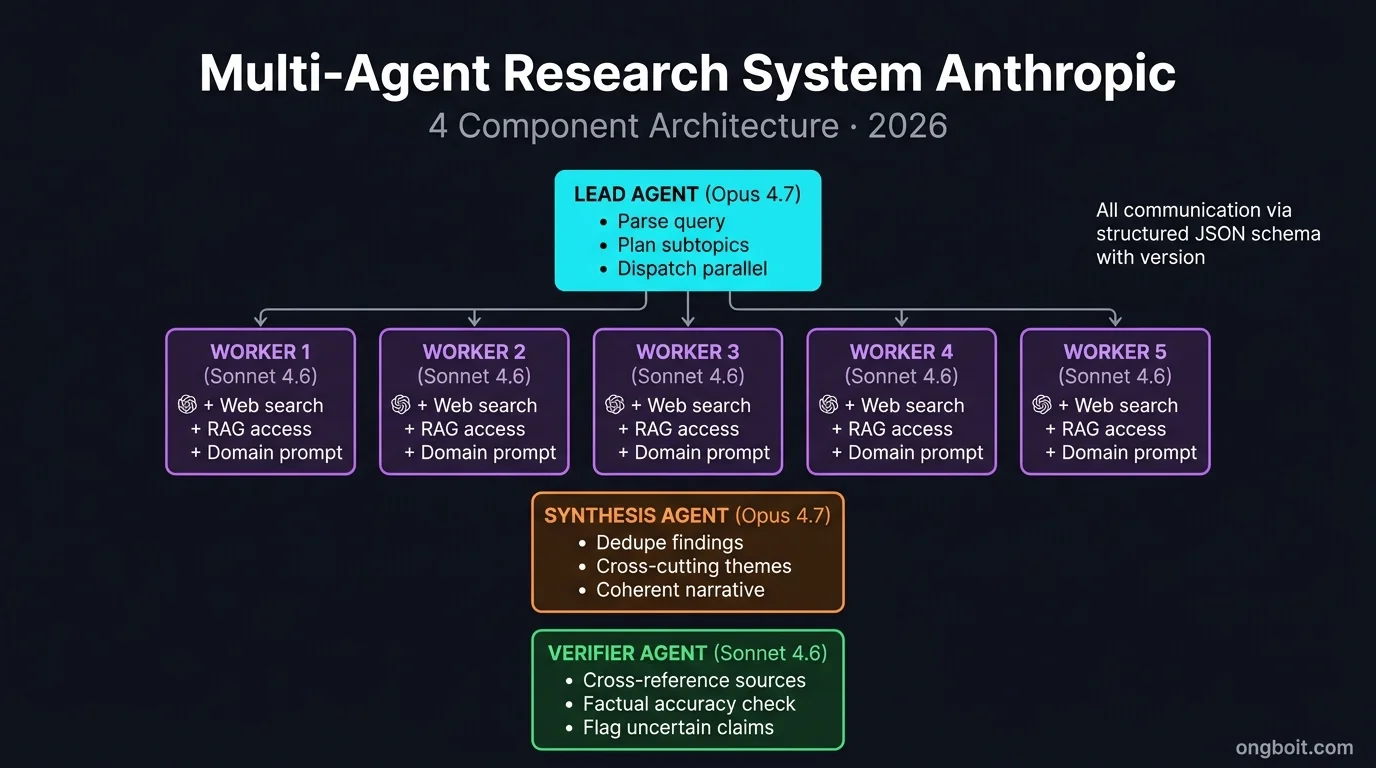
Bốn component cốt lõi. Lead Agent (Orchestrator) nhận query gốc từ user, phân tích complexity, chia thành subtopic, dispatch subagent. Lead agent dùng Opus (model mạnh nhất) vì decision quality quan trọng nhất ở phase này. Research Subagents xử lý từng subtopic song song. Mỗi subagent có web search tool, RAG access vào internal knowledge base, và prompt chuyên biệt cho domain. Số subagent động từ 3 tới 10 tuỳ complexity query, lead agent quyết định.
Synthesis Agent nhận findings từ tất cả subagent, deduplicate redundant info, identify cross-cutting themes, gộp thành coherent narrative. Synthesis agent cũng dùng Opus vì cần reasoning sâu để integrate diverse sources. Verifier Agent (optional) review final output, check factual accuracy bằng cross-reference với sources, flag uncertain claims. Verifier dùng Sonnet 4.6 vì task có pattern rõ ràng.
Communication giữa các agent dùng structured JSON với schema cố định. Mỗi subagent return: list of sources, list of key findings, confidence score, gaps identified. Format này giúp Synthesis Agent parse chính xác và dedupe efficient. Pattern này tương tự cách Managed Agents với Dreaming và Outcomes handle agent-to-agent communication.
Workflow 4 Phase Cụ Thể Diễn Ra Như Thế Nào?
Phase 1: Plan (Lead Agent, ~20 giây). Lead Agent đọc query, identify complexity level (simple/medium/complex), chia thành 3-10 subtopic độc lập. Output JSON: list of subtopic objects, mỗi object có name, description, search hints, expected source types. Pattern này tương tự “research brief” mà human researcher dùng trước khi bắt đầu.
Phase 2: Research (Research Subagents song song, ~2-3 phút). Mỗi subagent độc lập fetch sources cho subtopic của mình (web search Google/Bing, academic databases nếu có access, internal RAG). Subagent đọc top 5-10 sources, extract key facts, build mini-narrative cho subtopic. Output JSON với schema cố định bao gồm sources, findings, confidence, gaps.
Phase 3: Synthesize (Synthesis Agent, ~30 giây). Synthesis Agent nhận output JSON từ tất cả subagent, perform 3 task: deduplicate redundant findings, identify cross-cutting themes, integrate thành coherent narrative. Output là draft research report dạng markdown với citations.
Phase 4: Report (Verifier Agent + final formatting, ~30 giây). Verifier Agent check factual accuracy bằng cross-reference với original sources, flag claims không có source backing, suggest revisions. Lead Agent (hoặc Synthesis) áp dụng revisions, format final output cho user. Tổng workflow 3-5 phút, vs single-shot Claude trung bình 8-12 phút cho cùng query với chất lượng thấp hơn.

5 Lessons Learned Từ Production Multi-Agent Research?
Lesson một: dynamic subagent count, không hardcode. Anthropic ban đầu hardcode 5 subagent cho mọi query, kết quả overkill cho query đơn giản (đốt token vô ích) và underkill cho query phức tạp 10+ aspect. Sau khi switch sang dynamic count (Lead Agent quyết định 3-10 dựa trên complexity), cost giảm 30 phần trăm và quality tăng 15 phần trăm.
Lesson hai: structured handoff format giữa agents. Free-text handoff dẫn tới downstream agent miscount findings hoặc miss sources. Switch sang structured JSON với schema validation giảm error rate từ 8 phần trăm xuống 1 phần trăm. Schema thay đổi qua các phase nhưng luôn explicit và versioned.
Lesson ba: parallel by default cho research subagents. Subagent thường independent về data (mỗi subagent có subtopic riêng), nên parallel mặc định. Chỉ fall back sequential khi explicit dependency (rare, dưới 5 phần trăm case). Đây là khác biệt với workflow Prompt Chaining tuần tự.
Lesson bốn: cache aggressive cho reused fetches. Nhiều subagent fetch cùng source nếu subtopic overlap. Cache layer ở orchestrator level dedup HTTP request, giảm 25 phần trăm latency và 40 phần trăm bandwidth cost. Cache TTL phải reasonable (1 giờ cho news, 1 ngày cho documentation, 1 tuần cho academic paper).
Lesson năm: fail gracefully khi 1 worker timeout. Trong production có tỉ lệ 2-3 phần trăm subagent timeout (network issue, source slow). Pattern an toàn: synthesis agent vẫn proceed với output của subagent đã complete, note rõ subtopic missing. User nhận report incomplete tốt hơn nhiều so với chờ 10 phút mới fail. Đọc thêm về monitoring trong Agent View dashboard để track timeout patterns.
Áp Dụng Multi-Agent Research Cho Dự Án Việt Nam Như Thế Nào?
Use case phổ biến nhất: build internal research tool cho team consulting, marketing intelligence, hoặc legal compliance. Bắt đầu với pattern đơn giản hoá: 1 lead + 3 worker hardcode, mở rộng dynamic count sau khi pattern ổn định. Implementation core khoảng 300-500 dòng Python với Anthropic SDK, không cần framework như LangChain.
Đối với dự án Việt Nam có internal knowledge base, thay web search bằng RAG retriever vào ElasticSearch hoặc vector database. Pattern còn lại giống nhau: lead chia subtopic, worker query RAG, synthesis gộp. Tham khảo thêm cách build RAG hiệu quả trong cluster Obsidian của ongboit cho personal knowledge base, scale lên enterprise dùng pattern tương tự.
Đối với compliance và audit requirement (GDPR, NDPR Việt Nam): mỗi research session log đầy đủ vào audit trail (query gốc, list subagent, sources fetched, findings, final report). Pattern này tương tự cách production AI agent cần monitor cho regulated environment. Đọc đánh giá AI agent eval framework để build eval system riêng cho research quality.
Câu Hỏi Thường Gặp
Multi-Agent Research Tốn Token Nhiều Hơn Bao Nhiêu?
Trung bình 5-8 lần so với single-shot Claude cho cùng query. Lý do: mỗi subagent có context overhead (system prompt, tool definitions), nhiều subagent chạy song song nhân lên. Tuy nhiên latency giảm 3-5 lần nhờ parallel subagents, ROI dương cho task có business value cao. Đối với personal use cost-conscious, single Claude với web search vẫn hợp lý hơn.
Có Thể Dùng Sonnet Cho Lead Agent Thay Vì Opus Không?
Có thể nhưng Lead Agent quyết định critical (chia subtopic, dispatch, synthesize), đây là phase quan trọng nhất. Trade-off: Sonnet cho Lead tiết kiệm chi phí Lead phase, nhưng phase Lead chỉ chiếm 15 phần trăm tổng cost. Tiết kiệm nhỏ trong khi compromise ở quyết định quan trọng nhất, không đáng.
Subagent Có Cần Giao Tiếp Trực Tiếp Với Nhau Không?
Trong kiến trúc Anthropic, subagent không giao tiếp trực tiếp. Tất cả communication qua Lead/Synthesis Agent (hub-and-spoke topology). Pattern này đơn giản hơn debug và scale, dù latency cao hơn peer-to-peer 10-15 phần trăm. Đối với research workflow, đơn giản và reliable thắng performance edge.
Áp Dụng Pattern Này Cho Code Review Có Tốt Không?
Có. Adaptation: Lead Agent = senior reviewer chia file thành chunk, Research Subagents = chuyên review từng aspect (security/performance/style/correctness), Synthesis = compile final review report. Pattern này tương tự code review của Claude Code Parallel Claudes build C compiler nhưng cho review workflow.
Multi-Agent Có Thay Thế Được Human Researcher Không?
Không hoàn toàn. Multi-agent giỏi ở breadth (cover nhiều subtopic nhanh) và speed (3-5 phút vs hours), nhưng yếu ở depth analysis cho topic phức tạp đòi hỏi domain expertise sâu. Pattern thực tế dùng multi-agent research system: multi-agent làm “research assistant” – thu thập + tổng hợp data, sau đó human researcher review, validate, và làm phần analysis sâu. Combination này hiệu quả hơn cả hai riêng lẻ.
Bạn Có Nên Build Multi-Agent Research Cho Dự Án Của Mình?
Quyết định phụ thuộc 3 câu hỏi. Một, query có yêu cầu cover nhiều subtopic độc lập không (3+)? Nếu có, multi-agent giảm thời gian rõ rệt. Hai, query đủ valuable để biện minh cost 5-8 lần single-shot không? Đối với consulting deliverable hoặc executive briefing, có. Đối với internal note quick, có thể không.
Ba, có ngân sách build và maintain infrastructure không? Multi-agent system cần monitoring, caching, error handling, eval pipeline. Đầu tư ban đầu 1-2 tuần dev cho prototype, 1 tháng cho production-ready. Đọc thêm các pattern liên quan: Xây dựng AI agent hiệu quả 6 pattern cho theory tổng quát, Parallel Claudes C compiler case study cho ví dụ implementation cụ thể, đánh giá AI agent eval framework cho testing multi-agent quality.
Đọc thêm: Khi cần điều phối hàng chục đến hàng trăm agent cho một việc lớn mà không vỡ context, xem bài Dynamic Workflows trong Claude Code.