Đánh Giá AI Agent: Best Eval Framework Từ Anthropic 2026
Khi bạn build AI agent cho production, câu hỏi đầu tiên không phải “model nào tốt nhất” mà là “làm sao biết agent của tôi đang hoạt động đúng”. Đây chính là bài toán đánh giá AI agent (AI agent evaluation), lĩnh vực kỹ thuật vẫn còn mờ ám cho phần lớn lập trình viên vì chưa có tài liệu tiếng Việt tốt. Bài đăng “Demystifying Evals for AI Agents” của Anthropic Engineering xuất bản 9 tháng một năm 2026 là foundational post Anthropic Engineering “Demystifying Evals” đầu tiên giải thích rõ framework eval cho AI agent một cách hệ thống.
Bài viết này dịch và mở rộng nguyên bản tiếng Việt với context Việt Nam, phân tích bốn component cốt lõi của một eval framework gồm task, dataset, metric, judge, mô tả ba phương pháp evaluator phổ biến nhất, liệt kê năm anti-pattern thường gặp khi build eval system, và phần FAQ cho năm tình huống thực tế. Mục tiêu để bạn có thể tự thiết kế eval framework cho dự án AI agent của mình thay vì copy-paste từ tutorial mà không hiểu nguyên lý nền tảng.
TL;DR
- Đánh giá AI agent gồm 4 component: task (định nghĩa nhiệm vụ), dataset (input mẫu), metric (tiêu chí đo), judge (người hoặc LLM chấm điểm).
- 3 phương pháp evaluator phổ biến: rule-based (regex/code), LLM-as-judge (dùng LLM khác chấm), human-in-the-loop (con người chấm).
- Anti-pattern nguy hiểm nhất: dùng cùng LLM làm cả generator và judge, dẫn tới positive bias không phát hiện được lỗi.
- Quy tắc cốt lõi: bắt đầu eval ngay từ Day 0 của dự án, không chờ tới khi model đã ship production rồi mới đánh giá.
Đọc AI agent là gì trước để hiểu khái niệm cơ bản, và Xây dựng AI agent hiệu quả để biết 6 pattern kiến trúc. Bài này deep-dive vào việc đánh giá AI agent đã build.
- Task có output deterministic (parse JSON, extract entity): dùng rule-based evaluator, rẻ và nhanh nhất.
- Task có output mở (summarize, write report): dùng LLM-as-judge, scale tốt nhưng cần cẩn thận bias.
- Task quan trọng cao (medical, legal, financial): bắt buộc human-in-the-loop ít nhất giai đoạn đầu.
- Production agent: kết hợp ba phương pháp, mỗi phương pháp cho subset task khác nhau.
- Nguồn: Anthropic Engineering “Demystifying Evals for AI Agents” 9/1/2026, translate-and-expand với Vietnamese context.
- Hands-on: tác giả đã build eval framework cho hai dự án sản xuất 2025-2026.
- Không cover: benchmark cụ thể (MMLU, HumanEval) vì đó là task evaluation level mô hình, không phải agent.
- Freshness: best practice eval thay đổi theo từng quý, sẽ refresh khi Anthropic publish framework mới.
- Vendor influence: không có quan hệ thương mại.
Vì Sao Đánh Giá AI Agent Khó Hơn Đánh Giá Model Truyền Thống?
Đánh giá mô hình machine learning truyền thống có công thức rõ ràng: bạn có dataset test với ground truth, chạy model dự đoán, so sánh với truth bằng accuracy hoặc F1 score. Pattern đánh giá AI agent này áp dụng được vì task có output xác định: phân loại đúng hay sai, dự đoán giá đúng hay lệch bao nhiêu.
AI agent phá vỡ pattern này theo ba cách. Một, agent thường tạo output mở (generative output) như đoạn văn bản, code, hay quyết định nhiều bước, không có ground truth duy nhất. Hai, agent có thể đạt cùng mục tiêu qua nhiều đường khác nhau, một path tốt hơn path khác về cost, latency, robustness mà không phải về output cuối. Ba, agent tương tác với môi trường có state thay đổi, kết quả lần chạy này khác lần chạy khác dù input giống nhau.
Hậu quả: chỉ dùng accuracy số là không đủ. Đánh giá AI agent cần framework holistic xem xét output quality, process quality, cost efficiency, robustness, và safety. Anthropic Engineering proposes bốn component cốt lõi cho đánh giá AI agent mà mọi eval framework agent đều phải có, được trình bày trong phần tiếp theo.
4 Component Cốt Lõi Của Eval Framework Đánh Giá AI Agent Là Gì?
Component đầu tiên của đánh giá AI agent là Task definition. Mô tả chính xác agent đang giải bài toán gì, input format, output format mong đợi, success criteria. Task quá rộng như “agent giúp khách hàng” sẽ không đo được, phải narrow xuống như “agent phân loại ticket vào 5 category đã định” hoặc “agent draft email reply cho ticket loại ‘billing question’ với tone formal”. Quy tắc: nếu không thể viết bằng một câu rõ ràng có thể đo, task chưa định nghĩa đủ.
Component hai là Dataset. Tập hợp input mẫu để chạy agent, phải đại diện cho phân phối input thực tế trong production. Dataset cần bao gồm cả happy path (input điển hình), edge cases (input bất thường nhưng hợp lệ), và adversarial cases (input cố tình phá agent). Anthropic recommend bắt đầu với 50 tới 100 sample cho dataset đầu tiên, expand lên 500-1000 khi agent đã ổn định.
Component ba là Metric. Cách đo chất lượng output. Metric tốt phải đo được tự động hoặc semi-automatic, có thang điểm rõ ràng, và correlate với business outcome. Ví dụ metric cho summarize task: factual accuracy (0-1), coverage (0-1), conciseness (word count ratio). Tránh metric quá vague như “good summary” hoặc quá narrow như “contains keyword X”.
Component bốn là Judge. Người hoặc hệ thống chấm điểm output theo metric đã định. Judge có thể là rule-based script, LLM khác, hoặc con người. Phần tiếp theo phân tích chi tiết ba loại judge cùng trade-off.

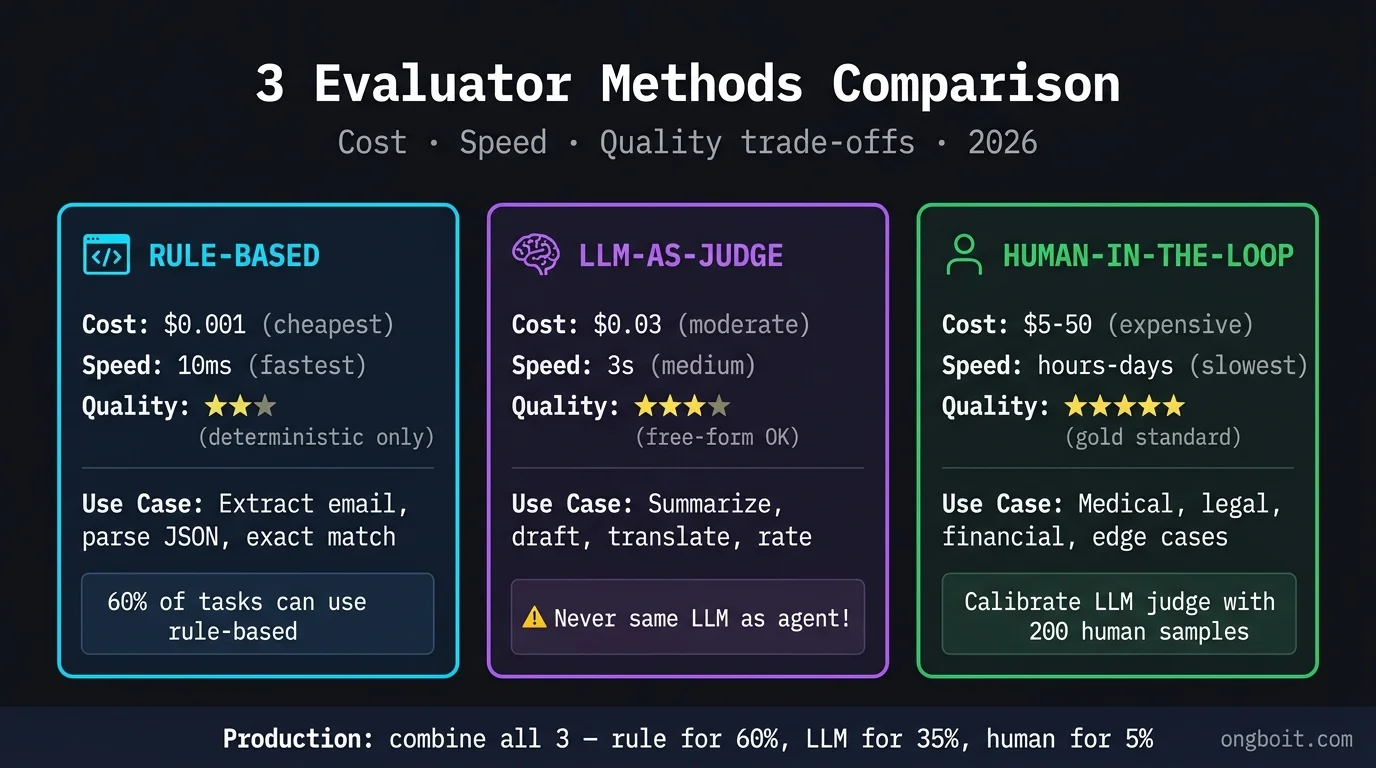
3 Phương Pháp Evaluator Phổ Biến Khi Đánh Giá AI Agent?
Rule-Based Evaluator
Rule-based evaluator dùng code (regex, JSON parser, exact match) để chấm output. Phương pháp này rẻ nhất, nhanh nhất, deterministic nhất. Phù hợp khi task có output structured như “extract email address from text” (regex match), “parse JSON response valid” (try/except), “answer is exactly one of [A, B, C, D]” (string compare).
Hạn chế: chỉ áp dụng được cho task có output deterministic. Không đánh giá được quality của free-form text, không hiểu nuance ngôn ngữ. Pattern thực tế: dùng rule-based cho 60 phần trăm task có thể automate, kết hợp với LLM-as-judge cho 40 phần trăm còn lại cần đánh giá quality.
LLM-As-Judge Evaluator
LLM-as-judge dùng một LLM khác để chấm output của agent. Cho LLM judge một rubric (ví dụ “rate 1-5 based on factual accuracy, coverage, conciseness”), cho input và output của agent, judge return số điểm kèm reasoning. Phương pháp này scale tốt cho free-form output, rẻ hơn human evaluator nhiều.
Cảnh báo quan trọng: tuyệt đối không dùng cùng LLM làm cả generator và judge. Nghiên cứu Anthropic và các nhóm khác chỉ ra LLM có positive bias mạnh đối với output của chính mình, dẫn tới overestimate quality khoảng 20-30 phần trăm. Pattern an toàn: nếu agent dùng Sonnet 4.6, dùng Opus 4.7 làm judge (model mạnh hơn). Hoặc dùng GPT-5.5, Gemini, Llama làm judge để có cross-model evaluation.
Human-In-The-Loop Evaluator
Human evaluator là gold standard. Con người chấm output dựa trên rubric, cho điểm và feedback chi tiết. Phương pháp này tốn nhất (10-50 USD mỗi review tuỳ độ phức tạp) và chậm nhất (mất giờ tới ngày). Bù lại, chất lượng đánh giá cao nhất, đặc biệt cho task có yêu cầu nuance như tone, persuasiveness, compliance.
Pattern thực tế: dùng human evaluator cho subset 5-10 phần trăm sample mỗi round, đặc biệt cho edge cases và adversarial cases. Hai trăm sample human-reviewed là baseline tốt để calibrate LLM-as-judge. Sau khi đã verify LLM judge correlate với human judge, scale lên dùng LLM cho phần còn lại.
5 Anti-Pattern Nguy Hiểm Khi Đánh Giá AI Agent Là Gì?
Anti-pattern một: dùng cùng LLM làm generator và judge. Như đã nhắc ở phần trên, dẫn tới positive bias 20-30 phần trăm. Luôn dùng LLM khác làm judge, ưu tiên model mạnh hơn agent.
Anti-pattern hai: dataset chỉ có happy path. Dev thường test với input điển hình mà bỏ qua edge cases và adversarial cases. Production agent gặp 10-20 phần trăm input bất thường, nếu không test trước sẽ fail trong tay khách hàng. Bắt buộc include 20 phần trăm edge cases trong dataset eval.
Anti-pattern ba: chỉ đo output quality, bỏ qua process quality. Agent có thể đạt output đúng nhưng tốn 50K token vô ích cho task lý ra cần 5K. Process metric như “average tool calls per task” và “average tokens per task” quan trọng không kém output metric. Đọc thêm về pattern tiết kiệm token trong tiết kiệm token Claude Code.
Anti-pattern bốn: eval chỉ một lần trước launch. Agent quality drift theo thời gian khi model bị update, khi dataset distribution thay đổi, khi user behavior evolve. Setup eval pipeline chạy weekly hoặc monthly để phát hiện regression sớm. Pattern Outcomes loop trong Managed Agents với Dreaming và Outcomes chính là continuous eval ở production scale.

Anti-pattern năm: đo accuracy tổng thể mà không break down theo segment. Agent có thể đạt 90 phần trăm accuracy tổng nhưng chỉ 30 phần trăm cho subset “Vietnamese language input” hoặc 20 phần trăm cho “long context >100K token”. Always break down kết quả eval theo các segment quan trọng để phát hiện blind spot.
Bắt Đầu Đánh Giá AI Agent Từ Đâu?
Lộ trình ba tuần để build eval framework đầu tiên cho dự án của bạn. Tuần một, định nghĩa task và metric. Viết task definition ngắn gọn một câu, chọn 3-5 metric cụ thể đo được, tạo dataset 50 sample bao phủ happy path cùng 10 edge cases. Đầu tư thời gian vào task definition vì sai bước này, mọi bước sau đều sai.
Tuần hai, implement rule-based evaluator cho phần task có thể automate (structured output, exact match). Đo accuracy baseline, ghi note các pattern fail thường gặp. Tuần ba, add LLM-as-judge cho phần task free-form. Dùng Opus 4.7 hoặc model khác mạnh hơn agent làm judge. Calibrate bằng cách human-review 20 sample, so sánh điểm LLM judge với human judge, tinh chỉnh rubric tới khi correlation đạt 0.8 trở lên.
Sau khi eval framework hoạt động ổn định, automate qua CI/CD: mỗi pull request thay đổi agent code phải pass eval trước khi merge. Pattern này được nhiều startup AI agent dùng, đảm bảo regression không lọt vào production. Tham khảo implementation cụ thể trong cluster ongboit: Xây dựng AI agent hiệu quả cho kiến trúc 6 pattern, sub-agents trong Claude Code cho orchestration, Managed Agents Dreaming Outcomes cho continuous eval pattern production-grade.
Câu Hỏi Thường Gặp
LLM-As-Judge Có Đáng Tin Không?
Đáng tin khi calibrate đúng cách. Nghiên cứu cho thấy LLM judge có correlation 0.7-0.9 với human judge cho task được rubric rõ ràng, đặc biệt khi dùng model mạnh hơn agent. Bí quyết: dùng cross-model evaluation (model khác họ với agent), human-calibrate baseline 200 sample, theo dõi correlation drift theo thời gian.
Dataset Bao Nhiêu Sample Là Đủ?
50-100 sample cho prototype đầu tiên đủ để phát hiện big issues. 500-1000 sample cho production-ready agent. Hơn 5000 sample thường overkill cho dev solo, dành ngân sách cho human review thay vì expand dataset. Quan trọng hơn số lượng là chất lượng coverage: happy path + edge cases + adversarial cases.
Eval Có Thay Thế Được Manual QA Không?
Không hoàn toàn. Eval automate phần lớn việc QA (60-80 phần trăm) nhưng không thay thế hoàn toàn human review cho task quan trọng. Pattern thực tế: eval automate phát hiện regression và quality drift, human review spot-check 5-10 phần trăm output mỗi tuần, đặc biệt cho edge cases agent đã fail trong quá khứ.
Eval Có Tốn Token Nhiều Không?
Có, đặc biệt LLM-as-judge. Mỗi eval round 100 sample × 2 prompts (generator + judge) × 10K token = 2 triệu token, tương đương 6 USD pricing Sonnet 4.6. Tối ưu cost: dùng rule-based cho task automate được, dùng smaller model làm judge khi không cần độ chính xác cao nhất, batch eval qua Anthropic Batch API giảm 50 phần trăm cost.
Eval Continuous Vs Eval Một Lần Khác Gì?
Eval một lần là baseline trước launch, eval continuous chạy weekly hoặc monthly trong production. Continuous quan trọng vì agent quality drift theo thời gian. Pattern: eval một lần trước launch để xác nhận agent đạt threshold, sau đó continuous eval qua cron để phát hiện regression. Outcomes loop của Anthropic là implementation production-grade của continuous eval pattern.
Bạn Nên Build Eval Framework Đầu Tiên Cho Task Nào?
Khuyến nghị mạnh: bắt đầu với task có output deterministic và dataset nhỏ. Ví dụ tốt cho lần đầu: extract email/phone từ text, classify ticket vào category đã định, parse structured data từ unstructured input. Ba loại task này có rule-based evaluator đơn giản, dataset 50 sample đủ, build trong nửa ngày để có working framework.
Sau khi đã có pipeline làm việc, mở rộng dần sang task free-form như summarize, draft email, generate report. Tuần thứ hai mới thử LLM-as-judge sau khi đã quen với rule-based. Tránh nhảy thẳng vào human-in-the-loop vì tốn quá nhiều thời gian cho beginner.
Tham khảo cluster đánh giá AI agent trên ongboit: AI agent là gì cho khái niệm, Xây dựng AI agent hiệu quả cho 6 pattern kiến trúc, Managed Agents production cho continuous eval pattern. Đối với eval-driven workflow trong Claude Code daily, đọc Claude Code hacks và mẹo Level 5 nhóm Outcomes loop.