n8n Error Handling: Hướng Dẫn 3 Tầng Bảo Vệ Workflow (2026)
Bởi Ông Bố IT · DevOps engineer, vận hành n8n production 4+ năm · Cập nhật 04/2026
Mình vận hành n8n với hơn 50 workflow production. Một tối, workflow gửi hóa đơn tự động bị lỗi âm thầm suốt cả đêm. Sáng ra khách hàng gọi điện mới biết. Không có alert, không có log rõ ràng, chỉ có một đống email chưa gửi và cảm giác rất khó chịu. Từ hôm đó, mình bắt đầu setup n8n error handling nghiêm túc cho toàn bộ hệ thống.
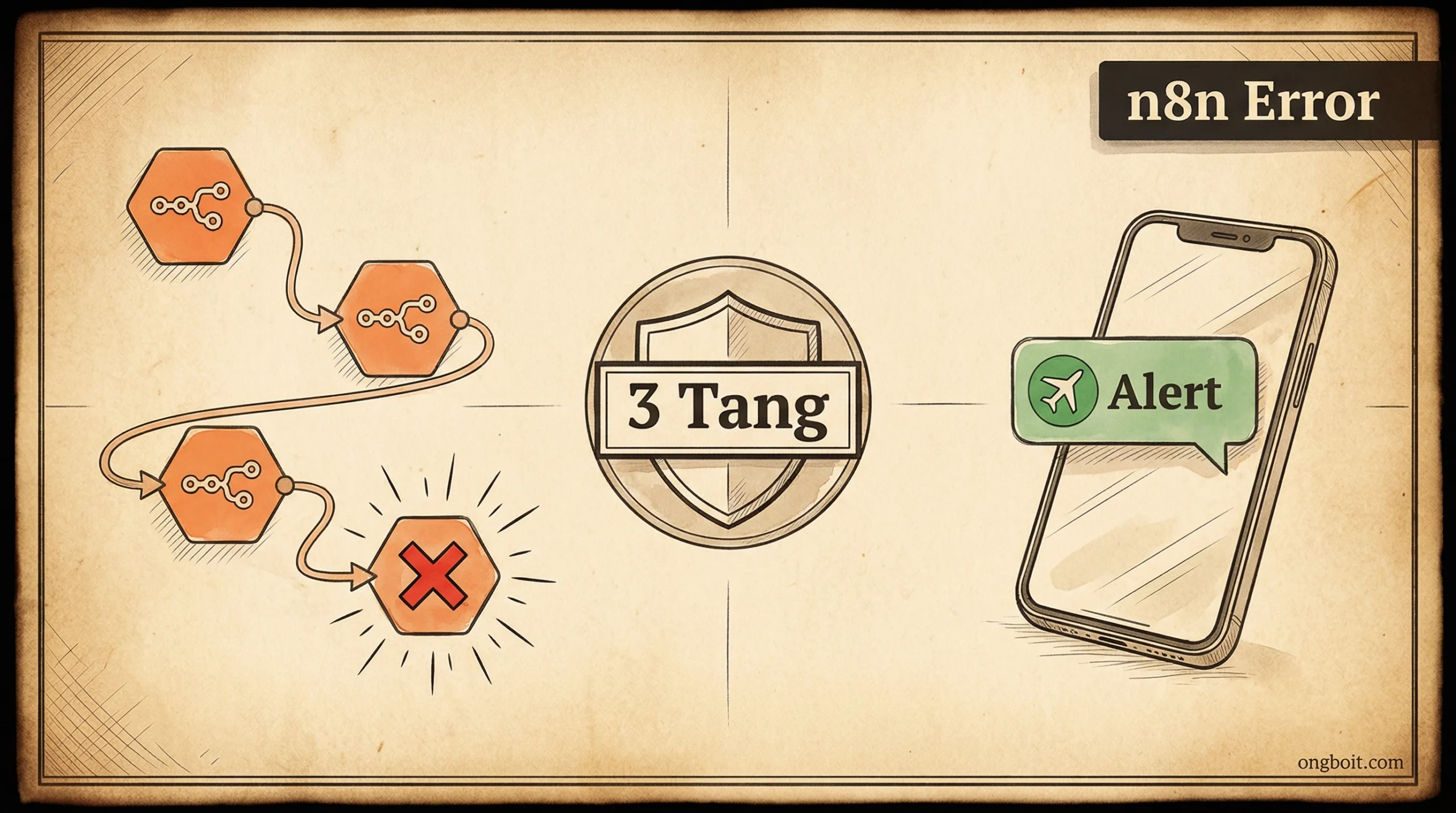
n8n có 3 tầng xử lý lỗi độc lập: Retry on Fail (node-level), Error Output Pin (rẽ nhánh trong workflow), và Error Workflow (cảnh báo toàn cục). Kết hợp với Telegram alert, bạn nhận thông báo trong vòng 30 giây khi có workflow thất bại. Gotcha nguy hiểm nhất cần nhớ: Retry on Fail bị tắt hoàn toàn khi “On Error” = “Continue”, đây là GitHub issue #10763, được confirm bởi n8n team.
Tại Sao Workflow n8n Của Bạn Cần Error Handling?
Theo Uptrends State of API Reliability 2025, 67% tổng số monitoring failures xuất phát từ lỗi API, và API downtime tăng trung bình 60% chỉ trong một năm. Nếu bạn chạy workflow n8n production mà không có n8n error handling, mỗi incident đó là một lần workflow thất bại âm thầm.
API downtime không phải xu hướng đang giảm. Thời gian downtime trung bình tăng 60% từ Q1 2024 lên Q1 2025, từ 34 phút mỗi tuần lên 55 phút mỗi tuần (Uptrends, 2025). Với n8n self-hosted chạy 24/7, con số này có nghĩa là gần một giờ mỗi tuần quy trình tự động của bạn có thể bị ảnh hưởng.
Workflow không có error handling dẫn đến silent failure: không có alert, data vẫn bị mất hoặc chưa được xử lý, và khách hàng thường là người phát hiện lỗi trước bạn. Mình đã trải qua điều đó, và mình không muốn bạn phải qua cùng cảm giác đó.
3 Tầng Xử Lý Lỗi Trong n8n Là Gì?
n8n error handling hoạt động theo 3 tầng độc lập, mỗi tầng giải quyết một loại lỗi khác nhau. Tầng 1 xử lý lỗi tạm thời như timeout và rate limit. Tầng 2 rẽ nhánh logic khi có lỗi có thể xử lý được trong cùng workflow. Tầng 3 gửi cảnh báo toàn cục khi workflow thất bại hoàn toàn. Kết hợp cả ba, bạn có một hệ thống error handling hoàn chỉnh.
Tầng 1: Retry on Fail
Retry on Fail là tầng đơn giản nhất và nên bật cho mọi node gọi external API. Vào Node Settings của node đó, bật “Retry on Fail”, đặt Max Tries theo loại dịch vụ: 3 lần cho external API thông thường, 2 lần cho AI models, và 5 lần cho file operations. Wait Between Tries nên đặt 5 giây, đủ để rate limit reset.
# Cấu hình Retry on Fail khuyến nghị
Retry on Fail: ON
Max Tries: 3 # External API (Stripe, SendGrid, ...)
Max Tries: 2 # AI models (OpenAI, Anthropic)
Max Tries: 5 # Đọc/ghi file
Wait Between: 5s # Đủ thời gian cho rate limit resetLưu ý quan trọng: Retry on Fail chỉ hoạt động đúng khi “On Error” của node đó được đặt là “Stop Workflow”. Nếu bạn đang dùng “Continue” hoặc “Continue (using Error Output)”, retry sẽ bị bỏ qua hoàn toàn. Mình sẽ giải thích kỹ hơn ở phần tiếp theo.
Tầng 2: Continue (using Error Output)
Khi bật “Continue (using Error Output)” trên một node, n8n tạo ra dual output pin: đường màu xanh cho dữ liệu thành công, đường màu đỏ cho dữ liệu lỗi. Bạn kéo hai nhánh này đến các node xử lý khác nhau trong cùng một workflow.
Tầng 2 phù hợp khi lỗi có thể xử lý được trong luồng hiện tại, ví dụ ghi log lỗi vào Google Sheets, gửi fallback response cho user, hoặc thử lại với dữ liệu đã được làm sạch. Đừng dùng tầng 2 cho lỗi nghiêm trọng cần dừng toàn bộ workflow và báo ngay cho admin.
Tầng 3: Error Workflow và Error Trigger Node
Error Workflow là tầng mạnh nhất. Bạn tạo một workflow riêng biệt chỉ để xử lý lỗi, rồi gắn nó vào các workflow production trong Workflow Settings. Khi bất kỳ node nào trong workflow production thất bại và dừng lại, n8n tự động kích hoạt Error Workflow.
Error Trigger node nhận đầy đủ thông tin về lỗi qua các fields sau (xem thêm n8n Error Handling documentation):
# Error data fields trong Error Trigger node
$json.workflow.name # Tên workflow bị lỗi
$json.workflow.id # ID workflow
$json.execution.url # Link trực tiếp đến execution bị lỗi
$json.node.name # Node cuối cùng bị fail
$json.error.message # Message lỗi đầy đủ
$json.execution.lastNodeExecuted # Node chạy cuối trước khi lỗiSau khi tạo Error Handler workflow và activate nó, vào từng workflow production, mở Workflow Settings, tìm mục “Error Workflow” và chọn “Error Handler”. Nếu bạn chưa biết cách cài đặt n8n self-hosted với Docker Compose, đây là bước cần làm trước khi setup error handling.
Cái Bẫy Nguy Hiểm Nhất Trong n8n Error Handling Là Gì?
Retry on Fail bị bỏ qua hoàn toàn khi “On Error” của node được đặt là “Continue” hoặc “Continue (using Error Output)”. Đây là GitHub issue #10763, được xác nhận bởi n8n team nhưng chưa có fix chính thức. Workflow tiếp tục chạy ngay lần fail đầu tiên mà không thực hiện bất kỳ lần retry nào.
Đây là cách hai setting này xung đột nhau và cách fix:
# SAI: Retry bị bỏ qua hoàn toàn
On Error: "Continue (using Error Output)"
Retry on Fail: ON # Không có tác dụng gì!
Max Tries: 3 # Bị bỏ qua
# ĐÚNG: Retry hoạt động bình thường
On Error: "Stop Workflow"
Retry on Fail: ON # Hoạt động đúng
Max Tries: 3 # Retry 3 lần trước khi kích hoạt Error WorkflowFix rất đơn giản: chọn một trong hai chiến lược, không trộn lẫn. Nếu muốn retry tự động, đặt “On Error” = “Stop Workflow” và bật Retry on Fail. Nếu muốn rẽ nhánh xử lý lỗi, đặt “On Error” = “Continue (using Error Output)” nhưng hiểu rằng retry sẽ không chạy.

Cách Setup n8n Error Workflow Từng Bước?
Setup n8n error handling đầy đủ chỉ mất khoảng 10 phút và không cần viết code. Toàn bộ quy trình gồm 6 bước: tạo workflow mới, thêm Error Trigger node, kết nối kênh thông báo, activate, gắn vào workflow production, và test. Sau khi xong, mọi workflow production của bạn đều được bảo vệ.
Bước 1: Tạo một workflow mới trong n8n, đặt tên rõ ràng như “Error Handler – Production”. Tên rõ ràng giúp dễ phân biệt khi bạn có nhiều workflow.
Bước 2: Thêm node “Error Trigger” làm node đầu tiên. Node này không cần cấu hình thêm gì. Nó tự động nhận data từ bất kỳ workflow nào gắn nó làm Error Workflow.
Bước 3: Thêm Telegram node nối trực tiếp sau Error Trigger. Trong phần message, dùng template sau:
# Telegram message template cho Error Handler
🚨 Workflow Lỗi!
Workflow: {{ $json.workflow.name }}
Node lỗi: {{ $json.node.name }}
Lỗi: {{ $json.error.message }}
Chi tiết: {{ $json.execution.url }}
Thời gian: {{ $now.format('dd/MM/yyyy HH:mm:ss') }}Bước 4: Nhấn “Activate” cho workflow “Error Handler – Production”. Workflow phải ở trạng thái Active, không phải draft, mới nhận được trigger từ các workflow khác.
Bước 5: Vào từng workflow production cần bảo vệ. Mở Workflow Settings (góc phải màn hình), tìm mục “Error Workflow”, chọn “Error Handler – Production” từ dropdown.
Bước 6: Test toàn bộ pipeline. Thêm một node “Set” vào workflow production, gán giá trị sai kiểu dữ liệu để trigger lỗi, chạy workflow, và kiểm tra xem Telegram có nhận được alert không.
Gửi Cảnh Báo Lỗi n8n Qua Telegram Như Thế Nào?
Telegram là kênh alert lý tưởng cho n8n error handling vì hoàn toàn miễn phí, có API ổn định, và bot setup chỉ mất 5 phút. n8n.io có 3 official Telegram error alert templates sẵn dùng:
- Template 5939: multi-language, phù hợp hệ thống quốc tế (mình dùng cái này làm base)
- Template 4407: Telegram + Google Sheets + Gmail, phù hợp khi cần log lỗi vào spreadsheet
- Template 5629: multi-channel, gửi cùng lúc qua Telegram, Slack, và email
Cách tạo Telegram bot và lấy các thông tin cần thiết:
# Bước 1: Lấy Bot Token
# Tìm @BotFather trên Telegram
# Gõ /newbot → đặt tên bot → copy token
# Token format: 123456789:AABBccDDeEFfGGhhIIjjKKllMMnnOOppQQ
# Bước 2: Lấy Chat ID của group/channel nhận alert
# Thêm bot vào group, rồi truy cập URL:
https://api.telegram.org/bot{TOKEN}/getUpdates
# Chat ID của group thường là số âm, ví dụ: -1001234567890
# Bước 3: Test thủ công trước khi thêm vào n8n
curl "https://api.telegram.org/bot{TOKEN}/sendMessage" \
-d "chat_id=-1001234567890&text=Test alert từ n8n"Sau khi có token và chat ID, thêm Telegram node vào Error Handler workflow. Chọn “Send Message” làm operation, điền chat ID, và paste message template vào trường Text. Bật Markdown mode để format message rõ ràng hơn.

Nếu bạn muốn theo dõi sức khỏe toàn bộ hệ thống n8n, không chỉ riêng lỗi workflow, bài viết về monitoring n8n production với Prometheus sẽ giúp bạn setup dashboard và alerting đầy đủ hơn.
Checklist n8n Error Handling: 6 Điều Bắt Buộc Trước Khi Deploy
Workflow production thiếu n8n error handling giống một quả bom hẹn giờ, không phải vấn đề nếu hay không mà là vấn đề bao giờ. Dưới đây là 6 mục bắt buộc kiểm tra trước mỗi lần deploy workflow quan trọng, dựa trên kinh nghiệm vận hành hơn 50 workflow production liên tục.
- Retry on Fail bật với Max Tries = 3, Wait Between Tries = 5 giây cho mọi API node.
- Error Workflow đã được gắn vào mọi workflow production trong Workflow Settings.
- Telegram hoặc email alert đã được test thành công ít nhất một lần thực tế.
- “On Error” = “Stop Workflow” trên mọi node có bật Retry on Fail (tránh gotcha #10763).
- Error Handler workflow đang ở trạng thái Active, không phải draft hay inactive.
- Có ít nhất một lần review execution logs mỗi tuần, kể cả khi không có alert.
Điểm số 6 thường bị bỏ qua nhất. Alert chỉ báo khi workflow dừng hẳn. Nhưng workflow có thể chạy xong mà vẫn xử lý sai dữ liệu, không có lỗi nhưng kết quả không đúng. Review logs định kỳ giúp phát hiện loại lỗi im lặng này sớm hơn.
Nếu bạn đang chạy n8n với nhiều workflow song song, bài viết về n8n Queue Mode khi cần xử lý hàng nghìn workflow sẽ giúp bạn scale hạ tầng đúng cách, kết hợp với error handling để hệ thống vừa nhanh vừa ổn định.
Error Handling Liên Kết Với Phần Còn Lại Của Ecosystem n8n 2026 Ra Sao?
Phần này giúp bạn hiểu rõ vị trí của error handling trong toàn bộ hệ sinh thái n8n năm 2026, từ giai đoạn triển khai cơ bản đến tích hợp với Claude Code phức tạp. Hiểu được sự liên kết giữa các thành phần giúp team product thiết kế system tổng thể hợp lý ngay từ đầu.
Error handling đặc biệt quan trọng khi triển khai trên Coolify cho self-host n8n. Mặc dù Coolify có khả năng tự động restart container khi bị crash ở mức OS, nhưng không thể xử lý được lỗi logic bên trong workflow. Pattern bảo vệ tốt nhất là kết hợp khả năng recovery cấp container của Coolify với cơ chế catch error cấp workflow trong n8n. Cách kết hợp này tạo thành 2 layer bảo vệ song song, đảm bảo system luôn duy trì hoạt động ngay cả khi gặp sự cố không lường trước được. Đặc biệt quan trọng cho các team nhỏ tại VN không có on-call ngoài giờ làm việc, system tự recovery giúp giảm áp lực vận hành đáng kể.
Khi triển khai các AI agent workflow trong n8n, vai trò của error handling càng trở nên quan trọng hơn nhiều so với workflow thông thường. AI agent có thể trả về response không đúng format mong đợi, vượt quá token limit, hoặc gặp lỗi rate limit của vendor. Pattern bảo vệ tốt nhất là kết hợp retry limit với alert qua Slack khi vượt threshold, đảm bảo team kỹ thuật được notify ngay khi có vấn đề xảy ra với AI processing pipeline tự động hằng ngày.
Pattern tích hợp với Claude Code qua MCP cũng đòi hỏi cấu hình error handling đặc biệt vì có thêm layer gọi Claude API có thể fail riêng biệt với workflow n8n thuần. Team development cần thiết kế pattern catch error theo từng layer riêng biệt, lỗi authentication Claude API khác với lỗi rate limit, khác với lỗi network. Mỗi loại lỗi cần có action xử lý khác nhau và alert phù hợp cho PM. Đầu tư 2-3 ngày thiết kế kỹ multi-tier error handling pattern ban đầu giúp tiết kiệm hàng tuần khắc phục sự cố về sau khi pipeline đã chạy ở quy mô lớn.
Checklist n8n Error Handling Cho Team VN Triển Khai Production
Phần này tổng hợp 3 bài học bổ sung quan trọng từ kinh nghiệm thực tế triển khai error handling cho nhiều khách hàng doanh nghiệp VN trong 6 tháng đầu năm 2026. Mỗi bài học đều là kinh nghiệm thực chiến không có trong docs chính thức của vendor, đáng được chia sẻ cho người mới bắt đầu để tránh các sai lầm tốn kém về thời gian và chi phí.
Bài học đầu tiên là về tầm quan trọng của việc đặt retry limit hợp lý cho mỗi loại workflow khác nhau. Nhiều team mới triển khai có xu hướng đặt retry cao một cách máy móc, nghĩ rằng càng nhiều retry thì càng đảm bảo workflow chạy thành công. Thực tế ngược lại hoàn toàn khi một số lỗi đặc thù như authentication không thể khắc phục được bằng retry đơn thuần. Pattern khôn ngoan là phân loại lỗi thành 3 nhóm chính bao gồm transient error như network yếu, permanent error như sai config, và manual intervention error như sai input data. Mỗi nhóm lỗi cần có retry strategy khác nhau, không nên áp dụng cùng một rule cho mọi tình huống.
Bài học thứ hai là về việc lưu trữ thông tin chi tiết về mỗi lần error xảy ra để phục vụ root cause analysis về sau. Nhiều team chỉ ghi lại error message đơn giản, không lưu giữ đầy đủ context như env var, input data, workflow version lúc lỗi xảy ra. Khi cần phân tích nguyên nhân sự cố về sau, thiếu thông tin chi tiết khiến quá trình điều tra trở nên rất khó khăn và mất nhiều thời gian. Pattern khôn ngoan là cấu hình log error đầy đủ với cấu trúc file có thể query dễ dàng, lưu giữ ít nhất 30 ngày để có đủ data phục vụ trend analysis dài hạn của system.
Bài học thứ ba là về tầm quan trọng của việc train team cách phản ứng nhanh khi nhận alert từ system. Nhiều team nhận được alert nhưng không biết phải xử lý theo runbook nào, dẫn đến tình trạng alert bị bỏ qua hoặc xử lý chậm trễ gây hậu quả nghiêm trọng. Pattern khôn ngoan là xây dựng runbook chi tiết cho từng loại alert cụ thể, kèm theo session drill định kỳ hằng quý để team luôn sẵn sàng phản ứng đúng cách. Đặc biệt quan trọng cho các team có traffic cao, một phút phản ứng chậm có thể gây thiệt hại đáng kể về revenue hoặc user experience.
Câu Hỏi Thường Gặp
Dưới đây là 5 câu hỏi phổ biến nhất về n8n error handling mà mình nhận được từ cộng đồng, kèm câu trả lời dựa trên kinh nghiệm thực tế vận hành production.
Retry on Fail không hoạt động trong n8n, nguyên nhân là gì?
Nguyên nhân phổ biến nhất là xung đột với setting “On Error”. Khi “On Error” được đặt là “Continue” hoặc “Continue (using Error Output)”, Retry on Fail bị bỏ qua hoàn toàn, dù bạn đã bật và đặt Max Tries = 3. Fix: đặt “On Error” = “Stop Workflow” trước, rồi bật Retry on Fail. Đây là GitHub issue #10763, đã được n8n team xác nhận nhưng chưa có fix chính thức.
Error Trigger node nhận được dữ liệu gì từ workflow bị lỗi?
Error Trigger nhận 6 fields chính: $json.workflow.name (tên workflow), $json.workflow.id (ID), $json.execution.url (link trực tiếp đến execution lỗi), $json.node.name (node cuối fail), $json.error.message (message lỗi đầy đủ), và $json.execution.lastNodeExecuted. Với 6 fields này, bạn có đủ thông tin để debug mà không cần vào n8n UI tìm thủ công.
Làm sao gửi cảnh báo lỗi n8n qua Telegram nhanh nhất?
Dùng template 5939 trên n8n.io, import vào n8n, thêm Telegram credentials (token từ @BotFather và chat ID của group). Đặt workflow này làm Error Workflow trong Workflow Settings của mọi workflow production. Nhớ đặt “On Error” = “Stop Workflow” trên các node quan trọng để Error Workflow được kích hoạt đúng lúc.
Có nên đặt Error Workflow cho tất cả workflow không?
Không cần thiết cho tất cả. Quy tắc mình dùng: workflow quan trọng như gửi email, xử lý thanh toán, sync data giữa hệ thống thì bắt buộc phải có Error Workflow. Workflow test, chạy thủ công, hoặc không ảnh hưởng đến user thì không cần. Ưu tiên bảo vệ workflow chạy theo lịch (scheduled) và webhook-triggered trước.
n8n có hỗ trợ exponential backoff tự động không?
Hiện tại n8n chưa hỗ trợ exponential backoff tích hợp sẵn. Retry on Fail chỉ dùng fixed delay (Wait Between Tries). Nếu cần exponential backoff, bạn có thể dùng Execute Workflow node tự gọi lại với Wait node tăng dần theo số lần thử, hoặc tham khảo template 5447 trên n8n.io chuyên về advanced retry logic. Cần lưu ý so sánh n8n Cloud vs self-host nếu bạn đang cân nhắc giải pháp managed có sẵn retry phức tạp hơn.
Kết Luận: Stack n8n Error Handling Chuẩn Cho Production
Stack n8n error handling chuẩn cho production gồm 3 tầng kết hợp: Retry on Fail cho lỗi tạm thời, Error Output Pin cho lỗi có thể xử lý trong workflow, và Error Workflow với Telegram alert cho lỗi nghiêm trọng cần phản hồi ngay. Ba tầng này độc lập và bổ sung cho nhau.
Điều quan trọng nhất cần ghi nhớ về n8n error handling: gotcha #10763 là Retry on Fail không hoạt động khi “On Error” = “Continue”. Đây là lỗi cấu hình phổ biến nhất và khó phát hiện nhất vì workflow vẫn chạy bình thường, chỉ là retry không được thực thi.
Bước tiếp theo tự nhiên sau khi có error handling là setup monitoring và scale hạ tầng. Bắt đầu với Error Workflow và Telegram alert, mở rộng dần khi hệ thống lớn hơn. Đừng chờ đến khi khách hàng gọi điện mới bắt đầu setup n8n error handling.
Điều mình nhận ra sau bốn năm vận hành n8n là: hệ thống tự động hóa tốt không phải là hệ thống không bao giờ lỗi, mà là hệ thống biết cách xử lý lỗi một cách có kiểm soát. Khi workflow thất bại mà bạn vẫn nhận được alert trong vòng 30 giây và có đủ thông tin để debug ngay lập tức, đó mới là dấu hiệu của một hệ thống production thực sự trưởng thành.