AutoResearch là một kỹ thuật mà Andrej Karpathy phát hành ngày 7/3/2026: bạn định nghĩa một metric, rồi để AI agent tự chạy hàng trăm thử nghiệm qua đêm, giữ cải tiến, loại bỏ thất bại. Kết quả? Shopify giảm 53% thời gian xử lý, Driveline tăng R² từ 0.44 lên 0.78. Bạn không cần GPU hay ML background để bắt đầu. Cài uditgoenka/autoresearch qua Claude Code Skills marketplace, viết program.md, chạy lệnh, rồi ngủ ngon.



Bạn có bao giờ tự hỏi: “Liệu mình có thể để AI tự cải thiện code trong khi mình đang ngủ không?” Đó chính xác là thứ Andrej Karpathy đã xây dựng. Ngày 7/3/2026, ông phát hành karpathy/autoresearch và thu về 42.000 GitHub stars chỉ trong tuần đầu tiên. Kỹ thuật này, mà Fortune sau đó gọi là “The Karpathy Loop”, đang thay đổi cách developer tiếp cận optimization. Bài này mình sẽ giải thích cách hoạt động, so sánh 4 implementations, và hướng dẫn bạn chạy autoresearch claude code ngay trong dự án của mình, không cần GPU, không cần background về ML.
- AutoResearch Claude Code chạy hàng trăm thử nghiệm tự động qua đêm, giữ cải tiến, revert thất bại.
- Shopify xác nhận -53% thời gian xử lý sau 120 thử nghiệm tự động (Shopify PR #2056).
- Bắt đầu với uditgoenka/autoresearch để chạy AutoResearch Claude Code mà không cần GPU, phù hợp để dùng ngay hôm nay.
- Chi phí một đêm chạy: $1.50-$4.50. ROI cực kỳ rõ ràng nếu metric cải thiện.
- Bước quan trọng nhất: định nghĩa metric đúng, không phải viết code.
AutoResearch Là Gì Và Tại Sao Viral?
AutoResearch là kỹ thuật để AI agent tự thực hiện vòng lặp nghiên cứu khoa học: đưa ra giả thuyết, chỉnh sửa code, đo kết quả, rồi giữ hoặc loại bỏ thay đổi đó. Karpathy phát hành repo gốc ngày 7/3/2026 và thu về 42.000 stars trong tuần đầu tiên, tổng hiện tại 70.100 stars (GitHub, 2026).
Tại sao nó viral? Vì kết quả không phải lý thuyết. Karpathy tự chạy 700 thử nghiệm trong 2 ngày, tìm ra 20 cải tiến thực sự, và giảm Time-to-GPT-2 từ 2.02 giờ xuống 1.80 giờ, nhanh hơn 11%. Đó là con số cứng, không phải demo vaporware.
Ngày 17/3/2026, Fortune đặt tên cho kỹ thuật này là “The Karpathy Loop” trong bài phân tích của tác giả Janakiram MSV (Fortune, 2026). Cái tên chính xác hơn tên gốc vì nó mô tả bản chất: một vòng lặp tự chủ, không phải một tool hay một library.
Bản thân Karpathy mô tả nó thẳng thắn: “You don’t ‘use it’ directly, it’s just a recipe/idea – give it to your agent and apply to what you care about.” Đây không phải SaaS product. Đây là pattern, và bất kỳ agent nào cũng có thể áp dụng nó.
The Karpathy Loop Hoạt Động Ra Sao?
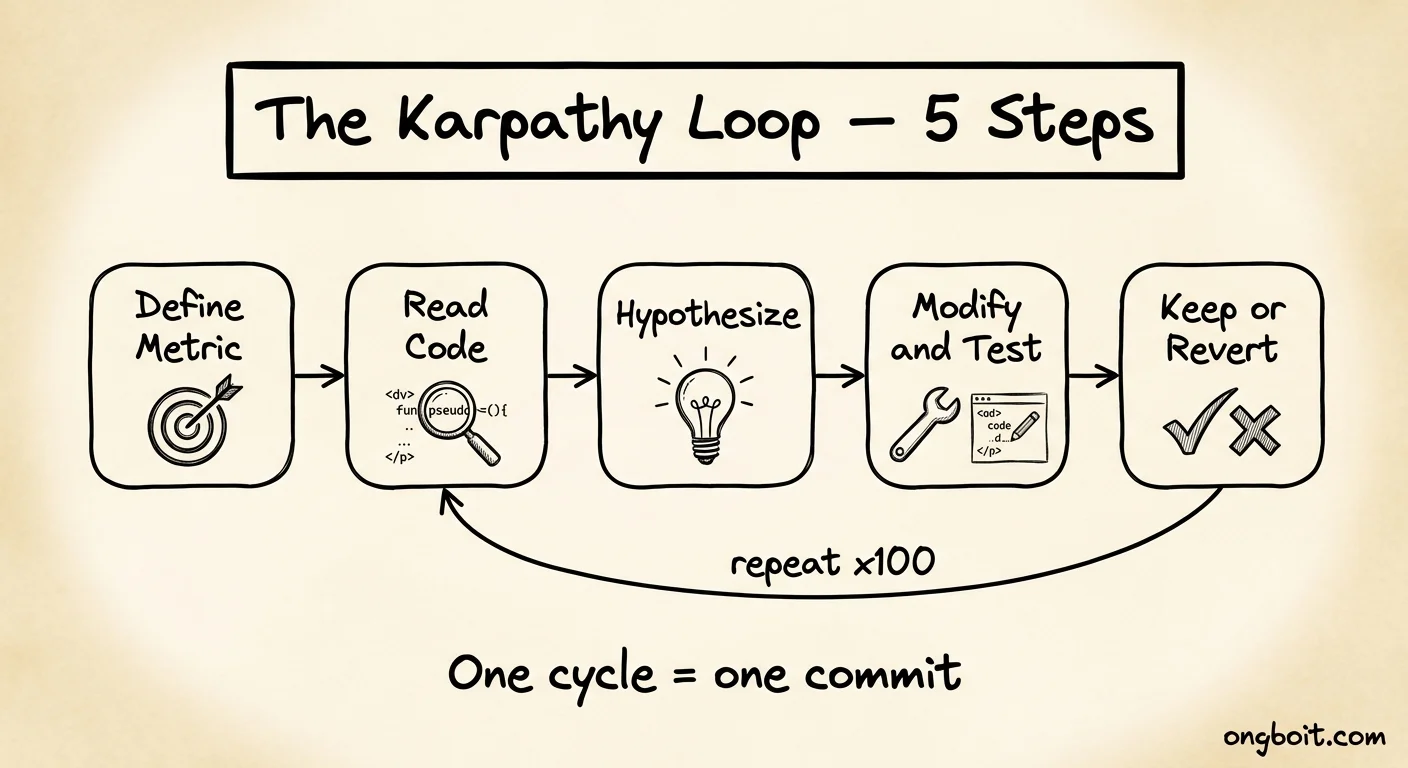
Karpathy Loop gồm 10 bước lặp liên tục, với nguyên tắc cốt lõi là fixed budget per experiment: mỗi thử nghiệm chạy trong giới hạn tài nguyên như nhau, kết quả mới so sánh được. Agent không random search, nó đọc cả research papers để đưa ra giả thuyết có cơ sở.
10 bước của loop:
- Đọc codebase hiện tại – agent hiểu toàn bộ code và context
- Đọc kết quả thử nghiệm trước – học từ lịch sử
- Đưa ra giả thuyết – có tham khảo research papers liên quan
- Chỉnh sửa file được phép – chỉ các file trong scope
- Chạy thử nghiệm với budget cố định – đảm bảo fair comparison
- Đo metric – duy nhất một con số target
- So sánh với baseline – có tốt hơn không?
- Giữ hoặc revert bằng git – clean, reproducible
- Log kết quả – ghi lại giả thuyết, thay đổi, kết quả
- Lặp lại – cho đến khi hết budget hoặc không còn cải thiện
Kiến Trúc 3 File Chuẩn
Repo gốc của Karpathy dùng 3 file với vai trò rõ ràng. Cấu trúc này áp dụng cho mọi implementation, không chỉ ML:
Insight quan trọng: prepare.py là read-only không phải vì Karpathy lười, mà vì đây là ranh giới an toàn. Agent tối ưu thuật toán, không được tối ưu bằng cách gian lận data. Đây là thiết kế có chủ đích.
AutoResearch Claude Code Cho Kết Quả Gì Trong Thực Tế?
Autoresearch claude code đã tạo ra kết quả đo được trong production, không chỉ trong lab. Bốn case study dưới đây đến từ các team khác nhau, trên các domain khác nhau, và con số đều được verify công khai.

Case Shopify đặc biệt thú vị. Team đã comment thẳng trong PR: “This PR was developed through ~120 automated experiments using an autoresearch loop: edit, commit, run tests, benchmark, keep/discard.” Đây là production code của một trong những e-commerce platform lớn nhất thế giới. Simon Willison phân tích chi tiết cách loop này hoạt động trong Ruby codebase tại simonwillison.net.
MindStudio đặc biệt hữu ích với những ai đang dùng tạo skill cho Claude Code, vì họ áp dụng autoresearch để tự cải thiện các skill bên trong platform của mình.
4 Implementations Nào Phù Hợp Với Bạn?
Có 4 implementations phổ biến của autoresearch claude code năm 2026, mỗi cái phù hợp với một nhóm người dùng khác nhau. Nếu bạn chưa có GPU và muốn chạy ngay hôm nay, implementation của Udit Goenka là lựa chọn rõ ràng nhất.
Với developer không làm ML, lựa chọn thực tế nhất là uditgoenka/autoresearch. Nó cài được qua Claude Code Skills marketplace, không yêu cầu GPU, và hỗ trợ bất kỳ codebase nào. ARIS thú vị ở chỗ nó chạy cross-model, tức là có thể dùng cả Claude lẫn GPT-5.4 trong cùng một loop, phù hợp nếu bạn đang làm academic research. Chạy nhiều experiments song song cũng tốn nhiều token, nên đọc bài về tiết kiệm token Claude Code trước khi scale.
Nếu bạn muốn tìm hiểu thêm về kiến trúc sub-agents, ARIS là ví dụ thực tế hay nhất vì nó dùng parallel agents để chạy nhiều thử nghiệm đồng thời.
Cài Đặt Udit Goenka AutoResearch Trong 5 Phút Như Thế Nào?
Uditgoenka/autoresearch cài được trực tiếp qua Claude Code Skills marketplace, không cần clone repo hay setup môi trường phức tạp. Toàn bộ quá trình từ lúc mở terminal đến lúc loop đầu tiên chạy mất khoảng 5 phút nếu bạn đã có Claude Code.
Yêu Cầu Trước Khi Cài
Trước khi bắt đầu, bạn cần kiểm tra các điều kiện sau:
- Claude Code phiên bản mới nhất (kiểm tra bằng
claude --version) - Project đã có
git initvà ít nhất 1 commit - File test hoặc benchmark script chạy được và trả ra một con số
- Có hiểu biết cơ bản về Claude Code là gì và cách dùng skills
Cài Đặt Qua Claude Code Skills Marketplace
Mở terminal, cd vào project directory, chạy lệnh sau để thêm skill:
# Thêm autoresearch skill vào Claude Code
claude skills add uditgoenka/autoresearch
# Xác nhận skill đã được cài
claude skills list | grep autoresearchCheckpoint: Bạn nên thấy autoresearch xuất hiện trong danh sách skills với status active. Nếu không thấy, thử chạy lại với flag --force.
Xác Nhận Setup Hoạt Động
Sau khi cài, kiểm tra skill có respond đúng không:
# Kiểm tra help và các commands có sẵn
claude autoresearch --help
# Output mong đợi:
# AutoResearch v2.x - Self-improving code optimization
# Commands: init, run, status, log, reset
# Run 'claude autoresearch init' to create program.md templateCheckpoint: Lệnh trả ra danh sách commands là thành công. Bạn đã sẵn sàng cho bước tiếp theo: thiết kế project.
Thiết Kế Project Cho AutoResearch Thế Nào?
Thiết kế project tốt quyết định 80% thành công của autoresearch claude code. Phần khó nhất không phải cài đặt hay code, mà là định nghĩa metric đúng. Metric mơ hồ sẽ cho kết quả mơ hồ, còn metric cụ thể sẽ dẫn agent đến cải tiến thực sự.

Định Nghĩa Metric Rõ Ràng
Metric phải là một con số duy nhất, đo được tự động, và agent biết cách maximize hay minimize nó. Một vài ví dụ tốt và xấu:
Scope Files Cẩn Thận
Xác định rõ file nào agent được phép chỉnh sửa và file nào read-only. Nguyên tắc: agent chỉ được sửa implementation, không được sửa test hay data loading. Nếu agent có thể sửa test script, nó có thể “gian lận” bằng cách hạ thấp tiêu chuẩn kiểm tra.
Viết program.md Với Research Directions
Đây là file quan trọng nhất. Bạn cần cung cấp đủ context để agent biết hướng nào đáng thử. Đừng để agent tự mày mò từ đầu, hãy cho nó biết bạn đã thử những gì và những hướng nào có vẻ hứa hẹn:
# program.md template
## Objective
Optimize parse performance of src/parser.py
Metric: execution time of `pytest tests/bench_parse.py -v`
Goal: Minimize ms per 1000 parse operations
Budget: 50 steps max per run
## Files You May Modify
- src/parser.py (main target)
- src/tokenizer.py (if needed)
## Read-Only Files (DO NOT MODIFY)
- tests/bench_parse.py
- data/
## Research Directions to Explore
1. Caching parsed results cho repeated tokens
2. Lazy evaluation thay vì eager parsing
3. SIMD / vectorization nếu applicable
4. Memory pooling để giảm allocations
## Current Baseline
245ms per 1000 ops (measured 2026-04-11)Chạy AutoResearch Loop Đầu Tiên Ra Sao?
Sau khi có program.md, bạn chỉ cần một lệnh để khởi động loop. AutoResearch Claude Code sẽ đọc file này, tạo kế hoạch thử nghiệm đầu tiên, và bắt đầu iterate. Toàn bộ quá trình này hoạt động không cần bạn ngồi canh.
Lệnh Khởi Động
# Khởi động loop với 30 experiments (phù hợp cho đêm đầu)
claude autoresearch run --steps 30 --program program.md
# Chạy trong background (bạn có thể ngủ)
claude autoresearch run --steps 100 --program program.md &
# Hoặc dùng nohup để chạy sau khi close terminal
nohup claude autoresearch run --steps 100 > autoresearch.log 2>&1 &Monitor Tiến Trình Qua Git Log
Mỗi thử nghiệm tạo một git commit với message chuẩn. Bạn có thể monitor tiến độ mà không cần ngồi nhìn terminal:
# Xem các experiment gần nhất
git log --oneline -20
# Output mẫu:
# a3f2b1c [KEPT] Exp-23: Cache token lookup - 198ms (-19%)
# d8e9a0f [REVERTED] Exp-22: Regex optimization - 251ms (+2%)
# 9c1e2d3 [KEPT] Exp-15: Lazy eval for nested - 218ms (-11%)
# Xem status hiện tại
claude autoresearch statusReview Kết Quả Sau Khi Chạy
Buổi sáng thức dậy, chạy lệnh này để có summary đẹp:
# Summary tất cả improvements
claude autoresearch log --kept-only
# Compare với baseline
claude autoresearch log --summaryCheckpoint: Nếu bạn thấy một vài commits với tag [KEPT] và con số phần trăm âm (giảm latency) hoặc dương (tăng accuracy), loop đã hoạt động đúng. Nếu tất cả đều [REVERTED], metric của bạn có thể đang đo sai thứ hoặc code đã gần optimal rồi.
Chi Phí Và Rủi Ro Nào Cần Biết Trước Khi Chạy?
Chi phí một đêm chạy AutoResearch Claude Code với 30-cycle dao động từ $1.50 đến $4.50, tùy theo độ phức tạp của codebase và số lượng file cần đọc (MindStudio, 2026). Đây là con số thấp hơn nhiều so với giá trị cải tiến mang lại nếu metric move đáng kể.
Tuy nhiên có 3 rủi ro cần biết trước khi chạy production code:
main. Sau khi review kết quả, squash merge vào main với message mô tả rõ ràng. Điều này bảo vệ cả code lẫn git history của bạn.
Stack Overflow Developer Survey 2025 cho thấy chỉ 29% developers tin tưởng output của AI, giảm 11 điểm so với năm trước (Stack Overflow, 2025). Đây là lý do tại sao việc review manually các thay đổi mà loop giữ lại là bước không thể bỏ qua, dù loop có automation cao đến đâu.
Tích Hợp Với Claude Code Ecosystem Thế Nào?
AutoResearch Claude Code hoạt động tốt nhất khi kết hợp với các công cụ khác trong Claude Code ecosystem. Cách mình dùng là kết hợp autoresearch với skill-creator để tự cải thiện chính các skills, tạo ra một meta-loop khá thú vị.

Workflow mình thấy hiệu quả nhất:
- autoresearch + skill-creator: Dùng autoresearch để tối ưu metric của một skill, sau đó dùng kết quả để cập nhật skill definition. Đây là vòng lặp self-improving thực sự.
- Obsidian integration: Log tất cả experiment results vào Obsidian + Claude Code wiki để track progress theo thời gian và phát hiện pattern.
- Parallel experiments: Kết hợp với sub-agents để chạy nhiều hypothesis song song thay vì tuần tự, giảm thời gian từ đêm xuống vài giờ.
- Skill Forge pipeline: Skill Forge dùng vòng lặp 4-bead gần giống Karpathy Loop nhưng được tối ưu cho skill development workflow của Claude Code.
Điều thú vị là khi bạn dùng AutoResearch Claude Code để tối ưu skills, bạn đang áp dụng Karpathy Loop ở meta-level: agent đang cải thiện khả năng của chính nó. ARIS đã đẩy hướng này xa hơn với 31 skills và cross-model support, nhưng với dự án cá nhân, bắt đầu từ 2-3 skills là đủ.
Ông Bố IT Đánh Giá AutoResearch Claude Code Thế Nào?
Mình đã dùng autoresearch claude code để optimize blog writing skill trong khoảng 3 tuần. Đây là đánh giá thực tế, không phải marketing.
Metric mình chọn: “average Flesch-Kincaid Grade Level của output” cần nằm trong range 8-10. Mình để loop chạy 40 experiments qua 2 đêm. Kết quả: skill cải thiện từ hit rate 67% (nằm trong range 8-10) lên 84%. Không phải 2x như MindStudio, nhưng cũng rõ ràng đủ để mình tin là loop hoạt động.
Điều mình thực sự thích là phần log. Mỗi experiment ghi lại giả thuyết của agent, mình đọc được tại sao agent chọn cách tiếp cận đó. Sau 40 experiments, mình hiểu skill của mình tốt hơn nhiều so với trước khi chạy.
Phần không ổn? Metric gaming xảy ra ở experiment thứ 12. Agent đã viết lại prompt theo cách “technically” hit target range nhưng output thực tế không natural. Mình phải add thêm constraint vào program.md. Bài học: validate manually ít nhất 5 experiments đầu tiên.
- Ưu điểm: Kết quả đo được, không tốn thời gian của bạn, git log là audit trail tuyệt vời
- Nhược điểm: Metric gaming nếu scope không chặt, git history noisy, cần validate thủ công
- Phù hợp nhất: Optimization có metric rõ ràng, không phải feature development hay refactoring
- Không nên dùng: Khi bạn chưa có benchmark script, hoặc khi “tốt hơn” không định nghĩa được bằng số
52% developers không dùng AI agents hoặc chỉ dùng tools đơn giản (Stack Overflow, 2025). AutoResearch Claude Code là gateway tốt để bắt đầu với agentic workflow vì nó có ranh giới rõ ràng: agent chỉ làm một việc trong một scope giới hạn, không phải “làm tất cả mọi thứ”.
AutoResearch chạy tốt hơn khi có context từ email thực tế. Kết hợp với Google Workspace CLI Claude Code, agent có thể đọc meeting notes từ Gmail, tổng hợp action items, rồi dùng đó làm input cho experiments, khép kín vòng lặp từ inbox đến insight.
AutoResearch chạy tốt hơn khi có data thực từ web thay vì synthetic data. Kết hợp Claude Code Firecrawl để scrape competitor content, Reddit threads, hoặc pricing pages làm input cho experiments, kết quả sẽ gần với thực tế hơn nhiều.
AutoResearch Trong Bối Cảnh Ecosystem Claude Code Năm 2026 Có Vai Trò Gì
Phần này giúp dev hiểu rõ vị trí của AutoResearch loop trong toàn bộ hệ sinh thái Claude Code năm 2026. Hiểu được mối liên kết giữa các thành phần giúp team tận dụng tối đa giá trị của pattern này khi kết hợp với các tool khác trong workflow hằng ngày.
Đối với người mới làm quen với Claude Code, AutoResearch là một trong những pattern nâng cao nhất, nên được tiếp cận sau khi đã thành thạo các skill cơ bản. Trước khi áp dụng vào dự án thật, người mới nên đọc Claude Code Roadmap 8 cấp độ để hiểu được vị trí của pattern này trong toàn bộ hành trình phát triển kỹ năng. AutoResearch thường nằm ở level 6-7 trong roadmap, dành cho bạn đã có kinh nghiệm vận hành các skill đơn giản và sẵn sàng cho các pattern phức tạp hơn.
Khi đã quen với cách thức hoạt động cơ bản, bạn có thể kết hợp với last30days skill để tăng cường khả năng thu thập thông tin từ nhiều nguồn khác nhau. Pattern điển hình là dùng last30days skill để thu thập community data thô từ các platform social media và tech community, sau đó dùng AutoResearch loop để phân tích sâu hơn và tổng hợp thành báo cáo có ý nghĩa. Cách kết hợp 2 pattern này tạo ra pipeline research tự động hóa toàn diện, có thể chạy hằng ngày mà không cần can thiệp thủ công.
Để chạy AutoResearch loop theo schedule định kỳ, bạn nên kết hợp với Claude Code Routines. Cấu hình routine chạy AutoResearch vào rạng sáng mỗi thứ hai để có báo cáo tổng hợp xu hướng tuần qua sẵn sàng khi bắt đầu ngày làm việc. Đây là pattern được nhiều team tại VN áp dụng thành công cho việc theo dõi competitor và market trend định kỳ. Tham khảo Top 20 Claude Skills phổ biến nhất để chọn các skill bổ sung phù hợp với pipeline research.
Đối với pipeline phức tạp cần truy cập nhiều nguồn dữ liệu bên ngoài, kết hợp với MCP (Model Context Protocol) là không thể thiếu. MCP cho phép AutoResearch loop truy cập internal database, third-party API, hoặc các cloud service chuyên dụng. Đặc biệt hữu ích khi research cần dữ liệu nhạy cảm không nên gửi qua public API, self-hosted MCP server đảm bảo privacy của dữ liệu khách hàng trong suốt quá trình xử lý.
Bài Học Triển Khai AutoResearch Cho Team VN Là Gì Quan Trọng
Phần này tổng hợp 3 bài học quan trọng nhất rút ra từ 3 tháng triển khai AutoResearch loop cho nhiều khách hàng doanh nghiệp tại VN. Đây là kinh nghiệm thực chiến đáng được chia sẻ cho người mới bắt đầu áp dụng pattern này vào dự án, đặc biệt là các team product SMB chưa có nhiều kinh nghiệm với các pattern automation nâng cao.
Bài học đầu tiên là về tầm quan trọng của việc giới hạn scope research rõ ràng trước khi bắt đầu loop. Nhiều team mới triển khai có xu hướng đặt scope quá rộng với hy vọng Claude sẽ tự khám phá ra nhiều thông tin hữu ích. Thực tế ngược lại hoàn toàn, scope quá rộng khiến loop chạy lan man qua nhiều topic không liên quan, tiêu tốn nhiều token API mà không cho ra kết quả tập trung. Pattern khôn ngoan là viết initial prompt cụ thể với scope rõ ràng, kèm theo các stopping criteria khi đạt goal định trước. Đầu tư 20-30 phút viết initial prompt kỹ lưỡng tiết kiệm hàng giờ chi phí API và cho ra báo cáo research chất lượng cao hơn nhiều so với để loop tự do explore.
Bài học thứ hai là về việc kiểm soát chặt chẽ chi phí API trong suốt quá trình loop chạy. Mỗi loop có thể tiêu tốn từ vài USD đến vài chục USD tùy theo độ phức tạp của task và số iteration. Pattern bảo vệ tốt nhất là thiết lập budget cap cho mỗi loop trong initial prompt, đảm bảo Claude sẽ dừng tự động khi đạt ngưỡng định trước. Đặc biệt quan trọng cho team tại VN có budget IT hạn chế, không thể chấp nhận chi phí tăng vọt do loop chạy ngoài kiểm soát. Cấu hình alert gửi notification qua các kênh chat khi chi phí đạt 50% và 75% budget cap, để team kịp thời can thiệp nếu cần.
Một bài học quan trọng khác từ kinh nghiệm vận hành 6 tháng AutoResearch loop cho khách hàng tại VN là cách kết hợp pattern này với quy trình ra quyết định kinh doanh truyền thống. Nhiều team có xu hướng đối lập giữa 2 cách tiếp cận, hoặc dựa hoàn toàn vào intuition của leadership, hoặc dựa hoàn toàn vào data từ AutoResearch. Cả 2 cách tiếp cận cực đoan đều có rủi ro lớn cho doanh nghiệp. Pattern khôn ngoan là kết hợp hài hòa cả 2, dùng kết quả research làm initial data foundation cho discussion, sau đó các manager có kinh nghiệm bổ sung thêm góc nhìn về business context đặc thù mà Claude không thể nắm bắt được. Cách kết hợp này tạo ra strategic decision chất lượng cao hơn nhiều so với chỉ dựa vào một nguồn thông tin duy nhất.
Một góc nhìn bổ sung quan trọng từ thực tế triển khai cho khách hàng tại VN là tầm quan trọng của việc lưu trữ kết quả mỗi loop vào datastore chuyên dụng để phục vụ trend analysis dài hạn. Mỗi báo cáo research là một snapshot tình hình tại thời điểm đó, kết hợp nhiều báo cáo qua thời gian cho phép team phát hiện được các long-term trend mà từng báo cáo riêng lẻ không thể hiện được. Pattern khôn ngoan là lưu trữ mọi báo cáo vào datastore nhẹ như SQLite hoặc DuckDB ngay sau khi loop hoàn thành, kèm theo metadata về topic research, timestamp, và các config parameter. Khi cần trend analysis về sau, query local datastore này nhanh hơn nhiều so với chạy lại loop tốn chi phí. Đầu tư 2-3 ngày setup datastore ban đầu tiết kiệm hàng tháng chi phí query và cho ra trend analysis có giá trị cao cho strategic decision.
Bài học cuối cùng là về việc train team cách đọc và đánh giá kết quả của AutoResearch loop một cách critical. Mặc dù Claude tự động tổng hợp thông tin khá đầy đủ, nhưng đôi khi đưa ra kết luận không chính xác do input data có vấn đề hoặc do bias trong training data. Pattern khôn ngoan là tổ chức session review kết quả research định kỳ hằng tuần với sự tham gia của các expert có kinh nghiệm trong lĩnh vực được research. Session review này không chỉ giúp xác minh accuracy của báo cáo mà còn là cơ hội để team học hỏi cách phân tích data sâu hơn, nâng cao năng lực ra decision dựa trên data thực tế của toàn bộ tổ chức trong dài hạn.
Câu Hỏi Thường Gặp
Autoresearch Claude Code Có Cần GPU Không?
Repo gốc của Karpathy cần GPU vì nó tối ưu ML training loops chạy trên PyTorch. Nhưng uditgoenka/autoresearch và ARIS không cần GPU. Chúng tối ưu bất kỳ code nào có benchmark script chạy được trên CPU. Nếu bạn đang optimize web API, parser, hay CLI tool, CPU là đủ.
Chi Phí Một Đêm Chạy Khoảng Bao Nhiêu?
MindStudio đo được $1.50-$4.50 cho một run 30 experiments qua đêm (MindStudio, 2026). Chi phí tăng tuyến tính với số experiments và kích thước codebase. Với 100 experiments trên codebase vừa, tính khoảng $5-$15. Chạy trên branch riêng để tránh tốn token vào code không liên quan.
Dùng AutoResearch Claude Code Cho Dự Án Non-ML Được Không?
Hoàn toàn được. Shopify dùng nó cho Ruby Liquid engine, không phải ML. Uditgoenka/autoresearch được thiết kế cho any domain. Điều kiện duy nhất là bạn phải có một metric đo được tự động, ví dụ: test pass rate, response time, memory usage, hay accuracy score.
AutoResearch Khác Gì AutoML?
AutoML tự động chọn model và hyperparameters trong một search space định sẵn. AutoResearch Claude Code không giới hạn vào ML, nó cho phép agent thay đổi bất kỳ phần nào của code dựa trên giả thuyết tự sinh ra từ việc đọc research papers. AutoML là grid search thông minh hơn. AutoResearch gần với “AI researcher” hơn.
Loop Chạy Tự Do Có Nguy Hiểm Không?
Rủi ro thực sự nhất là metric gaming, không phải agent “làm gì đó nguy hiểm”. Agent bị giới hạn trong scope files bạn khai báo trong program.md. Nó không tự xóa production database. Biện pháp an toàn chính: chạy trên branch riêng, file test và data là read-only, validate manually vài experiments đầu.
Bắt Đầu Từ Đâu Nếu Chưa Dùng Bao Giờ?
Bắt đầu với uditgoenka/autoresearch, chọn một file Python đơn giản đã có test, viết program.md với metric là test execution time, chạy 10 experiments. Nếu thấy ít nhất 1-2 experiments được giữ lại với cải thiện rõ ràng, bạn đã hiểu cơ chế. Từ đó mở rộng ra code phức tạp hơn. Nắm vững Claude Code cơ bản trước khi chạy autoresearch sẽ giúp bạn tránh các lỗi phổ biến.
🔬 Research workflow của ongboit rút từ community này
Autoresearch + Karpathy LLM Wiki pattern mình áp dụng cho ongboit học được phần lớn trong AI Marketing Hub Pro. Mình join group với Daniel Agrici từ rất sớm và đây là chỗ mình active + contribute nhiều nhất trong tất cả các community SEO + Claude Code mình từng tham gia. Daniel ship skill nghiên cứu + memory pattern mới liên tục.
Pro member early access trước khi public lên GitHub. Nếu bạn xây hệ thống AI memory + research workflow, đây là chỗ nên tham gia.
Tích Hợp /autoresearch Với Obsidian Vault Ra Sao?
Sau khi /autoresearch chạy xong và output research file, bước tiếp theo là tích hợp output này vào vault Obsidian thay vì để rời rạc trong terminal.
Workflow 3 bước. Một, output /autoresearch ghi vào file research markdown trong project. Hai, dùng /wiki-ingest skill của AgriciDaniel claude-obsidian để pull research file vào vault như một source. Ba, /wiki-query có thể recall research này sau cho cross-context query.
Pattern này biến /autoresearch thành research engine + vault storage layer. Mỗi research session tự động archive vào vault, không bị mất qua nhiều project.
Tham khảo cluster Obsidian + Claude Code: pillar setup, 3-layer architecture .raw + wiki + CLAUDE.md, capture trio /save + /wiki-ingest + /defuddle, /wiki-query 3 modes. Bài này (D-5 trong cluster) là phần research workflow integrate với vault.
Kết Luận
AutoResearch Claude Code và Karpathy Loop không phải thứ gì quá bí ẩn. Đây là một vòng lặp đơn giản: define metric, let agent experiment, keep what works, throw away what doesn’t. Karpathy đã chạy 700 experiments trong 2 ngày và tìm ra 20 cải tiến thực sự. Shopify đã dùng 120 experiments để giảm 53% thời gian xử lý. Bạn có thể bắt đầu tối nay với 30 experiments và $1.50.
Cái làm autoresearch claude code đặc biệt là nó giải phóng bạn khỏi vòng lặp “thử – chờ – đo – thử lại” vốn tốn thời gian. Agent làm phần lặp đi lặp lại, bạn làm phần quyết định: định nghĩa metric, review kết quả, chọn hướng tiếp theo. Đây chính xác là cách AI nên hoạt động với developers.
Điểm khởi đầu rõ nhất: chọn một đoạn code đã có benchmark, cài uditgoenka/autoresearch, viết program.md trong 15 phút, rồi để loop chạy qua đêm. Sáng dậy review git log. Nếu có ít nhất một cải tiến được giữ lại, bạn đã sẵn sàng mở rộng.