Schema không đưa bài bạn lên top. Nhưng thiếu nó, máy đọc bài bạn như đọc một khối văn bản trơn.
TL;DR: Schema markup là đoạn mã JSON-LD gắn vào trang để nói cho máy biết chính xác nội dung là gì: đây là bài viết, kia là giá sản phẩm, nọ là câu hỏi thường gặp. Nó KHÔNG làm tăng thứ hạng, và study mới nhất đo trên 1.885 trang cho thấy nó cũng không làm tăng AI citation. Đổi lại, nó mở cửa rich results (sao, giá, FAQ xổ xuống ngay trên kết quả tìm kiếm) và giúp Google nhận diện thực thể của bạn. Với WordPress, Rank Math gắn schema nền tự động; cần thêm loại nào thì vào tab Schema của bài viết, chọn type, điền, rồi kiểm tra bằng Rich Results Test. Tuyệt đối đừng inject schema qua REST API meta: site này từng sập WP admin vì đúng thao tác đó.
Bạn cài Rank Math xong, nghe nói phải gắn schema. Gắn rồi, check Rich Results Test pass xanh, mà tuần sau nhìn lại chẳng thấy gì thay đổi. Rồi bạn đọc được hai luồng ngược nhau: chỗ này bảo “schema giúp AI cite bài bạn”, chỗ kia bảo “schema chết rồi, đừng phí công”. Trước khi chọn phe, đáng để xem con số thật: tháng 5/2026 vừa có một nghiên cứu đo đúng câu hỏi này trên gần 2.000 trang, và kết quả của nó sẽ làm cả hai phe khó chịu. Các bài hướng dẫn tiếng Việt hiện tại vẫn đang dạy một chiều “gắn schema để tăng traffic”, chưa bài nào đem số liệu đó vào, nên bài này tồn tại để bù đúng chỗ trống ấy.
Mình viết từ vị trí người dùng Rank Math hằng ngày trên chính blog này, kèm một sự cố thật: một lần setup schema sai đường làm sập trang quản trị WordPress trong vài phút. Sự cố đó dạy mình nhiều hơn mọi bài hướng dẫn, và nó nằm ở phần setup bên dưới.
Schema markup là gì?
Hình dung trang khách sạn Đà Nẵng của bạn ghi “1.200.000đ/đêm, 4,8 sao, còn phòng ngày 20/6”. Người đọc hiểu ngay. Nhưng với máy, đó chỉ là một chuỗi ký tự, nó phải ĐOÁN đâu là giá, đâu là điểm đánh giá, đâu là ngày. Đoạn mã nhỏ gắn vào trang để khai báo thẳng “1.200.000đ là GIÁ phòng, 4,8 là ĐIỂM trên thang 5, 20/6 là NGÀY còn phòng”, để máy khỏi đoán, chính là schema markup, còn gọi là dữ liệu có cấu trúc (structured data). Ví dụ kinh điển của Semrush: schema nói rõ cho máy biết “$299 là giá của đúng sản phẩm này” thay vì để máy tự suy.
Bộ từ vựng chuẩn cho việc khai báo này nằm ở schema.org, dự án chung của Google, Microsoft và các search engine lớn. Quy mô của nó nói thay độ phổ biến: theo schema.org community stats, tính đến 2024 đã có hơn 45 triệu domain gắn schema markup với hơn 450 tỷ object được đánh dấu. Định dạng Google khuyến nghị là JSON-LD: một khối <script> nhỏ đứng riêng trong trang, không đụng vào HTML hiển thị, nên gắn hay gỡ không ảnh hưởng người đọc.
Trông nó thế này, đúng ví dụ khách sạn ở trên, 8 dòng là đủ một schema Product hợp lệ:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Product",
"name": "Phòng Deluxe, Khách sạn ABC Đà Nẵng",
"offers": { "@type": "Offer", "price": "1200000", "priceCurrency": "VND" },
"aggregateRating": { "@type": "AggregateRating", "ratingValue": "4.8", "reviewCount": "127" }
}
</script>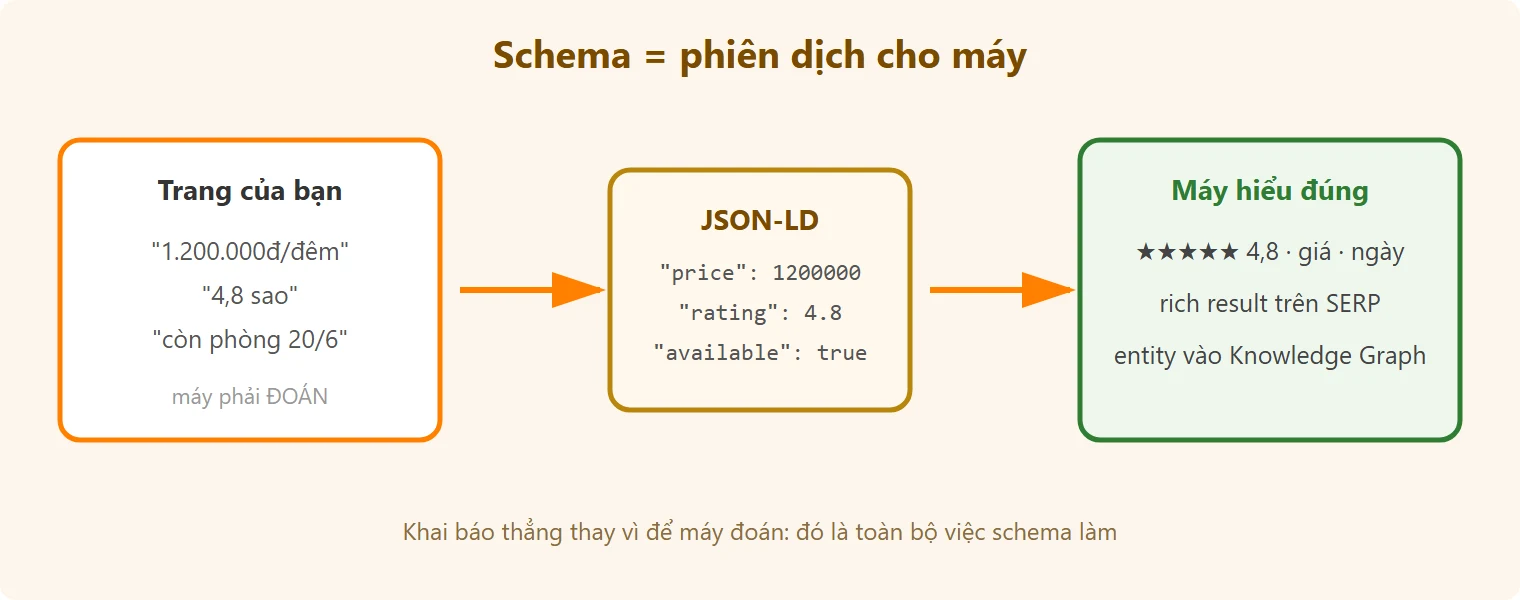
Một nhầm lẫn rất Việt Nam cần dẹp sớm: gõ “schema là gì” ra Google, nửa kết quả nói về database schema, tức lược đồ cơ sở dữ liệu trong SQL. Cùng chữ, khác nghề. Database schema là bản thiết kế bảng-cột cho lập trình viên; schema markup là khai báo nội dung cho search engine. Bài này chỉ nói loại thứ hai.
Schema có giúp tăng rank không?
Không, và đây là chỗ đa số bài tiếng Việt đang nói quá. Google qua John Mueller đã xác nhận thẳng: structured data không làm site rank tốt hơn (Search Engine Journal). Niềm tin “gắn schema để lên top” sống dai vì các site gắn schema chỉn chu thường cũng là site làm content tử tế: thứ hạng đến từ content, schema chỉ đứng cạnh hưởng tiếng thơm.
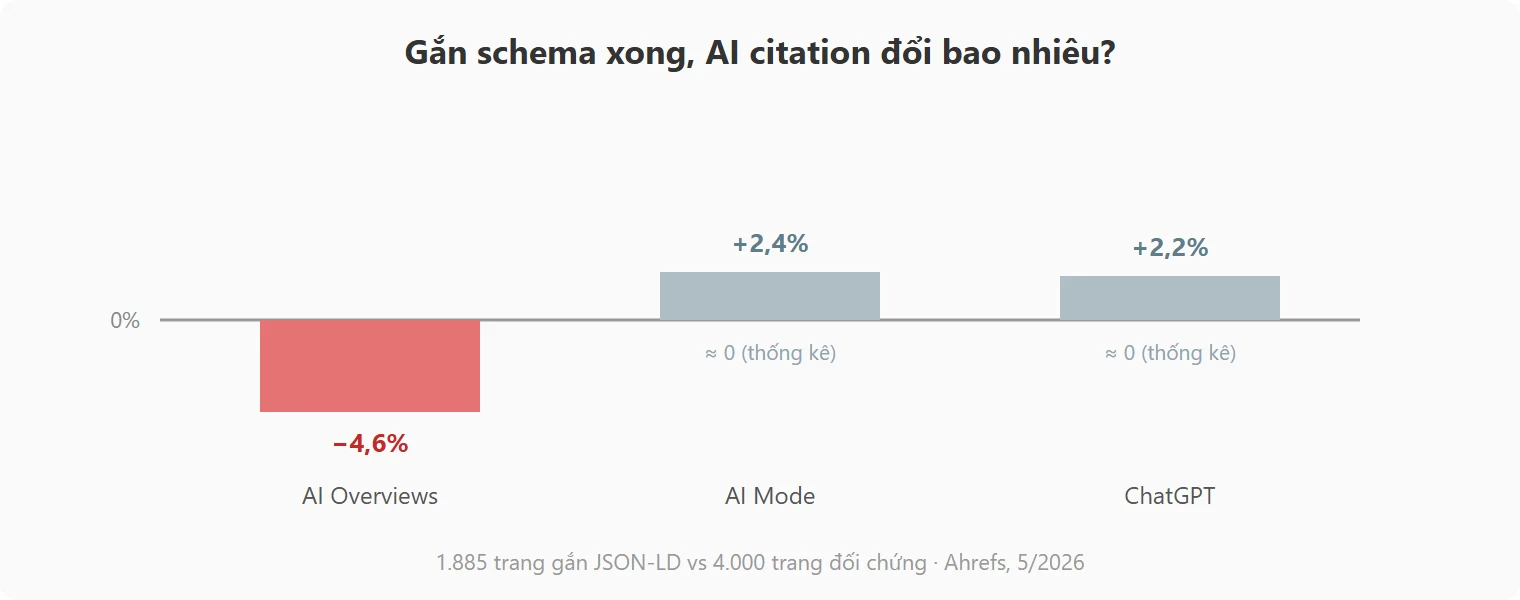
Còn câu hỏi nóng hơn của 2026, “schema có giúp được AI cite không?”, giờ đã có số để trả lời. Nghiên cứu của Ahrefs công bố 11/5/2026 của Louise Linehan và Xibeijia Guan theo dõi 1.885 trang bắt đầu gắn JSON-LD trong khoảng 8/2025 đến 3/2026, so với 4.000 trang đối chứng không gắn, đo bằng phương pháp difference-in-differences:
| Nền tảng | Thay đổi citation sau khi gắn schema | Đọc thế nào |
|---|---|---|
| Google AI Overviews | −4,6% | Giảm nhẹ, có ý nghĩa thống kê |
| Google AI Mode | +2,4% | Không phân biệt được với 0 |
| ChatGPT | +2,2% | Không phân biệt được với 0 |
Kết luận của nhóm nghiên cứu: gắn schema không làm tăng citation trên bất kỳ nền tảng nào. Họ cũng trung thực về giới hạn: study chỉ đo các trang vốn đã được cite nhiều, gộp mọi loại schema làm một, và cửa sổ đo 30 ngày khá ngắn. Nghĩa là nó chưa nói gì về trang MỚI chưa từng được AI biết đến, nơi schema có thể vẫn giúp khâu crawl và index ban đầu.

Hai mảnh ghép nữa làm bức tranh rõ hẳn. Thứ nhất, thí nghiệm của Mark Williams-Cook, dẫn trong guide schema của Ahrefs: ông bịa một địa chỉ trong schema, và ChatGPT lẫn Perplexity lặp lại địa chỉ bịa đó y như đọc văn bản thường. LLM đang đọc schema như TEXT, không phải như dữ liệu ngữ nghĩa. Thứ hai, theo phân tích từ Dejan.ai và một số nghiên cứu độc lập, trong các LLM hiện nay, chỉ Gemini cho thấy dấu hiệu rõ rệt việc dùng structured data để verify thông tin entity qua Google Knowledge Graph – chứ không phải đọc schema như văn bản thuần như các LLM khác.
Vậy schema THẬT SỰ đổi lại cái gì? Ba thứ, đều đáng tiền:
1. Rich results: sao đánh giá, giá, FAQ xổ xuống, breadcrumb đẹp ngay trên trang kết quả. Không tăng hạng, nhưng cùng một vị trí thì kết quả có sao có giá ăn click tốt hơn kết quả chữ trơn. Số đo cụ thể từ Google Search Central: Rotten Tomatoes đo CTR +25% trên 100K trang có structured data; Nestlé đo CTR rich result pages cao hơn +82% so với non-rich pages. 2. Entity rõ ràng: schema Organization và Person giúp Google gom đúng “bạn là ai” vào Knowledge Graph. Đây là đường vòng duy nhất mà schema chạm tới AI: máy hiểu đúng thực thể thì trích dẫn đúng nguồn. 3. Khử mơ hồ: trang có giá, có ngày, có công thức thì khai báo thẳng giúp máy phân loại đúng, đỡ rơi vào nhầm lẫn kiểu “lấy số điện thoại làm giá”.
8 loại schema đáng gắn năm 2026 – chọn cái nào cho website?
Theo schema.org docs, vocabulary hiện có 823 type chính thức (cộng 1.529 properties, 96 enumerations), Google chỉ hỗ trợ một phần nhỏ, và bạn chỉ cần đếm trên một bàn tay. Tổng hợp từ khuyến nghị 2026 của Ahrefs và Semrush:
| Loại | Gắn cho | Vì sao đáng |
|---|---|---|
| Organization | Toàn site (1 lần) | Định danh thương hiệu vào Knowledge Graph; nền cho mọi schema khác |
| Person | Trang tác giả | Tín hiệu E-E-A-T: bài có người thật đứng tên |
| Article | Mỗi bài blog | Khai báo tác giả, ngày đăng, ngày sửa; nền cho mọi bài |
| Product | Trang sản phẩm | Giá, tồn kho, đánh giá lên thẳng kết quả tìm kiếm; AI agent so sánh sản phẩm cũng đọc từ đây |
| LocalBusiness | Doanh nghiệp có địa chỉ | Giờ mở cửa, số điện thoại, bản đồ |
| Recipe | Công thức nấu ăn | Thời gian chuẩn bị, calorie, hình ảnh món ăn |
| Review | Đánh giá sản phẩm/dịch vụ | Sao đánh giá hiển thị trực tiếp SERP |
| Event | Sự kiện có ngày giờ địa điểm | Date, location, ticket info |
Còn FAQ và HowTo thì cần nói thẳng: Google đã cắt giảm mạnh việc hiển thị rich results cho hai loại này từ 2023, trong khi nhiều bài tiếng Việt vẫn dạy “gắn FAQ schema để tăng CTR” như thời 2021. Gắn FAQ schema giờ gần như không còn được xổ câu hỏi trên SERP. Nó còn lại một giá trị mềm: cấu trúc hỏi-đáp rõ ràng cho máy đọc, như Peter Rota lập luận trên LinkedIn (11/2025) rằng bất cứ thứ gì cho thêm ngữ cảnh có cấu trúc đều có ích cho LLM. Quan điểm của mình: FAQ schema xếp cuối danh sách ưu tiên, gắn nếu tiện, đừng kỳ vọng.
Setup schema bằng Rank Math: 7 bước an toàn
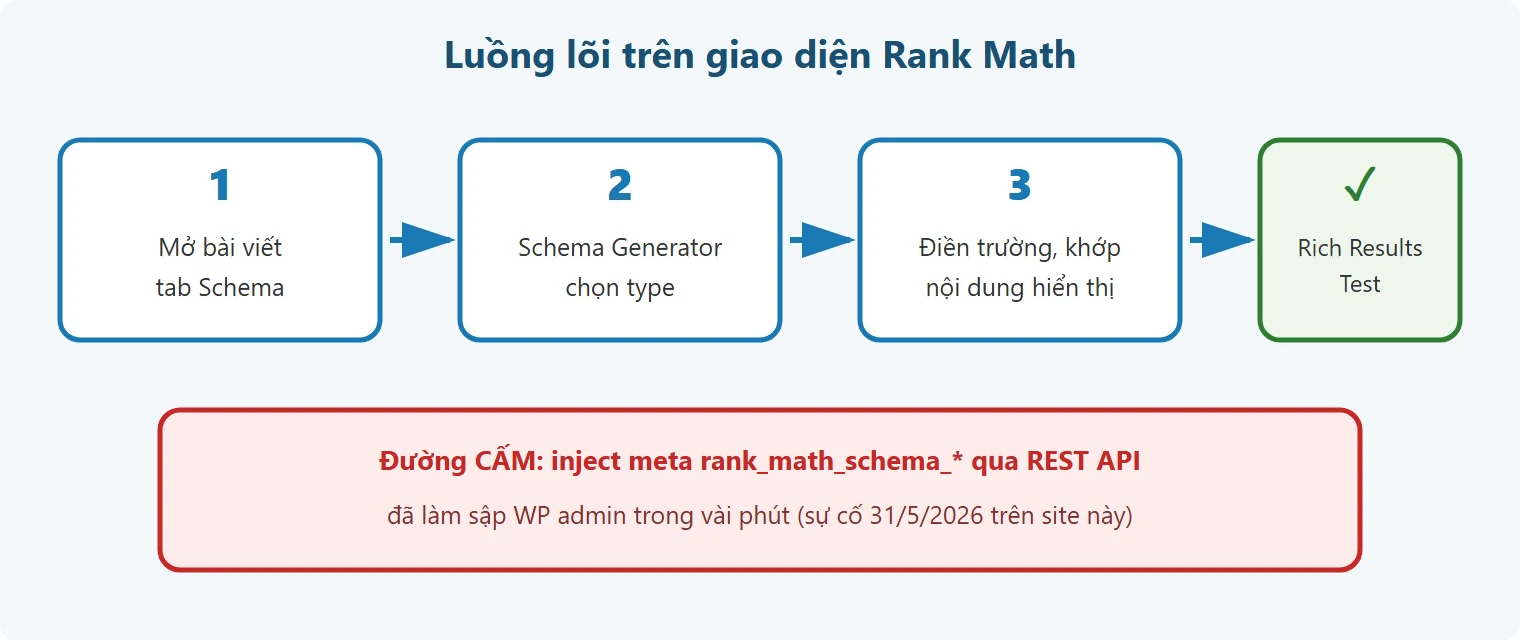
rank_math_schema_* qua REST API (sự cố 31/5/2026).Tin tốt cho người dùng WordPress: cài Rank Math xong là bạn đã có schema nền chạy tự động. Khi setup wizard hỏi site là Organization hay Person, trả lời xong là nó tự gắn schema định danh đó toàn site, kèm Article cho mỗi bài viết. Phần lớn blog chỉ cần đúng mức này.
Khi cần thêm loại schema cho bài cụ thể, quy trình 7 bước:
1. Set default schema type cho post type. Vào Rank Math → Titles & Meta → Posts → Schema Type → chọn “Article” (hoặc BlogPosting). Đây là default cho mọi bài blog mới – bạn không phải set tay từng bài. Bước này ít người làm nhưng quyết định toàn cluster. 2. Mở bài viết → panel Rank Math → tab Schema. Bạn thấy schema đang gắn (thường là Article có sẵn). 3. Schema Generator → chọn type (Product, Recipe, FAQ, HowTo, Review, Event…). Bản PRO mở thêm nhiều type và cho import từ URL khác. 4. Điền các trường bắt buộc. Quy tắc vàng từ tài liệu Google: nội dung khai trong schema phải KHỚP nội dung hiển thị trên trang. Khai sao 5 mà trang không có đánh giá nào là tự rước rủi ro. 5. Verify Author profile. Vào Users → Profile → cuộn xuống Schema → fill bio + social links (Twitter, LinkedIn) + URL. Article schema có field “author” linked tới WP user; Google dùng thông tin này để verify author authority – quan trọng cho E-E-A-T, đặc biệt YMYL. 6. Verify Author URL field. Click Article schema trong tab Schema → xem field “author” có chứa URL profile chính xác (kiểu https://ongboit.com/author/ongboit/). Nhiều người bỏ sót bước này – kết quả là Google không link được author entity. 7. Validate bằng Rich Results Test trước khi publish (chi tiết tool ở phần dưới).
Giờ đến phần mà không bài hướng dẫn nào nói với bạn, vì nó đến từ vết xe đổ của chính mình. Ngày 31/5/2026, mình tự động hóa việc gắn FAQ schema bằng cách inject thẳng meta rank_math_schema_FAQPage qua REST API như cách set custom field thông thường. Kết quả: trang quản trị WordPress sập với lỗi “critical error” khi mở SEO panel. Nguyên nhân kỹ thuật: Rank Math KHÔNG lưu schema trong các trường meta phẳng kiểu đó – nó lưu trong một cấu trúc mảng nội bộ tên rank_math_schemas với ID riêng cho từng schema. Bơm một khối JSON phẳng vào tên trường tưởng-là-đúng làm plugin vỡ khi đọc lại. Không chỉ mình — GitHub issues của Rank Math có nhiều report tương tự cho cùng pattern bypass cấu trúc nội bộ.
Từ sự cố đó, ba đường gắn schema đã kiểm chứng an toàn, xếp theo độ tiện:
- Rank Math UI (7 bước ở trên): an toàn tuyệt đối, plugin tự lo cấu trúc lưu trữ.
- Block FAQ của Rank Math trong Gutenberg: viết FAQ ngay trong editor, schema tự sinh.
- Inline JSON-LD trong content: dán khối
<script type="application/ld+json">vào cuối nội dung bài. Đây là đường duy nhất an toàn khi bạn publish qua REST API hoặc tự động hóa, vì nó không đụng vào meta của plugin. Bài keyword cannibalization trên blog này đang chạy FAQPage theo đúng cách này, bạn có thể view-source kiểm tra.
Nếu bạn cũng publish bài bằng automation như mình: đừng bao giờ ghi vào bất kỳ meta nào bắt đầu bằng rank_math_schema_. Tốn một buổi tối khôi phục đấy.
Làm sao biết schema đã chạy đúng?
Ba công cụ, ba vai, đừng nhầm:
- Rich Results Test: trả lời câu “GOOGLE có đọc được và có cho rich results không?”. Đây là tool chạy đầu tiên, vì nó kiểm theo luật riêng của Google. Pass tool này = ELIGIBLE, không phải SẼ HIỂN THỊ.
- Schema Markup Validator: trả lời câu “schema có ĐÚNG CHUẨN schema.org không?”, không quan tâm luật Google. Dùng khi debug cú pháp hoặc khi gắn type mà Google không hỗ trợ rich results.
- GSC Rich Result Status report: tool authoritative nhất vì phản ánh trạng thái thật Google đã crawl. Vào Search Console → Enhancement → chọn loại schema (Article, FAQ, HowTo…). Report cho biết bao nhiêu URL có schema, bao nhiêu URL có error trong production. Đợi 4-6 tuần sau publish trước khi expect thấy data.
Workflow timeline thực tế áp dụng trên ongboit: sau khi publish bài mới có schema, mình check Rich Results Test ngay (Day 0). 1 tuần sau, mình check GSC Rich Result report để xem Google đã crawl + parse schema chưa. Sau 4-6 tuần, mình check SERP thật bằng cách search query bài và xem có hiện rich result không. Không có shortcut cho timeline này – Google crawl chậm.
Pass tool xong, còn một bẫy âm thầm đáng biết: AI crawler không chạy JavaScript. Theo Ahrefs, GPTBot, ClaudeBot và PerplexityBot đều không thực thi JS, nên schema bơm vào trang qua Google Tag Manager là vô hình với chúng, dù Rich Results Test vẫn pass vì Google render được JS. Schema nên nằm trong HTML trả về từ server, đó là cách Rank Math làm sẵn cho bạn.
Với site nhiều bài, kiểm từng trang bằng tay không xuể: công cụ site audit (Ahrefs Webmaster Tools có bản miễn phí) quét schema lỗi cả site một lượt, hoặc nếu bạn dùng Claude Code thì quy trình audit content 49 check của mình có riêng một pillar chấm schema từng bài.
Khi KHÔNG nên dùng schema markup
Có 3 trường hợp schema markup không hữu ích, thậm chí có hại:
Trang đang bị Google penalty. Schema không gỡ được penalty. Fix issue gây penalty (thin content, manual action, link spam) trước. Add schema sau khi site recover.
Bài chưa rank top 30. Schema chỉ phát huy tác dụng khi trang xuất hiện trên SERP visible. Bài đang rank trang 4, 5 thì không ai thấy SERP listing – schema vô nghĩa cho đến khi bài lên trang 1-2. Tập trung vào content + internal link để lên top trước, schema sau.
Bài có content quá thin hoặc auto-generate. Schema làm Google chú ý đến trang nhanh hơn – nếu trang nội dung kém, đây là cách rút ngắn thời gian Google đánh giá tiêu cực. Viết content tốt trước, schema sau. Schema không cứu được nội dung yếu.
Schema thời AI search: còn đáng làm không?
Đáng, miễn là làm vì đúng lý do. Xếp lại kỳ vọng theo những gì đã đo được:
- Đừng làm vì tin rằng schema giúp tăng rank (Google nói thẳng là không) hay giúp AI cite bài bạn nhiều hơn (study 1.885 trang nói gần như không, ít nhất với trang đã có tên tuổi).
- Hãy làm vì rich results vẫn ăn click trên cùng một thứ hạng; vì Organization/Person schema là đường chính danh vào Knowledge Graph, nơi duy nhất có bằng chứng AI (Gemini) thật sự đối chiếu structured data; và vì một trang máy-đọc-được không bao giờ là khoản đầu tư lỗ khi search đang đổi hình dạng từng quý.

Nói cách khác: schema là tấm hộ chiếu cho nội dung của bạn trong thế giới máy đọc, không phải vé hạng thương gia. Ai hứa với bạn vé hạng thương gia, hỏi họ số liệu. Còn nếu bạn quan tâm bức tranh lớn hơn về việc xuất hiện trong câu trả lời AI, mảnh schema này chỉ là một phần của cuộc chơi GEO, nơi content và entity mới là vai chính.
Tự xử hay tự động hóa?
Site dưới 20 bài: gắn schema bằng Rank Math UI theo 7 bước ở trên là đủ, mỗi bài 3-5 phút. Site nhiều bài hoặc publish bằng automation: dùng inline JSON-LD pattern + để máy quét schema lỗi định kỳ. Mình đã đóng cả hai việc đó vào quy trình audit content trên Claude Code (pillar schema trong 49 check), còn nếu muốn người làm SEO rà tận nơi thì xem dịch vụ SEO audit website.
Câu hỏi thường gặp
Schema markup là gì, nói ngắn gọn?
Là đoạn mã JSON-LD gắn vào trang web để khai báo cho search engine biết chính xác từng phần nội dung là gì (bài viết, giá, đánh giá, câu hỏi), thay vì để máy tự đoán từ văn bản.
Cài Rank Math rồi có cần gắn thêm schema không?
Phần lớn blog thì không. Rank Math đã tự gắn Organization/Person cho site và Article cho từng bài. Chỉ cần thêm khi bài có dạng nội dung đặc thù: sản phẩm, công thức, sự kiện, review.
Gắn schema bao lâu thì thấy kết quả?
Rich results có thể xuất hiện sau vài ngày đến vài tuần tùy tốc độ Google crawl lại trang, và không có cam kết: pass Rich Results Test nghĩa là ĐỦ ĐIỀU KIỆN, không phải chắc chắn được hiển thị. Còn thứ hạng thì đừng chờ, schema không làm việc đó.
Schema có giúp bài được ChatGPT hay AI Overviews trích dẫn không?
Theo nghiên cứu 1.885 trang của Ahrefs (5/2026): không đo được tác động nào với trang đã được cite, AI Overviews thậm chí giảm nhẹ. Giá trị AI của schema đi đường vòng qua entity và Knowledge Graph, không phải đường thẳng “gắn là được cite”.
Các nguồn ngoài trong bài được truy cập và kiểm tra ngày 2026-06-11.