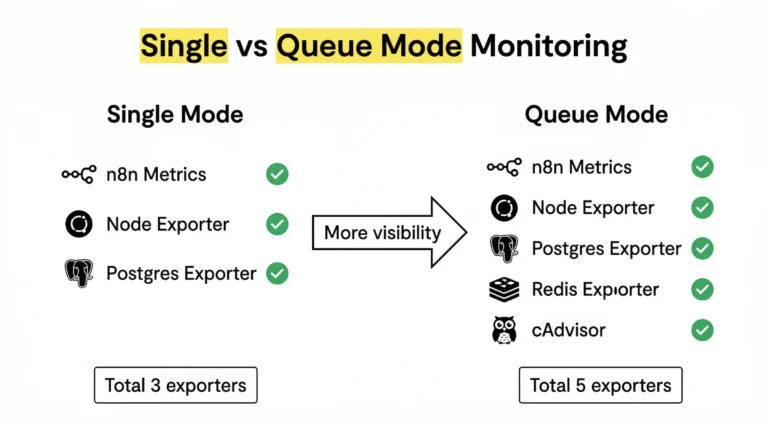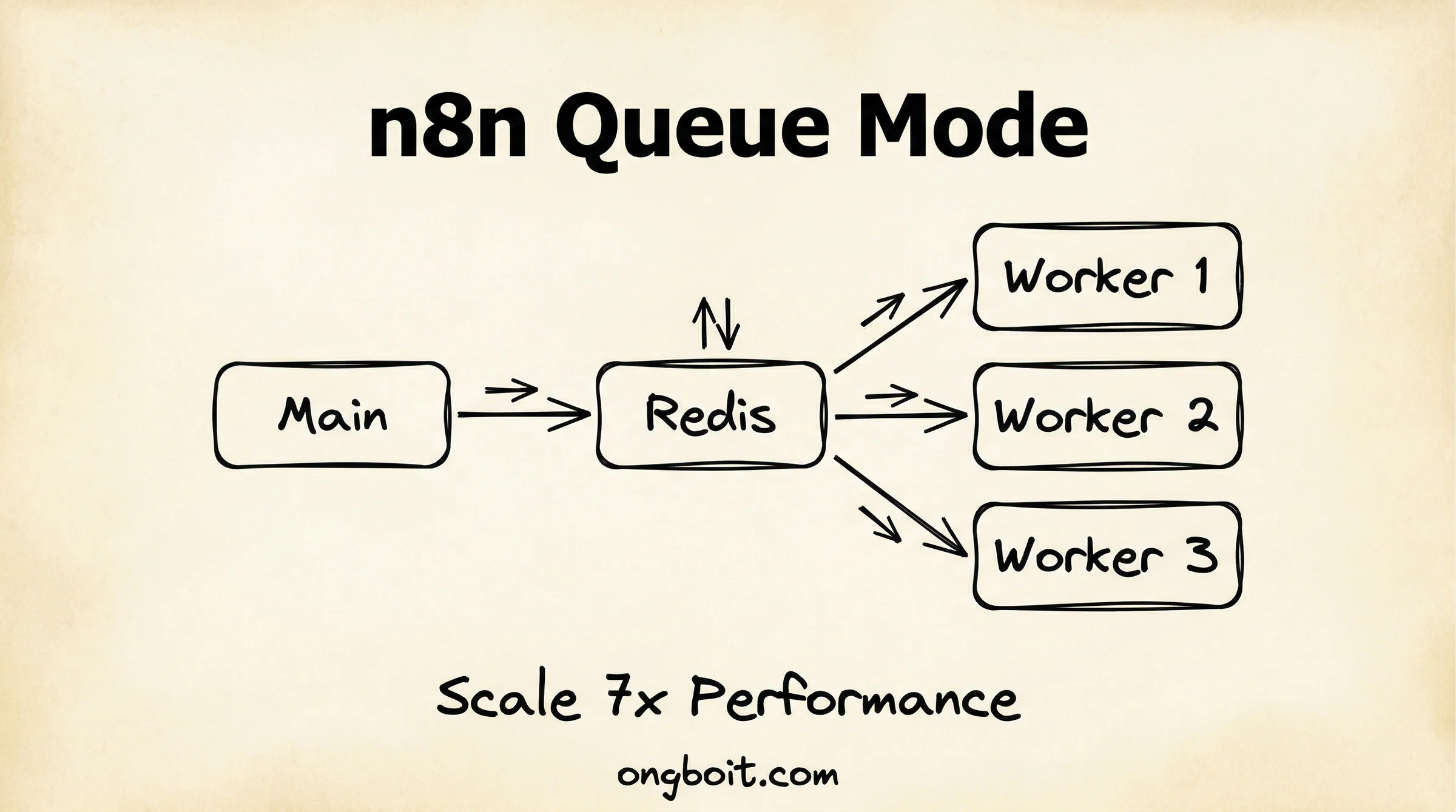
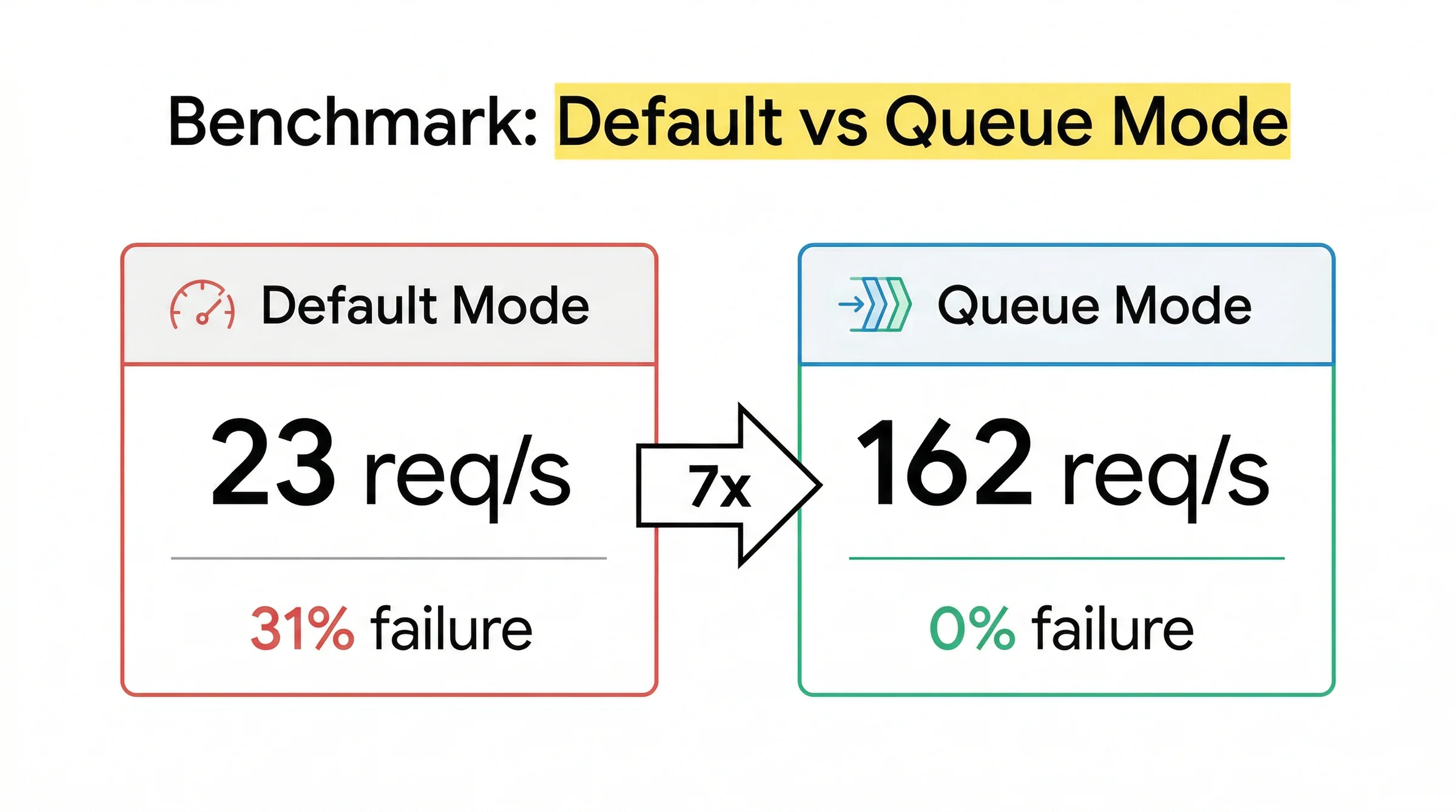
n8n Queue Mode tăng throughput từ 23 lên 162 requests/giây (7x), giảm failure rate từ 31% xuống 0%. Kiến trúc hoạt động theo mô hình: Main instance phân phối jobs qua Redis, worker nodes thực thi song song.
Mình đã chạy setup này trên production với 3 workers, xử lý hơn 10,000 executions/ngày mà không có sự cố nào. Nếu bạn đang tự host n8n và gặp tình trạng workflows bị timeout hoặc chờ nhau, đây là giải pháp bạn cần.
Lần đầu mình setup n8n, mình dùng mode mặc định và chạy một mình trên VPS. Mọi thứ ổn khi chỉ có vài workflows. Nhưng khi số lượng automation tăng lên, workflows bắt đầu xếp hàng chờ nhau, đôi khi timeout giữa chừng. Đó là lúc mình tìm hiểu về Queue Mode và nhận ra đây là thứ mình cần từ đầu.
Bài này mình sẽ chia sẻ toàn bộ quá trình setup n8n Queue Mode với Docker Compose, từ cấu hình Redis, Postgres cho đến scaling workers. Không có lý thuyết suông, chỉ có những gì mình đã thực sự chạy trên production.
n8n Queue Mode Là Gì?
Queue Mode là chế độ triển khai n8n theo mô hình phân tán, cho phép nhiều worker nodes cùng xử lý workflows song song. Thay vì một instance gánh tất cả mọi thứ, bạn có một Main instance đóng vai trò “bộ não” và nhiều Worker instances làm “tay chân” thực thi.
Mình hay giải thích cho bạn bè theo kiểu nhà bếp nhà hàng: Main instance là bếp trưởng nhận order và phân công. Redis là tấm bảng kẹp order ở giữa bếp. Workers là các đầu bếp thực thi từng món. Không có tấm bảng order đó (Redis), bếp trưởng phải chạy đưa từng tờ giấy cho từng người, vừa chậm vừa dễ mất.
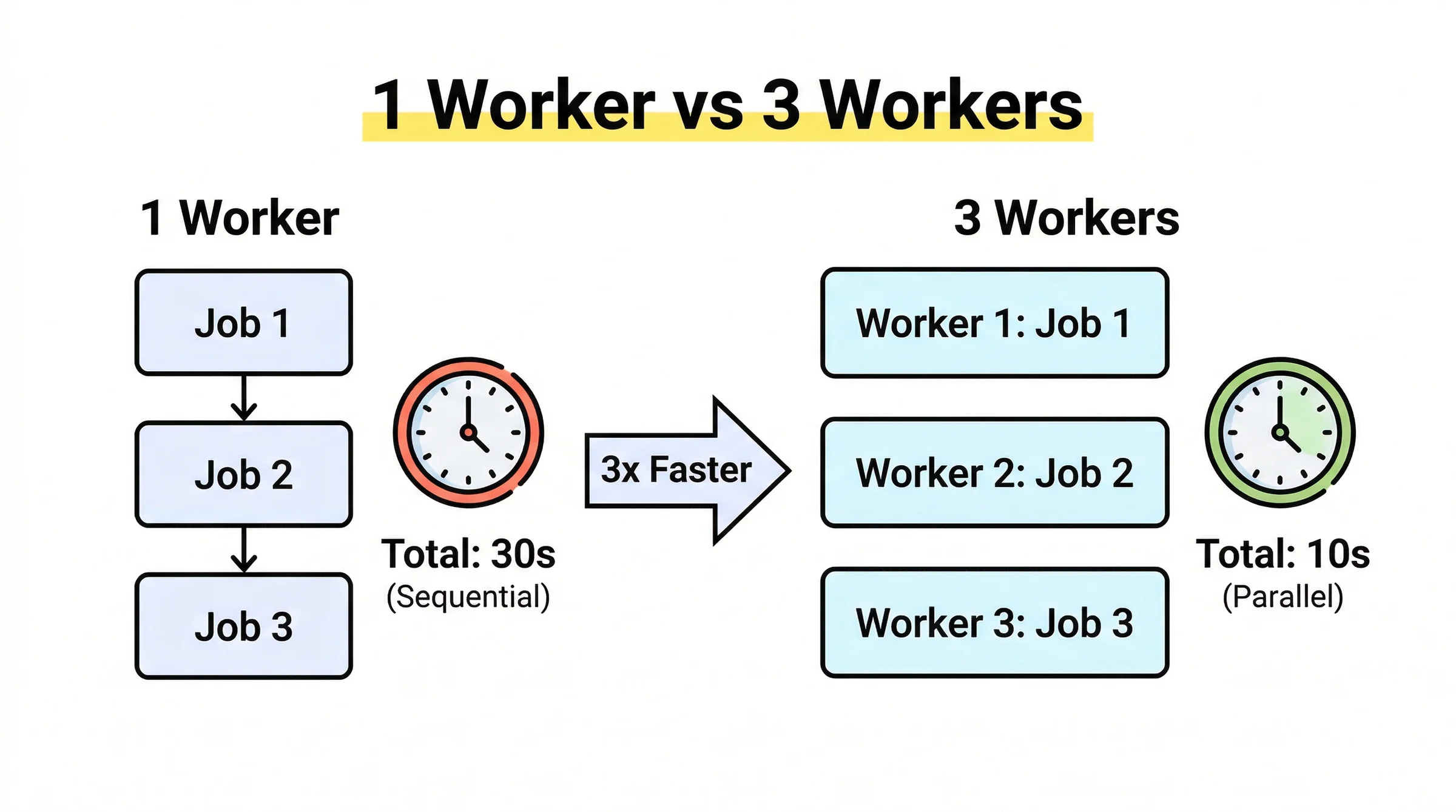
Hãy tưởng tượng n8n như một nhà bếp nhà hàng. Ở chế độ bình thường, chỉ có 1 đầu bếp vừa nhận order vừa nấu. Khi khách đông, đầu bếp quá tải và order bị delay. Queue Mode giống việc thuê thêm đầu bếp. Người quản lý (Main instance) nhận order và dán lên bảng (Redis queue). Các đầu bếp (Workers) tự lấy order từ bảng và nấu song song.
Trong thực tế, mình chạy n8n cho 3 website cùng lúc. Trước khi bật Queue Mode, workflows chạy chậm dần khi traffic cao. Sau khi thêm 2 workers, mọi thứ chạy mượt trở lại. Chi phí thêm? Chỉ cần VPS 4GB RAM thay vì 2GB.
Khi Nào Cần Queue Mode?
Không phải ai cũng cần Queue Mode ngay từ đầu. Nếu bạn chỉ chạy vài workflows cá nhân, mode mặc định là đủ. Queue Mode phù hợp khi bạn gặp ít nhất một trong những dấu hiệu này:
- Workflows hay bị timeout khi chạy nhiều cùng lúc
- CPU của VPS liên tục spike 100% trong giờ cao điểm
- Cần xử lý hơn 500 executions/ngày một cách ổn định
- Muốn scale horizontal khi tải tăng mà không restart toàn bộ hệ thống
- Đang chạy production với SLA cụ thể
Mình bắt đầu cân nhắc Queue Mode khi thấy n8n của mình xử lý khoảng 300-400 executions/ngày và CPU thường xuyên trên 80%. Sau khi chuyển sang Queue Mode với 2 workers, con số đó tăng lên 1,500+ mà CPU chỉ ở mức 40-50%.
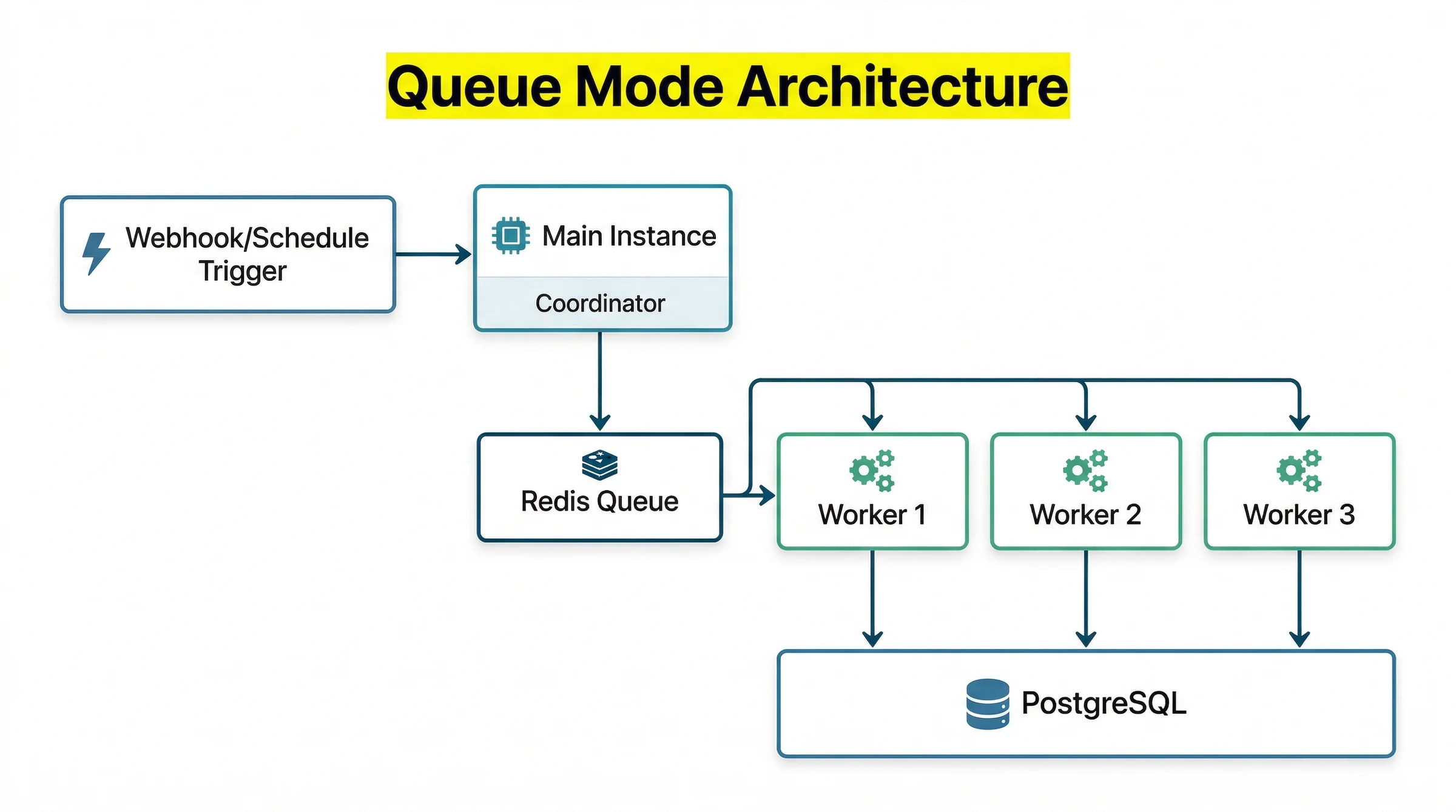
Kiến Trúc Queue Mode
Ba thành phần chính trong kiến trúc Queue Mode:
Main instance xử lý toàn bộ giao diện web, webhook, và trigger. Khi một workflow được kích hoạt, Main tạo ra một job và đẩy vào Redis queue. Main không tự chạy workflow nữa, trừ những tác vụ hệ thống nội bộ.
Redis đóng vai trò message broker, lưu trữ queue jobs tạm thời và đảm bảo các workers không xử lý trùng nhau. Redis cần ở trạng thái online liên tục. Nếu Redis chết, jobs sẽ không được phân phối cho đến khi Redis recover.
Worker instances liên tục poll từ Redis queue, lấy jobs về và thực thi. Mỗi worker chạy độc lập, bạn có thể thêm hoặc bớt workers mà không ảnh hưởng đến Main hay các workers khác.
Benchmark: Queue Mode Nhanh Hơn Bao Nhiêu?
Con số cụ thể từ benchmark của n8n cho thấy sự khác biệt rõ rệt. Với cùng tải workload, mode mặc định xử lý 23 requests/giây trong khi Queue Mode đạt 162 requests/giây, tức gấp hơn 7 lần. Quan trọng hơn, failure rate giảm từ 31% xuống còn 0%.

Điều thú vị là mình thấy trong thực tế, kết quả còn tốt hơn benchmark. Khi workflows của mình chủ yếu là I/O-bound (gọi API, đọc/ghi database), workers có thể xử lý đồng thời nhiều hơn vì chúng không bị block bởi CPU.
Cách Setup n8n Queue Mode Với Docker Compose?
Mình sẽ hướng dẫn từng bước để bạn có một setup production-ready. Toàn bộ cấu hình này mình đang chạy thực tế, không phải demo lab.
Prerequisites
Trước khi bắt đầu, bạn cần chuẩn bị:
- VPS chạy Linux (Ubuntu 22.04 hoặc Debian 12 là lý tưởng), tối thiểu 2 vCPU và 4GB RAM
- Docker và Docker Compose đã được cài đặt. Nếu bạn đang dùng Coolify để self-host, Docker đã có sẵn rồi
- Domain trỏ về IP của VPS (nếu muốn public access)
- Port 5678 và 6379 chưa bị chiếm
Docker Compose File
Đây là file docker-compose.yml mình đang dùng. Cấu trúc gồm 4 services: Postgres, Redis, n8n Main, và n8n Worker.
version: "3.8"
services:
postgres:
image: postgres:15-alpine
restart: always
environment:
POSTGRES_DB: n8n
POSTGRES_USER: n8n
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
volumes:
- postgres_data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U n8n"]
interval: 10s
timeout: 5s
retries: 5
redis:
image: redis:7-alpine
restart: always
command: redis-server --requirepass ${REDIS_PASSWORD}
volumes:
- redis_data:/data
healthcheck:
test: ["CMD", "redis-cli", "--no-auth-warning", "-a", "${REDIS_PASSWORD}", "ping"]
interval: 10s
timeout: 5s
retries: 5
n8n-main:
image: n8nio/n8n:latest
restart: always
ports:
- "5678:5678"
environment:
- N8N_HOST=${N8N_HOST}
- N8N_PORT=5678
- N8N_PROTOCOL=https
- N8N_ENCRYPTION_KEY=${N8N_ENCRYPTION_KEY}
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_BULL_REDIS_PORT=6379
- QUEUE_BULL_REDIS_PASSWORD=${REDIS_PASSWORD}
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=${POSTGRES_PASSWORD}
- N8N_RUNNERS_ENABLED=true
- WEBHOOK_URL=https://${N8N_HOST}
volumes:
- n8n_data:/home/node/.n8n
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
n8n-worker:
image: n8nio/n8n:latest
restart: always
command: worker
environment:
- N8N_ENCRYPTION_KEY=${N8N_ENCRYPTION_KEY}
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=redis
- QUEUE_BULL_REDIS_PORT=6379
- QUEUE_BULL_REDIS_PASSWORD=${REDIS_PASSWORD}
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=n8n
- DB_POSTGRESDB_PASSWORD=${POSTGRES_PASSWORD}
- QUEUE_WORKER_CONCURRENCY=5
volumes:
- n8n_data:/home/node/.n8n
depends_on:
- postgres
- redis
- n8n-main
deploy:
replicas: 2
volumes:
postgres_data:
redis_data:
n8n_data:
Environment Variables
Tạo file .env cùng thư mục với docker-compose.yml.
Đừng bao giờ commit file này lên Git.
# Thay thế bằng giá trị thực của bạn
N8N_HOST=n8n.yourdomain.com
N8N_ENCRYPTION_KEY=your-32-char-random-string-here
POSTGRES_PASSWORD=strong-postgres-password-here
REDIS_PASSWORD=strong-redis-password-hereĐể tạo N8N_ENCRYPTION_KEY ngẫu nhiên, chạy lệnh này:
openssl rand -hex 16Launch
Sau khi chuẩn bị xong, khởi động toàn bộ stack:
# Khởi động lần đầu
docker compose up -d
# Kiểm tra logs để xác nhận các services đang chạy đúng
docker compose logs -f n8n-main
docker compose logs -f n8n-worker
# Kiểm tra trạng thái
docker compose psNếu thấy log của n8n-main hiện “Listening on port 5678” và n8n-worker hiện “Worker ready”, là bạn đã setup thành công. Để scale thêm workers sau này, chạy:
# Scale lên 3 worker instances
docker compose up -d --scale n8n-worker=3
Chọn VPS Nào Cho Queue Mode?
Queue Mode thêm Redis và ít nhất một worker vào stack, nên yêu cầu phần cứng cũng cao hơn. Đây là bảng sizing mình tổng hợp từ kinh nghiệm thực tế và tài liệu từ NextGrowth.ai.
Mình đang dùng Hetzner CX32 (4 vCPU, 8GB RAM) cho setup production với 3 workers. Chi phí khoảng 12 EUR/tháng, rất hợp lý cho workload hiện tại. Nếu bạn ở Việt Nam và muốn latency thấp hơn, Hostinger VPS có datacenter ở Singapore khá tốt cho khu vực Đông Nam Á.
Một lưu ý quan trọng từ kinh nghiệm của mình: đừng để Redis và Postgres cùng server với n8n nếu bạn chạy production nghiêm túc. Nhưng với quy mô dưới 50,000 executions/ngày, chạy chung một VPS vẫn ổn, đặc biệt khi bạn có thể monitor và tối ưu từ từ. Bài hướng dẫn về setup VPS cho Claude Code của mình cũng có nhiều mẹo hữu ích cho việc quản lý server.
Từ kinh nghiệm cá nhân, mình recommend bắt đầu với Hostinger KVM 2 (4 vCPU, 8GB RAM, ~$9/tháng) cho Queue Mode. Server Singapore có latency thấp từ Việt Nam (~30ms). Nếu budget thoải mái hơn, Hetzner CX33 ($6.59/tháng) cũng là lựa chọn tốt nhưng chỉ có datacenter EU/US.
Một tip quan trọng: đừng chạy n8n Queue Mode và database trên cùng VPS nếu bạn có hơn 5,000 executions/ngày. Lúc đó, nên tách PostgreSQL ra managed database riêng (DigitalOcean Managed Database từ $15/tháng) để tránh bottleneck I/O.
Regular Mode vs Queue Mode: Nên Chọn Cái Nào?
Trước khi setup Queue Mode, bạn cần hiểu rõ sự khác biệt với Regular Mode (chế độ mặc định). Không phải ai cũng cần Queue Mode, và chọn sai mode có thể tốn tiền hoặc mất thời gian không cần thiết.
Dấu Hiệu Cần Chuyển Sang Queue Mode
Mình recommend bắt đầu với Regular Mode. Khi thấy bất kỳ dấu hiệu nào dưới đây, đó là lúc chuyển:
- Workflows timeout hoặc xếp hàng chờ nhau
- UI editor bị lag khi workflows đang chạy
- CPU VPS spike 80-100% liên tục
- Lỗi “Execution queue is full” xuất hiện
- Webhook bị miss vì server đang bận xử lý workflow khác
Cách Migrate Từ Regular Sang Queue Mode
Quy trình chuyển đổi gồm 4 bước. Mình đã làm nhiều lần nên biết chỗ hay vấp:
Bước 1: Backup toàn bộ n8n data (workflows, credentials, execution history). Nếu đang dùng SQLite, export tất cả workflows ra JSON trước.
Bước 2: Chuyển database từ SQLite sang PostgreSQL. n8n không có migration tool tự động cho việc này, bạn cần import workflows vào instance mới chạy Postgres.
Bước 3: Setup Docker Compose với Redis + Workers theo hướng dẫn ở phần trên. Copy N8N_ENCRYPTION_KEY từ instance cũ để decrypt credentials.
Bước 4: Test tất cả workflows trên setup mới trước khi tắt instance cũ. Đặc biệt check webhooks vì URL có thể thay đổi.
Troubleshoot 5 Lỗi Thường Gặp?
Mình đã gặp hầu hết những lỗi này trong quá trình vận hành. Ghi lại để bạn khỏi mất công debug lại từ đầu.
1. Jobs Stuck Không Chạy
Triệu chứng: workflow được trigger nhưng không thấy execution nào chạy, jobs cứ nằm trong queue. Nguyên nhân thường gặp nhất là workers không kết nối được Redis, hoặc workers chưa start.
# Kiểm tra workers đang chạy không
docker compose ps n8n-worker
# Kiểm tra logs của worker
docker compose logs n8n-worker --tail=50
# Kiểm tra Redis connection
docker compose exec redis redis-cli -a ${REDIS_PASSWORD} ping2. Redis Connection Lost
Nếu Redis restart hoặc bị disconnect, n8n Main và Workers sẽ mất kết nối. n8n có cơ chế tự reconnect, nhưng đôi khi cần restart workers thủ công. Thêm restart: always vào Redis service để tránh tình huống này.
3. Out of Memory (OOM)
Khi workers xử lý nhiều workflows lớn cùng lúc, RAM có thể cạn. Xử lý bằng cách giảm QUEUE_WORKER_CONCURRENCY từ 5 xuống 3, hoặc scale RAM. Mình cũng set --max-old-space-size=1024 trong Node options của worker để limit memory usage.
4. UI Bị Chậm Dù Workers Đang Chạy
Main instance cũng cần tài nguyên, đặc biệt khi có nhiều users đang xem execution history. Đảm bảo Main instance có ít nhất 1GB RAM riêng. Nếu bạn dùng deploy.resources.limits trong Docker Compose, kiểm tra lại giới hạn memory cho n8n-main.
5. Lỗi Sau Khi Update n8n
# Update đúng thứ tự
docker compose pull
docker compose up -d n8n-main
# Đợi Main healthy rồi mới update workers
sleep 30
docker compose up -d n8n-workerMình từng gặp lỗi Redis connection lost sau khi VPS restart. Nguyên nhân: Redis container chưa khởi động xong mà n8n đã cố kết nối. Giải pháp: thêm depends_on với condition: service_healthy trong Docker Compose để đảm bảo Redis sẵn sàng trước khi n8n start.
Một lỗi phổ biến khác: workflow chạy đúng ở development nhưng lỗi ở Queue Mode. Lý do: biến môi trường chỉ set ở Main instance mà chưa set ở Workers. Nhớ rằng Workers là container riêng, cần copy đầy đủ env vars. Mình recommend dùng file .env chung cho tất cả services.
Khi Nào Scale Workers, Khi Nào Không?
Thêm workers không phải lúc nào cũng là câu trả lời đúng. Mình đã học điều này theo cách khó khăn nhất: scale lên 5 workers trên VPS 4GB RAM và cuối cùng OOM hết cả stack.
Nguyên tắc vàng của mình: scale workers khi CPU của worker instances đang consistently trên 70%, không phải khi queue có nhiều jobs. Nếu queue nhiều nhưng CPU thấp, vấn đề có thể là bottleneck ở database hay external API, thêm workers không giải quyết được gì.
Khi Nên Thêm Workers
- CPU của worker pods ổn định trên 70-80% trong giờ cao điểm
- Queue depth tăng theo thời gian (jobs vào nhanh hơn xử lý)
- Latency từ lúc trigger đến lúc execution bắt đầu vượt quá 10-15 giây
- Bạn vừa thêm nhiều workflows mới với tần suất cao
Khi Không Nên Thêm Workers
- Queue nhiều nhưng CPU thấp dưới 30% (bottleneck ở I/O hoặc external API)
- RAM của VPS đã trên 80% (thêm worker sẽ gây OOM)
- Workflows đang có lỗi logic, không phải thiếu capacity
Tuning Concurrency
Thay vì thêm workers, đôi khi chỉ cần tăng QUEUE_WORKER_CONCURRENCY. Mỗi worker có thể xử lý nhiều jobs song song. Mình thường bắt đầu với concurrency=5, quan sát memory usage, rồi điều chỉnh. Với workflows nặng về CPU, giữ concurrency thấp (2-3). Với workflows I/O-bound như gọi API, có thể tăng lên 10-15.
Đây cũng là lý do mình luôn recommend setup monitoring ngay từ đầu, không phải đợi đến khi có vấn đề. Những metric như queue depth, worker CPU, và execution latency sẽ cho bạn biết chính xác khi nào cần scale.
Golden rule mà mình luôn theo: concurrency = số CPU cores x 2. Nếu VPS có 4 cores, set N8N_WORKER_CONCURRENCY=8. Đây là điểm xuất phát tốt. Sau đó monitor queue depth: nếu luôn > 0, thêm worker. Nếu workers idle > 50% thời gian, giảm concurrency hoặc bớt worker để tiết kiệm RAM.
Đừng mắc sai lầm thêm workers khi vấn đề thực sự là workflow chậm. Nếu 1 workflow mất 30 giây mà bạn có 100 workflows chờ, thêm workers chỉ giảm thời gian chờ chứ không giảm thời gian chạy. Optimize workflow trước (giảm API calls, cache data, batch operations), rồi mới scale workers.
Monitoring Queue Mode Với Prometheus và Grafana?
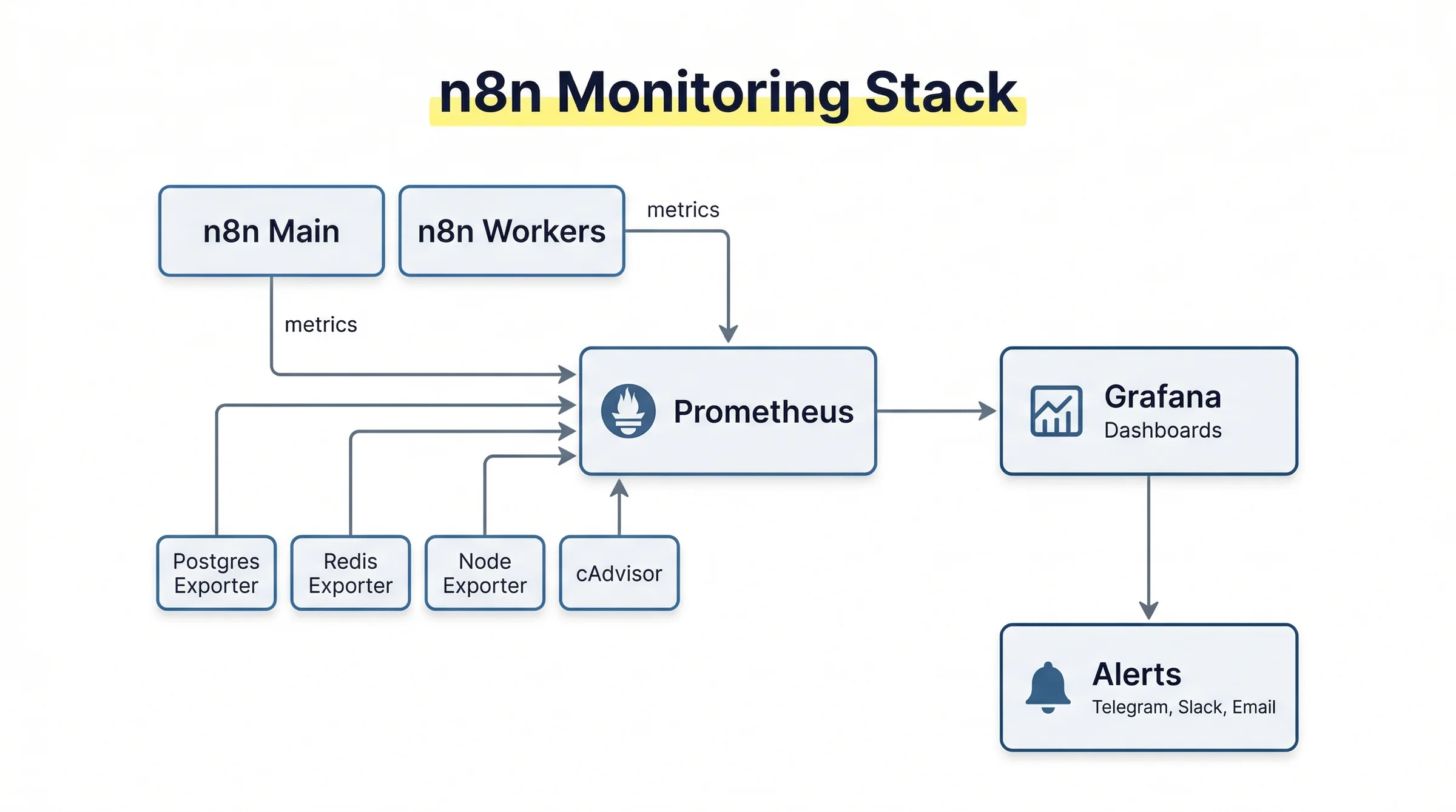
n8n Queue Mode expose metrics qua endpoint /metrics khi bạn bật N8N_METRICS=true. Các metrics quan trọng nhất bao gồm số jobs trong queue, execution duration, và worker concurrency hiện tại.
n8n tích hợp khá tốt với Prometheus và Grafana. Bạn có thể import dashboard có sẵn từ cộng đồng n8n và bắt đầu có visibility ngay lập tức. Mình đã viết chi tiết trong bài riêng: n8n Monitoring với Prometheus + Grafana, bao gồm cả alert qua Telegram khi có vấn đề.
Nếu bạn đang dùng Claude Code để tự động hóa DevOps, tích hợp Grafana alerts với n8n để tạo workflow tự động xử lý sự cố là một pattern cực kỳ hiệu quả mình hay dùng trong production.
Monitoring không phải nice-to-have mà là must-have khi chạy Queue Mode production. Mình setup một workflow canary chạy mỗi 5 phút: ping Redis, check worker count, verify database connectivity. Nếu bất kỳ check nào fail, workflow gửi alert qua Telegram ngay lập tức.
Các metrics quan trọng cần theo dõi: queue depth (số jobs đang chờ), worker utilization (% CPU/RAM mỗi worker), execution success rate, và average execution time. Nếu queue depth tăng liên tục mà workers không bận, vấn đề có thể ở network hoặc database, không phải thiếu workers.
Với Prometheus, export metrics từ n8n bằng cách set N8N_METRICS=true và N8N_METRICS_PREFIX=n8n_. Grafana dashboard visualize các metrics này thành biểu đồ real-time. Bài hướng dẫn đầy đủ: n8n Monitoring: Giám Sát Workflow Với Prometheus & Grafana.
Câu Hỏi Thường Gặp
Queue Mode có miễn phí không?
Có, Queue Mode là tính năng miễn phí trong n8n self-hosted. Bạn chỉ cần trả tiền cho infrastructure (VPS, Redis) chứ không có phí license nào thêm. n8n Cloud cũng hỗ trợ scaling tự động nhưng theo mô hình SaaS khác.
Cần bao nhiêu RAM cho Queue Mode?
Tối thiểu 4GB RAM cho setup 1 worker. Phân bổ mình recommend: Postgres 512MB-1GB, Redis 256-512MB, n8n Main 512MB-1GB, mỗi Worker 512MB-1GB. Với 3 workers trên Hetzner CX32 (8GB RAM), mình thường thấy tổng memory usage khoảng 5-6GB trong giờ cao điểm, còn room để buffer.
Redis có cần cluster không?
Không cần thiết cho hầu hết use cases. Redis standalone với persistence enabled là đủ cho hầu hết workloads dưới 50,000 executions/ngày. Redis Cluster chỉ cần khi bạn cần high availability thực sự (99.99% uptime) hoặc dataset Redis quá lớn cho một node. Mình chạy Redis standalone với AOF persistence, recovery time khi Redis restart thường dưới 30 giây.
Có thể dùng RabbitMQ thay Redis không?
n8n hiện tại chỉ hỗ trợ Redis làm queue backend, không hỗ trợ RabbitMQ. Điều này được ghi rõ trong n8n Queue Mode documentation. Redis đủ tốt cho hầu hết use cases, và cộng đồng n8n chưa có kế hoạch thêm RabbitMQ support trong ngắn hạn.
Queue Mode hoạt động với Coolify không?
Có, hoàn toàn được. Mình biết nhiều người trong cộng đồng đang chạy n8n Queue Mode trên Coolify. Bạn có thể deploy bằng Docker Compose stack trên Coolify, hoặc dùng Coolify managed Redis service. Bài hướng dẫn deploy với Coolify của mình có nhiều tips về cách quản lý Docker stacks phức tạp trên nền tảng này.
Khi hệ thống đã scale với Queue Mode, đừng quên setup n8n error handling đầy đủ để bảo vệ từng worker. Worker thất bại trong queue mode có thể gây mất jobs nếu không có error workflow và Telegram alert tương ứng.
Kết Luận
Queue Mode là bước tiến quan trọng nhất khi bạn chuyển từ “dùng n8n cho vui” sang “chạy n8n production cho business”. Mình đã chạy Queue Mode hơn 6 tháng cho ongboit.com và các dự án client. Kết quả: zero downtime, xử lý hàng ngàn workflows mỗi ngày, và chi phí chỉ thêm ~$4/tháng so với single instance.
Nếu bạn mới bắt đầu với n8n, chưa cần Queue Mode ngay. Khi nào workflows bắt đầu chậm, executions timeout, hoặc UI lag, đó là lúc cần upgrade. Setup chỉ mất 15 phút nếu follow hướng dẫn Docker Compose ở trên. Bắt đầu với 1 worker, tăng dần theo nhu cầu.
n8n Queue Mode không phải thứ bạn cần ngay từ ngày đầu, nhưng khi đã cần thì cần luôn. Mình recommend bắt đầu với 1 worker và scale dần theo workload thực tế, đừng over-provision từ đầu.
Công thức đơn giản: nếu n8n của bạn đang xử lý dưới 500 executions/ngày và CPU không spike, mode mặc định là đủ. Khi vượt ngưỡng đó hoặc bắt đầu thấy timeout, đây là thời điểm chuyển sang Queue Mode.
Setup này mình đã ổn định trên production nhiều tháng không có sự cố nghiêm trọng. Nếu bạn gặp vấn đề gì trong quá trình setup, để lại comment bên dưới, mình sẽ hỗ trợ dựa trên kinh nghiệm thực tế của mình.
Nếu bạn chưa có n8n chạy sẵn, xem hướng dẫn self-host n8n bằng Docker Compose hoặc Coolify để bắt đầu từ VPS trắng trước khi chuyển sang Queue Mode.