Claude Code không scrape được. Đây không phải bug. Đây là giới hạn thiết kế. Native web fetch của Claude Code chỉ đọc HTML tĩnh, không chạy JavaScript, không vượt được anti-bot. Kết quả? Bạn nhận về một shell rỗng thay vì dữ liệu thực. Giải pháp là claude code firecrawl: cài Firecrawl CLI vào Claude Code, fix toàn bộ vấn đề này trong 5 phút.
Mình đã dùng claude code firecrawl trong 3 tháng qua. Sự khác biệt so với web fetch thuần rõ đến mức không cần thuyết phục nhiều. Bài này mình sẽ giải thích tại sao Firecrawl hoạt động, cách cài đặt từng bước, và 5 use cases thực tế mình dùng hàng tuần.
Firecrawl là open-source tool với 107K GitHub stars biến bất kỳ website nào thành clean markdown cho LLMs. Đây là official Claude plugin được Anthropic liệt kê chính thức. Firecrawl fix đúng 3 điểm yếu của Claude Code: JS rendering, anti-bot bypass, và token bloat. Cài đặt mất 5 phút, free 500 credits để bắt đầu.
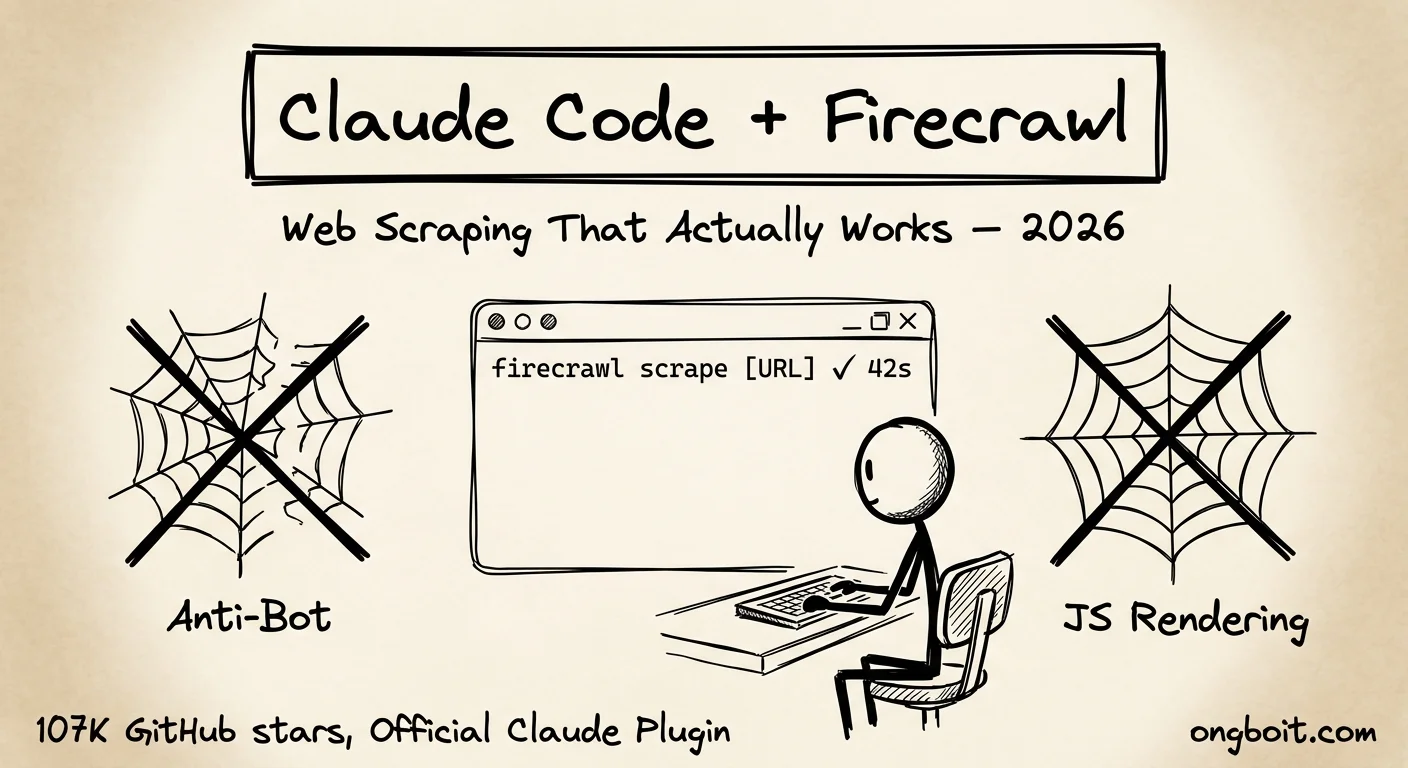


Claude Code Web Scrape Thực Sự Tệ Thế Nào?
Theo Scrapingdog (2026), 65% doanh nghiệp đang dùng web scraping để feed dữ liệu cho AI và ML projects. Nhưng Claude Code native không thể làm được điều đó một cách đáng tin cậy. Vấn đề không phải Claude kém, mà web hiện đại chạy bằng JavaScript, còn web fetch chỉ đọc HTML tĩnh.
Mình đã test ba kịch bản thực tế với claude code firecrawl và kết quả rất nhất quán. Cả ba lần, web fetch hoặc fail hoàn toàn hoặc chậm đến mức không dùng được.
Test 1: SimilarWeb (JavaScript-heavy)
Chase AI chạy benchmark trực tiếp trên SimilarWeb, một trong những sites phụ thuộc JS nặng nhất. Web fetch treo mất 4 phút 30 giây, cuối cùng trả về thông báo “page loads dynamically via JavaScript.” Firecrawl xong trong 42 giây, trả về đầy đủ traffic metrics, country breakdown, và social sources.
Test 2: Yellow Pages (có anti-bot protection)
Web fetch nhận 403 Forbidden liên tục. Không có cách nào bypass được. Firecrawl dùng Fire Engine để xử lý anti-bot, trả về 16 kết quả sau 53 giây. Không cần cấu hình thêm gì cả.
Test 3: Amazon nhiều trang
Claude Code thuần khi scrape 4 trang Amazon mất 5.5 phút, phần lớn thời gian là retry sau khi bị block. Firecrawl hoàn thành trong 45 giây. Chênh lệch gần 7 lần, và kết quả Firecrawl sạch hơn nhiều.
Nếu bạn chưa rõ Claude Code là gì và tại sao lại cần đến web scraping, đọc bài giới thiệu trước khi tiếp tục.
Firecrawl Là Gì, Và Tại Sao Nó Fix Được Vấn Đề Đó?
Firecrawl là open-source tool (107K GitHub stars, 6.9K forks tính đến tháng 4/2026) biến bất kỳ website nào thành clean markdown tối ưu cho LLMs. Đây cũng là official Claude plugin được Anthropic liệt kê chính thức, không phải third-party không có ai bảo đảm.
Khi bạn dùng claude code firecrawl, ba vấn đề cốt lõi được giải quyết theo cách khác hoàn toàn so với web fetch thông thường.
JS rendering: Firecrawl chạy headless Chrome thật ở background. Không chỉ đọc HTML, mà thực sự render trang như browser. Sites như SimilarWeb hay Linear không thể “qua mặt” nó bằng dynamic loading.
Anti-bot bypass: Fire Engine, proprietary layer của Firecrawl, xử lý phần lớn các anti-bot protections phổ biến. Đây là lý do Yellow Pages trả về kết quả trong khi web fetch nhận 403 liên tục.
Token efficiency: Đây là điểm mình thấy ít người nhắc đến nhất nhưng quan trọng không kém. Khi Claude Code dùng native web fetch, toàn bộ HTML dump thẳng vào context window. Với Firecrawl CLI, output được lưu ra file system. Claude đọc file theo từng phần bằng grep, không load cả trang vào token.
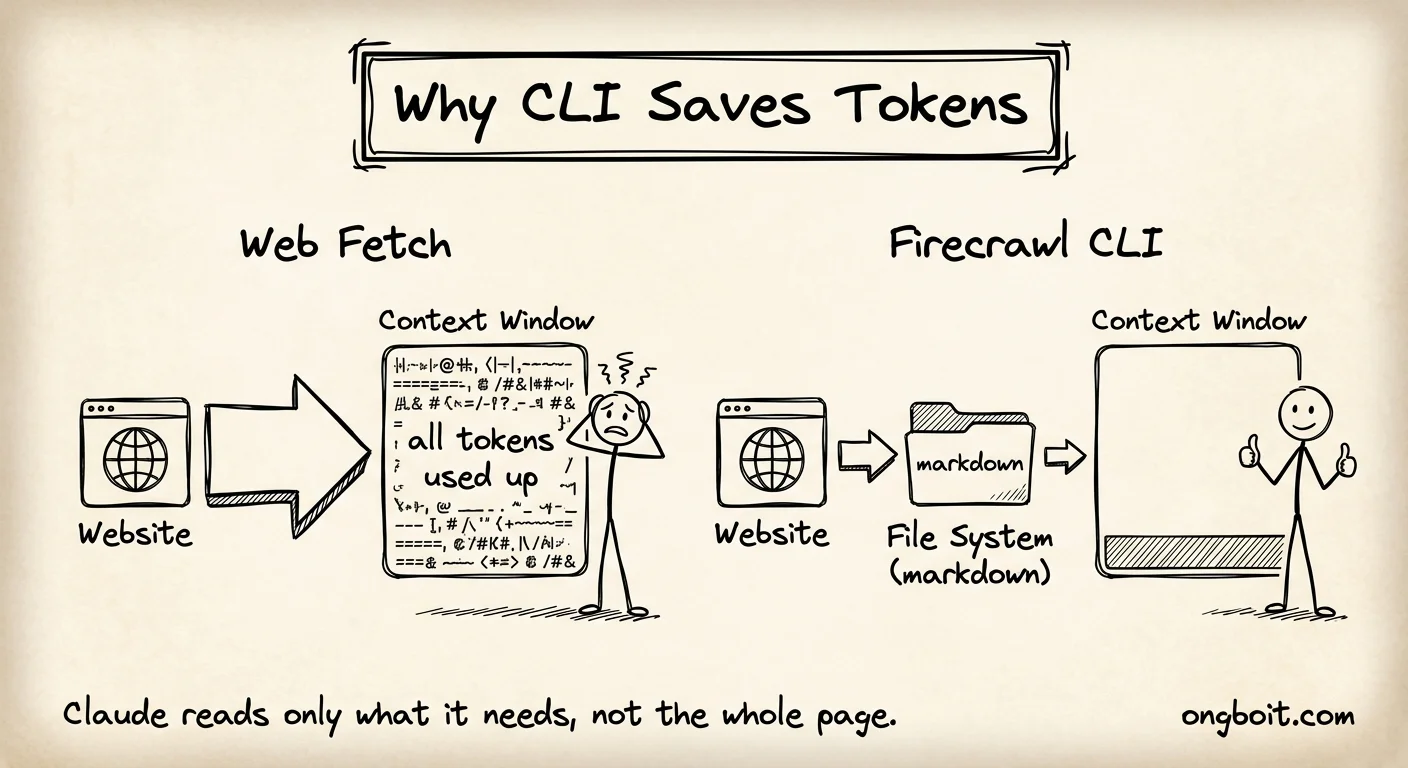
Về tốc độ, Black Bear Media (2026) đã benchmark trực tiếp: Firecrawl crawl 20 articles mất 110 giây, Apify mất gần 8 phút. Cached content của Firecrawl trả về trong dưới 100ms.
Sau khi cài Firecrawl, bạn sẽ muốn đọc thêm về cách tiết kiệm token Claude Code khi scrape nhiều trang cùng lúc.
Firecrawl Có 8 Khả Năng: Dùng Cái Nào Khi Nào?
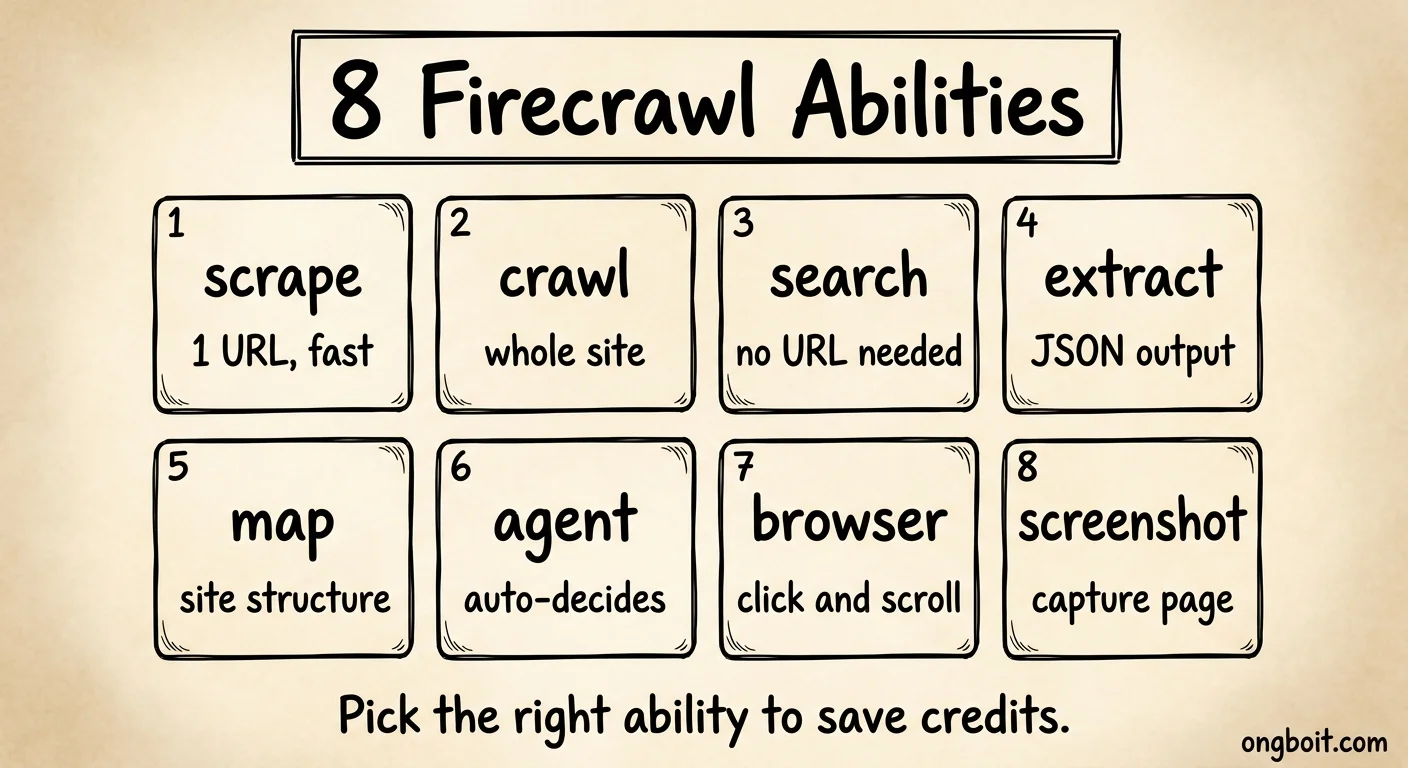
Claude code firecrawl không phải một-tool-làm-tất-cả theo kiểu cùng một lệnh. Firecrawl có 8 abilities riêng biệt, mỗi cái tối ưu cho một loại task khác nhau. Hiểu rõ bảng này giúp bạn tránh tốn credits không cần thiết vào agent khi scrape là đủ.
agent và browser interact tốn nhiều credits nhất vì chúng chạy browser session thật. scrape và search tiết kiệm nhất. Trên free plan 500 credits, ưu tiên scrape và search để test trước.
Cài Đặt Claude Code Firecrawl Trong 5 Phút
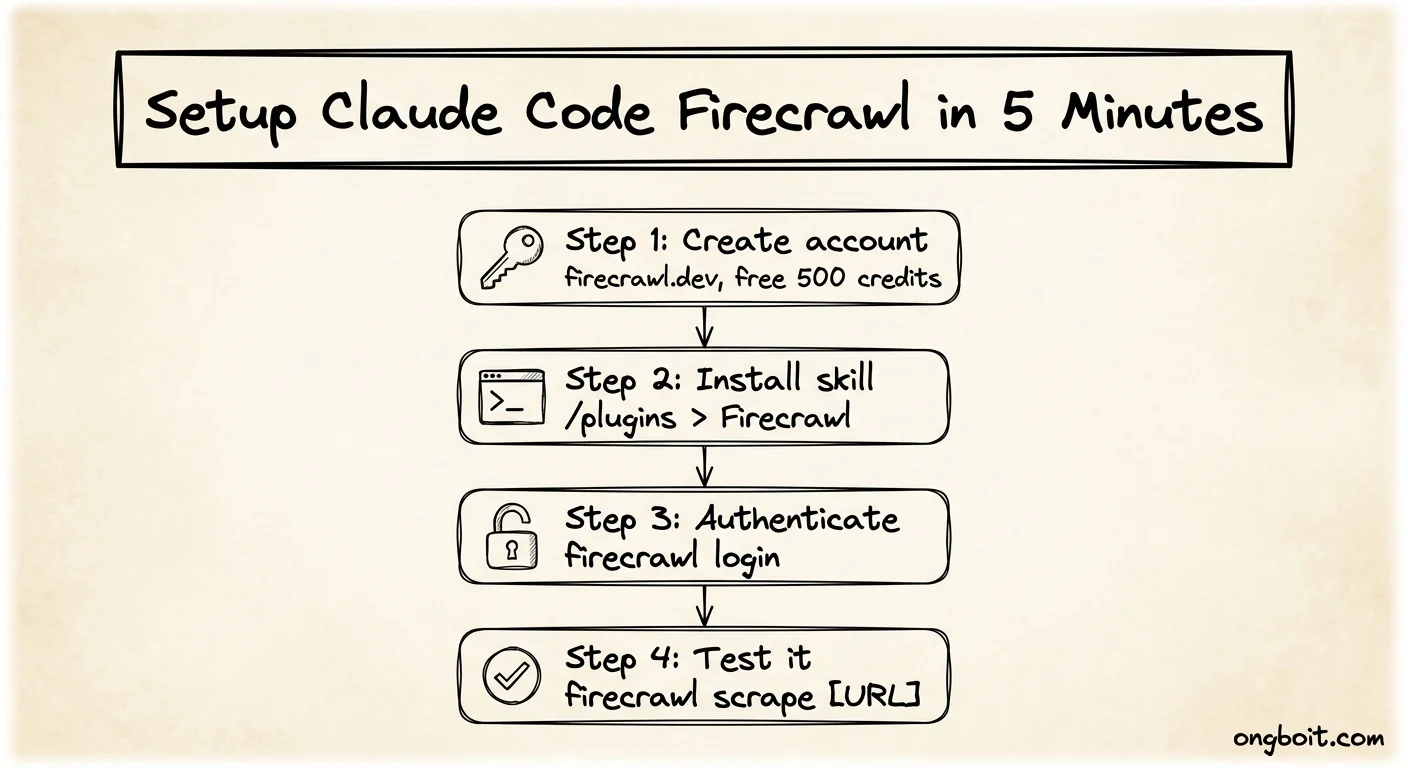
Cài đặt claude code firecrawl mất đúng 5 phút. Free plan cho 500 credits để bắt đầu, không cần credit card. Đây là đủ để chạy qua toàn bộ tutorial dưới đây và test 2-3 use cases thực tế. Quá trình theo 4 bước, bước nào cũng dưới 2 phút.
Bước 1: Tạo tài khoản và lấy API key
Vào firecrawl.dev, đăng ký bằng Google account. Sau khi login, vào phần Dashboard để copy API key. Key này sẽ dùng ở Bước 3.
Bước 2: Cài skill vào Claude Code
Có ba cách, mình liệt kê theo mức độ dễ.
Cách 1: Plugin marketplace (nhanh nhất): Trong Claude Code session, gõ /plugins, tìm “Firecrawl” rồi Install. Done.
Cách 2: Tự cài qua docs (workflow của Duncan Rogoff): Vào firecrawl.dev/docs, copy toàn bộ trang install documentation, paste vào Claude Code và nói: “Install the Firecrawl skill and CLI for me.” Claude tự xử lý phần còn lại.
Cách 3: MCP server thủ công:
npx -y firecrawl-mcpBước 3: Authenticate
firecrawl login
# Browser tự mở → click "Authorize CLI" → doneSau khi authorize, CLI lưu credentials locally. Bạn không cần login lại cho các session sau.
Bước 4: Test nhanh
# Test scrape một trang
firecrawl scrape https://firecrawl.dev --formats markdown
# Test search (không cần biết URL trước)
firecrawl search "top AI news March 2026" --limit 5Nếu cả hai lệnh trả về markdown, cài đặt thành công. Thời gian thực tế từ lúc vào firecrawl.dev đến lúc test xong: dưới 5 phút.
extract tính phí theo token riêng, bắt đầu từ gói $89/tháng. Dùng scrape và search trước để tránh hết credits trước khi test xong.
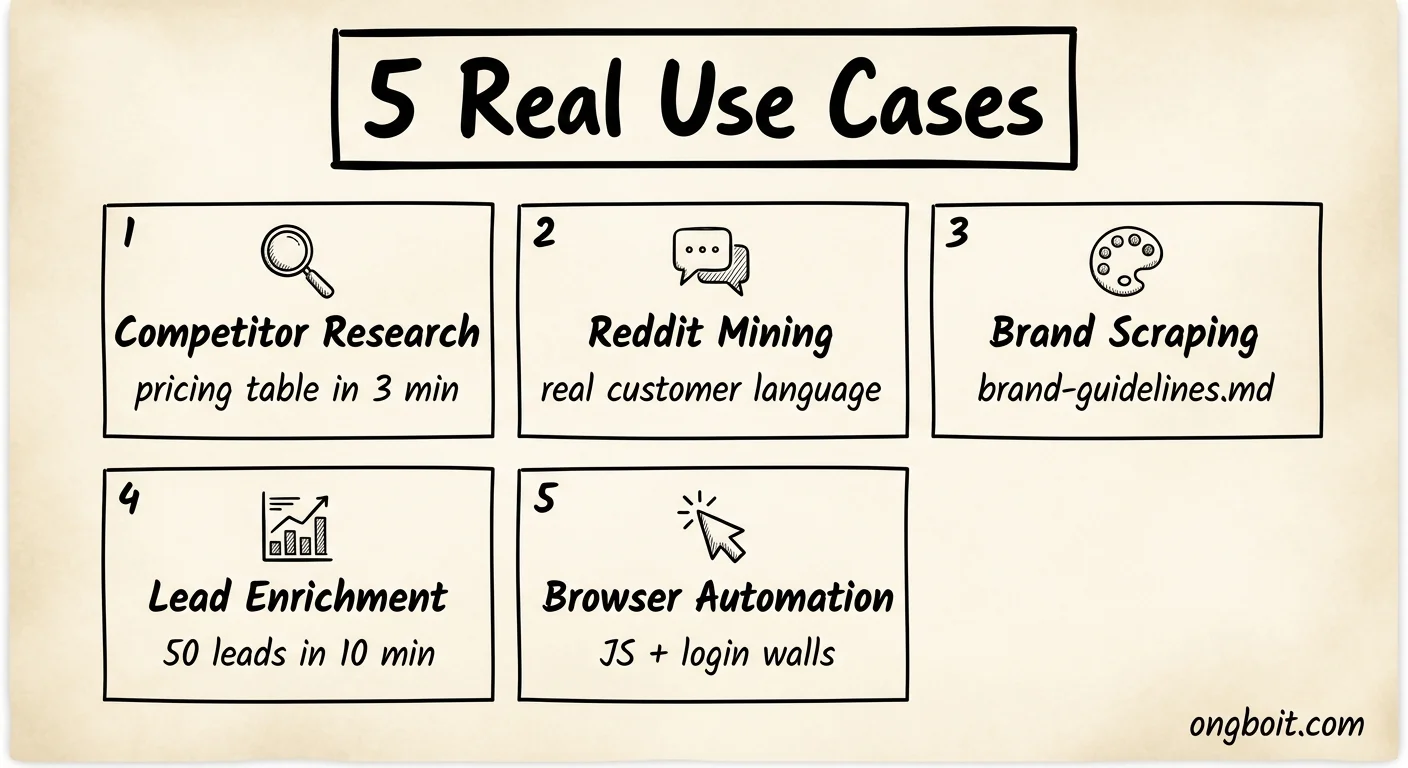
5 Use Cases Thực Tế Với Claude Code Firecrawl: Bạn Dùng Cái Nào Trước?
Phần này là lý do mình viết bài này. Với claude code firecrawl, cài xong là một chuyện, biết dùng vào việc gì mới là chuyện quan trọng hơn. Năm use cases dưới đây mình đều đã dùng trong công việc thực tế.
Use Case 1: Competitor Research (Không Cần Viết Code)
Đây là use case đơn giản nhất nhưng tiết kiệm thời gian nhất. Thay vì mở từng tab, copy-paste thủ công, bạn chỉ cần một prompt.
Dùng Firecrawl scrape trang pricing của 3 URLs này: [URL1], [URL2], [URL3].
Tạo bảng so sánh features và giá.
Highlight những điểm mình đang thiếu so với họ.Claude code firecrawl dùng ability search để tìm các trang liên quan, scrape để lấy nội dung chi tiết, rồi Claude tổng hợp thành report. Toàn bộ quá trình mất dưới 3 phút cho 3 competitors.
Mình dùng workflow này hàng tuần để theo dõi thay đổi pricing của competitors. Kết quả đáng tin hơn hẳn so với việc nhờ ChatGPT “tìm giá của X” vì Firecrawl lấy data thực từ trang thật, không phải data training cũ.
Use Case 2: Reddit Mining Cho Customer Language
Đây là workflow mình học từ Duncan Rogoff (YouTube, 2026). Anh ấy dùng Firecrawl để scrape Reddit threads, tìm pain points của khách hàng, rồi dùng exact language đó để viết web copy.
Dùng Firecrawl scrape Reddit để tìm customer frustrations với HVAC companies.
Tổng hợp thành báo cáo: top pain points, exact language họ dùng.Insight cụ thể từ video của Duncan: từ xuất hiện nhiều nhất trong mọi review 5 sao của HVAC companies là “honest.” Điều đó cho thấy ngành này có vấn đề nghiêm trọng về trust, và web copy cần nhắm vào đúng điểm đó thay vì nói về giá hay tốc độ.
Use Case 3: Brand Scraping Cho Client Work
Khi làm việc với client mới, bước đầu tiên bao giờ cũng là hiểu brand của họ. Thay vì hỏi từng thứ một, mình dùng claude code firecrawl để lấy hết trong một lần.
Dùng Firecrawl scrape toàn bộ thông tin từ website này: [URL].
Tạo brand-guidelines.md với: màu sắc, typography, logo URLs, services, tone of voice.File markdown này trở thành reusable asset. Mỗi lần Claude Code cần làm gì đó cho client đó, mình chỉ cần reference file brand-guidelines.md thay vì giải thích lại từ đầu. Đây thực chất là cách build “client memory” rẻ và nhanh nhất, không cần RAG hay vector database phức tạp.
Use Case 4: Lead Enrichment
Có list companies nhưng thiếu context về từng cái. Claude code firecrawl giải quyết ở scale mà làm tay không kịp.
Tôi có list 50 company URLs (file leads.txt).
Dùng Firecrawl crawl từng site, extract: company size, tech stack, contact info, pricing model.
Output ra leads-enriched.csv.Kết hợp với kỹ thuật sub-agents, mỗi sub-agent xử lý 10 companies song song. 50 leads thay vì mất 50 phút chỉ còn mất 10 phút.
Use Case 5: Browser Automation Cho JavaScript và Login Walls
Đây là ability mới nhất và mạnh nhất của Firecrawl. Video official của Leo demo rõ trường hợp airrank.dev có pagination và nút “see more.”
Vào airrank.dev, lấy top 30 LLMs từ bảng chính.
Nếu cần click "see more" hay chuyển trang, dùng Firecrawl browser feature.Persistent sessions là tính năng đặc biệt hữu ích. Bạn login LinkedIn một lần trong browser session, Firecrawl lưu session đó lại. Các lần sau không cần login lại. Tất nhiên, kiểm tra terms of service của từng platform trước khi dùng.
Pipeline này còn mạnh hơn nhiều khi kết hợp với AutoResearch Claude Code để tự động hóa toàn bộ research workflow.
Giới Hạn Của Firecrawl: Khi Nào Không Nên Dùng?
Claude code firecrawl rất mạnh, nhưng không phải không có điểm yếu. Nói thẳng ra thay vì để bạn tự phát hiện sau khi đã tốn credits là tốt hơn. Theo Proxyway benchmark (2025), Firecrawl chỉ đạt 33.69% success rate trên các hardened anti-bot sites, so với Zyte 93.14% và Scrapfly 98%.

Các sites mà Firecrawl thường fail bao gồm LinkedIn Enterprise, Cloudflare Enterprise tier, và sites dùng specialized solutions như Kasada hay DataDome. Đây là những anti-bot systems cấp enterprise, không phải standard protections.
Ngoài ra, nếu bạn chọn route self-hosting open-source, bạn mất anti-bot protection và browser interact. Route đó chỉ phù hợp khi scrape sites bạn sở hữu hoặc sites không có protection đáng kể.
Khi nào nên dùng tool khác thay thế? Dùng Playwright khi cần click phức tạp, fill forms với validation logic, hoặc upload files. Đây là những thứ Firecrawl browser interact không handle được. Dùng Zyte hoặc Scrapfly khi cần 90%+ success rate trên hardened sites ở scale lớn, và sẵn sàng trả giá cao hơn đáng kể.
Firecrawl Kết Hợp Với Hệ Sinh Thái Claude Code Thế Nào?
Claude code firecrawl một mình đã mạnh. Nhưng nó mạnh nhất khi là một mắt xích trong cả pipeline, không phải tool độc lập. Dưới đây là ba cách kết hợp mình thấy hiệu quả nhất.
Mình đã test pipeline Firecrawl + Skills trong 3 tuần. Kết quả: thời gian tạo một Claude Code skill mới từ docs giảm từ khoảng 45 phút xuống còn 8 phút. Phần lớn thời gian tiết kiệm là từ bước research và đọc docs.
Firecrawl + Skills: Scrape documentation của một tool mới, feed vào Claude Code, yêu cầu Claude viết skill dựa trên docs đó. Thay vì đọc docs thủ công và viết skill từ đầu, bạn có một draft trong vài phút. Tìm hiểu thêm về cách build Claude Code Skills để dùng pattern này hiệu quả hơn.
Firecrawl + Sub-agents: Assign mỗi sub-agent scrape một competitor song song. 10 competitors từng mất 10 phút tuần tự, giờ chỉ còn 1 phút. Sub-agent nhận URL, scrape, extract structured data, trả về kết quả. Claude chính tổng hợp.
Firecrawl + AutoResearch: Scrape data thực từ web làm input cho experiments. Thay vì dùng sample data hay synthetic data, bạn feed real-world content. Kết quả experiments gần với thực tế hơn nhiều.
Pipeline đầy đủ trông như thế này: Web → Firecrawl → Markdown file → Claude reads → Report/Action. Đơn giản, nhưng chính sự đơn giản đó làm nó dễ debug và dễ maintain.
Nếu bạn chưa có Claude Code, cài đặt Claude Code là bước đầu tiên trước khi làm bất cứ thứ gì ở đây.
Câu Hỏi Thường Gặp
Firecrawl free 500 credits có đủ dùng không?
Đủ để test. 500 credits tương đương 500 URL scrapes hoặc search queries. Mình chạy hết tutorial trong bài này và 2-3 use cases thực tế với khoảng 80-100 credits. Nếu bạn cần dùng thường xuyên, Hobby plan $16/tháng cho 3,000 credits là đủ cho hầu hết individual use cases.
Firecrawl MCP và Firecrawl CLI khác nhau thế nào?
MCP server (firecrawl-mcp) cho phép Claude gọi Firecrawl trực tiếp qua Model Context Protocol. CLI (firecrawl) là command-line tool để dùng từ terminal. Khi cài skill, bạn thực ra đang cài cả hai. CLI lưu output ra file system, MCP là channel để Claude communicate với Firecrawl API. Cả hai cần API key từ firecrawl.dev.
Có scrape được PDF không?
Có. Lệnh firecrawl scrape [PDF-URL] --formats markdown trả về text từ PDF dưới dạng markdown. Mình dùng cách này cho research papers, whitepapers, và annual reports. Kết quả không hoàn hảo 100% với PDFs có layout phức tạp, nhưng đủ tốt cho phần lớn use cases.
Có cần biết code để dùng Firecrawl với Claude Code không?
Không cần. Bạn chỉ cần nói với Claude bằng tiếng Việt hoặc tiếng Anh như các ví dụ prompt trong bài này. Claude tự chọn đúng Firecrawl ability cho task, tự viết lệnh, tự chạy, rồi trả về kết quả. Bạn chỉ cần cài đặt ban đầu theo 4 bước ở trên.
Firecrawl có scrape được trang cần login không?
Với browser interact feature trên Hobby plan trở lên, bạn có thể start một persistent browser session, login thủ công một lần, rồi Firecrawl lưu session đó lại để reuse. Nhưng kiểm tra terms of service trước. LinkedIn, ví dụ, cấm automated scraping rõ ràng trong ToS.
Khác gì BeautifulSoup và Scrapy?
BeautifulSoup và Scrapy là Python libraries, yêu cầu viết code scraping thủ công, không handle JavaScript, không có anti-bot protection, và không tích hợp với Claude Code. Firecrawl là managed service, handle anti-bot, output clean markdown trực tiếp, và tích hợp native với Claude Code skills. Trade-off là Firecrawl có pricing, còn BeautifulSoup/Scrapy hoàn toàn miễn phí nếu bạn tự host.
Kết Luận
Claude code firecrawl fix đúng ba điểm yếu của Claude Code web fetch: JavaScript rendering, anti-bot bypass, và token bloat. Không cần workaround phức tạp, không cần Playwright cho phần lớn use cases. Chỉ cần 5 phút cài đặt và 500 credits miễn phí để bắt đầu.
Bắt đầu với scrape và search để làm quen. Sau khi nắm rõ giới hạn của từng ability, mới nên thử browser interact và agent. Nhớ kiểm tra terms of service của từng site trước khi chạy ở scale.
Nếu muốn mở rộng thêm, xem Google Workspace CLI Claude Code để kết nối scraping pipeline với Google Sheets và Docs.
Thế giới đang chuyển sang AI-driven data collection. 65% doanh nghiệp đã dùng web scraping cho AI. Câu hỏi không còn là có nên dùng không, mà là dùng tool nào hiệu quả nhất cho từng use case cụ thể.