Claude Code Ultrareview Là Gì? Đáng $5–$20? (2026)
Claude Code Ultrareview là gì? Đây là feature AI code review chạy qua slash command /ultrareview, phân tích code theo 5 tiêu chí. Một bug thoát qua /review của Claude Code, merge vào main, rồi nổ production lúc 2 giờ sáng. Nguyên nhân: một model đơn không đủ góc nhìn để phân tích interaction giữa auth module và session manager cùng lúc. /ultrareview giải quyết đúng vấn đề đó: fleet 5-20 agent song song, mỗi agent chuyên một góc, kết quả qua Verification Layer độc lập trước khi báo cáo.
Giá là $5-$20/lần. Bài này giải thích cơ chế hoạt động thực sự của /ultrareview, cách chạy từng bước, và khi nào chi phí đó worth it với framework Bug Budget giúp bạn tính ROI nhanh. Đây là bài tiếng Việt đầu tiên về tính năng này và là bài duy nhất address thẳng câu hỏi mà community HackerNews đặt ra: “$15-$20/review có đáng không khi /review miễn phí?”
TL;DR
- /ultrareview triển khai fleet 5-20 AI agent song song trong Anthropic cloud sandbox, mỗi agent chuyên một góc (security, logic, perf, tests, architecture)
- 84% large PR (≥1,000 lines) nhận ít nhất 1 bug thực sự; false positive rate dưới 1% (Anthropic internal)
- Chi phí $5-$20/lần, đáng với auth, migration, refactor lớn; không cần cho commit hằng ngày
- Không chạy trên Bedrock/Vertex/ZDR; 3 free runs hết hạn 5/5/2026
Claude Code Ultrareview Là Gì Và Hoạt Động Ra Sao?
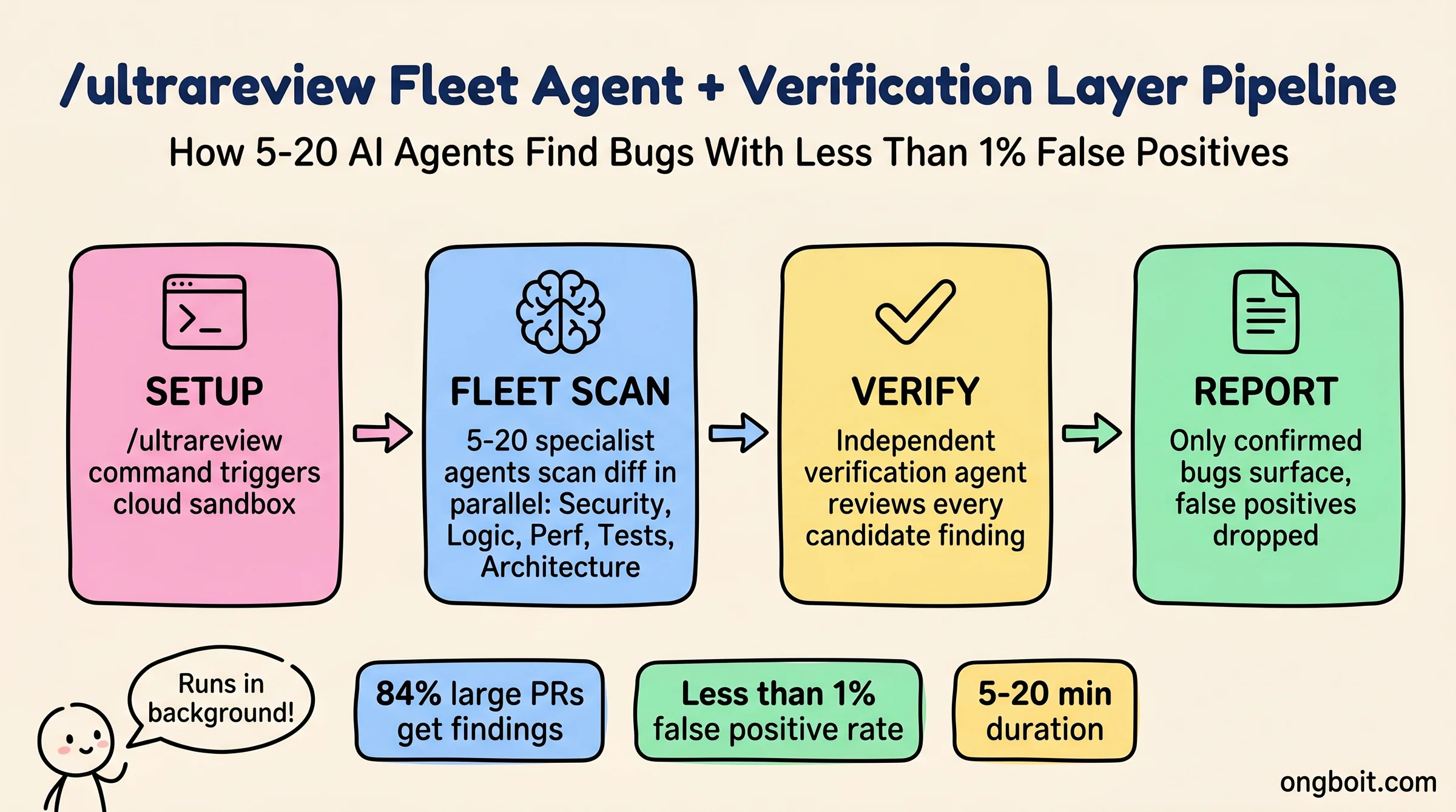
/ultrareview là lệnh code review chuyên sâu trong Claude Code (có từ v2.1.86, tháng 4/2026), triển khai fleet 5-20 agent AI trong Anthropic cloud sandbox để phân tích diff từ nhiều góc độ độc lập. Kết quả qua Verification Layer trước khi báo cáo, giữ false positive dưới 1%. Đây là điểm khác biệt căn bản so với /review thông thường, chạy ngay trong terminal với một model đơn trong vài giây.
Sự khác biệt không chỉ là “nhiều agent hơn”. /review chạy realtime trong vài giây, miễn phí, nhưng dùng một model duy nhất nhìn toàn bộ diff. Khi diff lớn, model phải chia attention cho quá nhiều thứ cùng lúc, dẫn đến bỏ sót bug cross-file và interaction bug giữa các module. /ultrareview giải quyết vấn đề đó bằng cách chia nhỏ: mỗi agent chỉ tập trung vào một chiều duy nhất.
| Tiêu chí | /ultrareview | /review thông thường |
|---|---|---|
| Số agent | 5-20 chuyên biệt | 1 model tổng hợp |
| Thời gian | 5-20 phút (background) | Vài giây (realtime) |
| Chi phí | $5-$20/lần | Miễn phí |
| Terminal trong lúc chờ | Tự do dùng tiếp | Blocked |
| Verification step | Có (Verification Layer) | Không |
| False positive | Dưới 1% | Cao hơn |
| Auth | Claude.ai account | API key OK |
Theo dữ liệu nội bộ của Anthropic, 84% large PR (từ 1,000 lines trở lên) nhận ít nhất 1 bug finding thực sự, trung bình 7.5 issues/PR. Con số này từ internal testing, không phải benchmark độc lập, nhưng đủ để tính cost-benefit.
Điểm quan trọng: /ultrareview không thay thế /review. Với commit hằng ngày, /review là đủ và nhanh hơn nhiều. /ultrareview dành cho những PR mà cost của một bug production thực sự cao: auth changes, database migration, large refactor lớn hơn 500 lines. Cách phân biệt nhanh: nếu một bug trong PR đó lọt lên production và tốn 4 giờ để debug, /ultrareview worth it. Nếu worst case là “mình sửa lại trong 20 phút”, thì /review miễn phí là đủ.
Verification Layer: /ultrareview Hoạt Động Như Thế Nào?
Verification Layer là cơ chế khiến /ultrareview khác biệt căn bản với các tool AI review khác: mỗi bug candidate tìm được bởi bất kỳ agent nào phải qua một agent độc lập xác nhận trước khi đưa vào report. Đây là lý do false positive rate dưới 1%. Không phải vì model giỏi hơn, mà vì kiến trúc có bước verification riêng biệt với fleet agent.
Pipeline của /ultrareview hoạt động theo 4 giai đoạn:
Giai đoạn 1: Setup. Anthropic cloud sandbox nhận diff (từ branch hoặc PR). Sandbox phân tích độ lớn của diff để quyết định cần bao nhiêu agent, từ 5 agent cho PR vừa đến 20 agent cho codebase lớn.
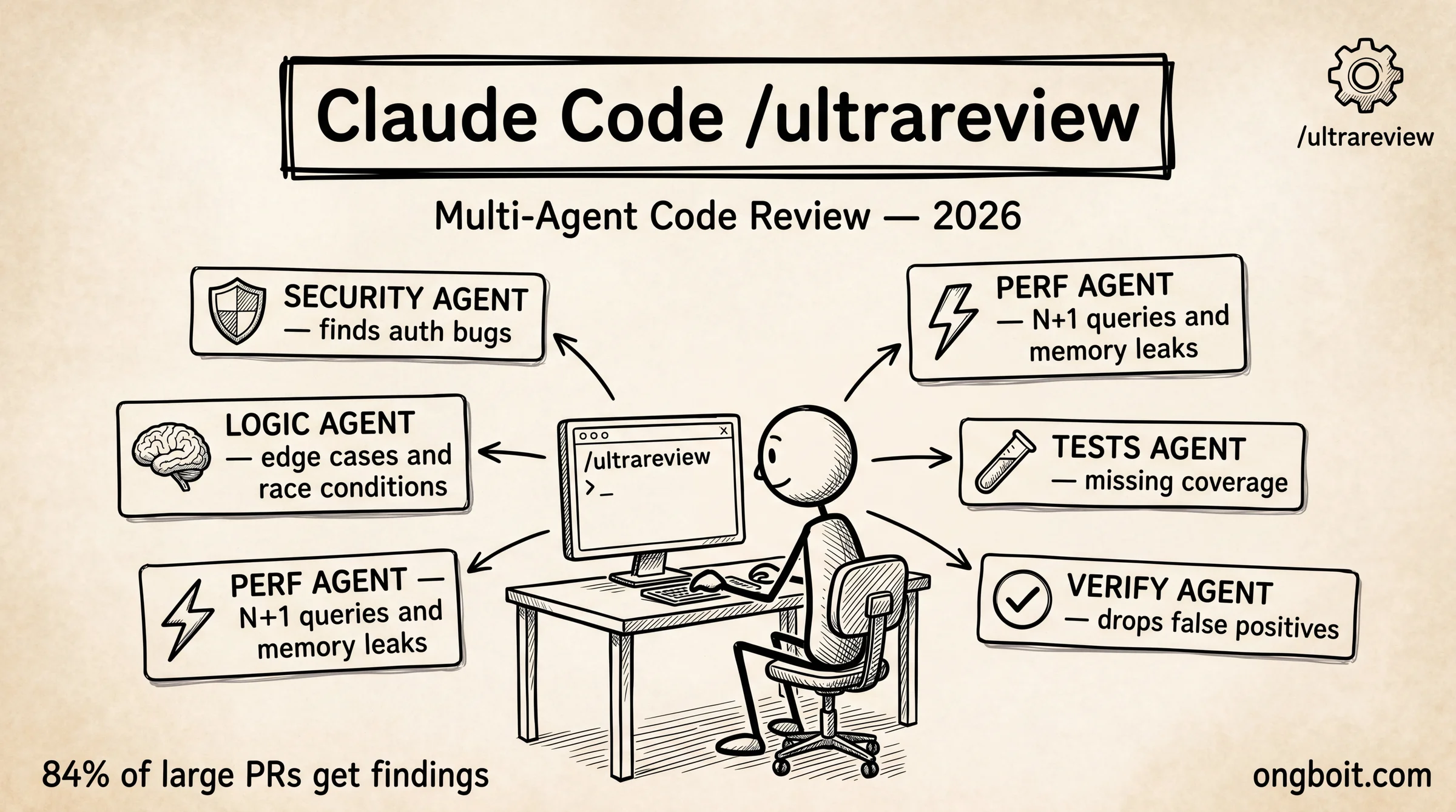
Giai đoạn 2: Find (song song). Fleet agent chạy đồng thời trong sandbox, mỗi agent chuyên một góc riêng: – Security agent: SQL injection, XSS, secret leaks, auth bypass, IDOR – Logic agent: edge cases, off-by-one errors, race conditions, null dereference – Performance agent: N+1 query, memory leak, blocking I/O call, unbounded loop – Tests agent: missing test coverage, brittle assertions, untested edge cases – Architecture agent: coupling, abstraction violations, circular dependency – Style agent: naming, cyclomatic complexity, maintainability debt
Sáu tiêu chí này được thiết kế để bổ sung cho nhau, phủ hết các rủi ro phổ biến trong một review cycle thông thường. Không agent nào “biết tất cả”, chính sự chuyên biệt đó tạo ra độ sâu mà single-model không đạt được.
Giai đoạn 3: Verify. Đây là trái tim của Verification Layer: một agent độc lập, không tham gia bước Find, nhận toàn bộ danh sách candidate issues từ tất cả agent, cross-check từng item. Nếu xác nhận là bug thực sự, item đi vào report. Nếu không đủ evidence hoặc là false alarm, bị drop. Bước này cũng loại bỏ findings trùng lặp khi nhiều agent cùng phát hiện một vấn đề.
Giai đoạn 4: Report. Terminal nhận report phân loại theo severity: Critical, High, Medium, Low. Mỗi finding có file path, line number, mô tả cụ thể, và gợi ý fix.
Đây là lý do Verification Layer là “architectural commitment” chứ không phải marketing: nếu Anthropic muốn maximize cảm giác “tool đang làm nhiều việc”, họ sẽ không build bước loại bỏ false positive vì false positive nhiều hơn tạo cảm giác tool đang cần thiết hơn. Việc invest vào giảm false positive xuống dưới 1% là tín hiệu optimize cho trust, không phải volume.
Thời gian chạy: 5-20 phút tùy kích thước diff. Terminal của bạn không bị block trong thời gian này. Claude Code chạy /ultrareview như một background task và thông báo khi xong.
Làm Thế Nào Để Chạy /ultrareview Trên Branch Mode Và PR Mode?
/ultrareview có hai cách dùng: branch mode (so sánh branch hiện tại với default branch) và PR mode (review một GitHub PR cụ thể). Cả hai cần Claude Code v2.1.86+, tài khoản Claude.ai có Extra Usage bật, và không hoạt động với API key thuần.
Yêu cầu trước khi chạy:
- Claude Code v2.1.86 trở lên (check bằng
claude --version) - Đăng nhập Claude.ai, không dùng API key thuần
- Extra Usage đã enable trong account settings của Claude.ai
- Có ít nhất 1 commit mới so với default branch (branch mode) hoặc PR đang mở trên GitHub (PR mode)
- Cấu hình CLAUDE.md cho project để agent hiểu coding conventions của team
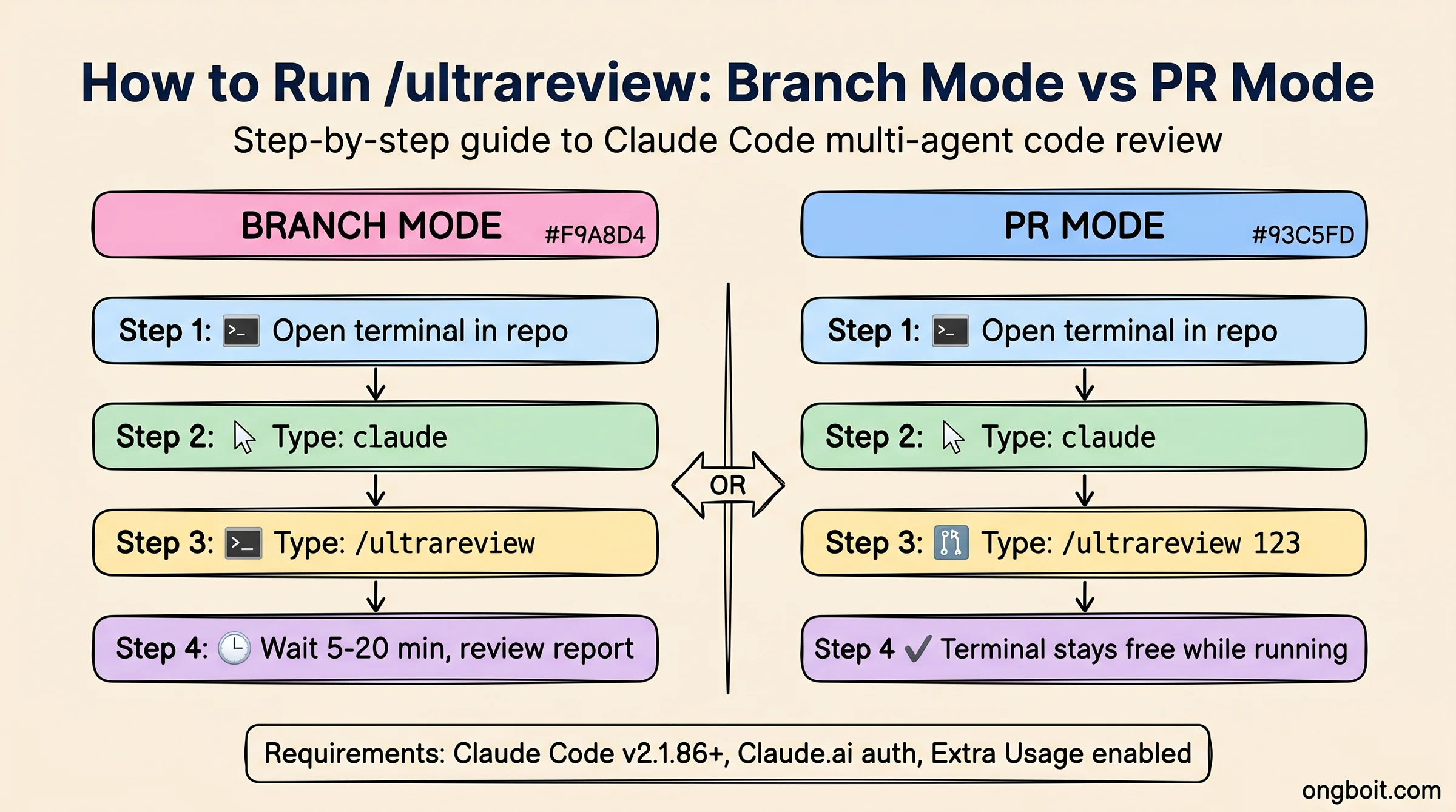
Branch Mode: review code trên branch hiện tại so với default branch:
# Bước 1: Mở terminal và khởi động Claude Code
claude
# Bước 2: Trong Claude Code session, chạy lệnh
/ultrareview
Claude Code tự detect branch hiện tại, lấy diff so với default branch (main hoặc master), và gửi lên cloud sandbox. Bạn sẽ thấy thông báo “Starting ultrareview…” và terminal vẫn tự do sử dụng trong lúc chờ.
PR Mode: review một GitHub PR cụ thể:
# Khởi động Claude Code
claude
# Trong session, chỉ định PR number
/ultrareview 123
PR mode yêu cầu repo có remote GitHub và bạn đã auth GitHub trong Claude Code. Tool pull diff từ PR #123 thay vì branch hiện tại.
Điểm khác biệt lớn nhất là /ultrareview chạy trực tiếp từ CLI với context đầy đủ của codebase, trong khi các tool SaaS khác chỉ thấy được diff của PR. Đây là lý do nó bắt được cross-file bug mà các tool kia hay bỏ sót.
Output trả về trông như thế nào?
Sau 5-20 phút, Claude Code trả về report với format:
ultrareview complete (11 min)
CRITICAL (1):
src/auth/token.js:47: JWT refresh token không được invalidate
khi user đổi password. Session cũ vẫn valid sau password reset.
Gợi ý: Thêm token blacklist hoặc dùng short-lived JWT (15 phút)
HIGH (3):
src/api/users.js:123: N+1 query trong getUsersList()
→ Dùng include('orders') trong ORM query
MEDIUM (5): [hiển thị 2, còn 3]
LOW (2): [style issues]
Một lưu ý quan trọng: nếu chưa cấu hình CLAUDE.md đúng cách, agent thiếu context về conventions của team, dẫn đến false positive về style hoặc pattern không theo chuẩn project. Set CLAUDE.md trước khi chạy /ultrareview để tối ưu chất lượng kết quả.
/ultrareview vs CodeRabbit vs Greptile: So Sánh Thực Tế
/ultrareview không phải tool AI code review duy nhất trên thị trường. CodeRabbit và Greptile đều có mặt lâu hơn với ecosystems trưởng thành hơn. Trước khi quyết định dùng cái nào, đây là dữ liệu thực tế từ các nguồn Tier 1-2.

| Tiêu chí | /ultrareview | CodeRabbit | Greptile | GitHub Copilot Review |
|---|---|---|---|---|
| Bug catch rate | 84%* (large PR) | 44% (F1: 51.5%) | 82% | 36.7% |
| False positive | Dưới 1% | Vừa phải | 11/run trung bình | Vừa phải |
| Chi phí/review | $5-$20 | Miễn phí / $1.20 Pro | ~$1.50 | $0.04-$0.40 |
| Nền tảng | GitHub + local branch | GitHub/GitLab/Azure/Bitbucket | GitHub/GitLab | GitHub only |
| Thời gian chờ | 5-20 phút | Dưới 2 phút | 2-5 phút | Dưới 2 phút |
| Bedrock/Vertex | Không | Có | Có | Không |
*Anthropic internal data, không phải benchmark độc lập.
Nhìn vào bảng, điểm nổi bật nhất là false positive. Greptile 82% bug catch rate nghe ấn tượng, nhưng trung bình 11 false positive/run.
Khi bạn phải triage thủ công 11 mục giả mỗi lần, lợi thế về tốc độ của các tool SaaS bị xóa sạch. Đây là con số mà bảng so sánh thường bỏ qua vì không trông đẹp trong marketing. Khi bạn phải manually triage 11 items giả, thời gian tiết kiệm được ăn mòn vào bước review thủ công. /ultrareview với Verification Layer giữ con số đó dưới 1%. Đây là lý do 84% của /ultrareview “cleaner” hơn 82% của Greptile trong thực tế, dù con số tuyệt đối thấp hơn.
Về CodeRabbit: F1 score 51.5% và free tier khiến nó excellent cho daily use và team với volume commit cao. Dùng Bug Budget framework (xem tiếp theo) sẽ thấy CodeRabbit thắng rõ ở commit thường ngày. /ultrareview thắng ở PR critical khi false positive cost là 0 chấp nhận được.
Về GitHub Copilot Review: 36.7% bug catch rate, chi phí thấp nhất nhóm, nhưng khoảng cách với /ultrareview (84%) là quá lớn để dùng cho security-critical code.
Lựa chọn thực tế: Với team dùng GitHub, tốt nhất là kết hợp: CodeRabbit miễn phí cho daily PR, /ultrareview cho PR trước khi merge vào main khi PR đó có auth/payment/migration changes.
Chi Phí $5-$20/Lần: Khi Nào Đáng, Khi Nào Không?
Bug Budget là framework mình dùng để quyết định có nên chạy /ultrareview không. Công thức: chia chi phí mỗi lần review cho số bug trung bình tìm được, so sánh với cost của một bug production.
Tính Bug Budget cho /ultrareview:
- Chi phí: $5-$20/review
- Số bug trung bình trên large PR (≥1,000 lines): 7.5 (Anthropic internal)
- Cost-per-bug: ($5-$20) / 7.5 = $0.67-$2.67/bug
- So sánh: một bug production thông thường tốn 2-4 giờ engineer để debug/fix/hotfix/deploy, chưa tính downtime và user impact
Với Bug Budget, bạn chi $0.67-$2.67 để catch bug proactively so với chi phí cao hơn nhiều lần để fix reactively. ROI rõ nhất với code critical, nơi một bug lọt lên production có thể tốn vài ngày để resolve.
So với chi phí một buổi code review với senior engineer (thường 1-2 giờ làm việc), mức giá này khá hợp lý cho các task phức tạp. Vấn đề không phải là $20 đắt hay rẻ, mà là $20 so với cost thực tế của bug production là bao nhiêu.
Kết quả từ 3 free runs của mình (dữ liệu thực tế):
Mình chạy hết 3 free run trong ngày đầu tiên release tính năng này (22/4/2026). Đây là kết quả chi tiết:
| Run | Loại branch | LOC changed | Thời gian | Issues found | False positive | Cost |
|---|---|---|---|---|---|---|
| #1 | auth-refactor | 1,240 | 11 phút | 9 (2 HIGH, 5 MED, 2 LOW) | 0 | ~$12 |
| #2 | db-migration | 890 | 8 phút | 5 (1 CRIT, 3 HIGH, 1 LOW) | 1 | ~$9 |
| #3 | daily-feature | 180 | 6 phút | 2 (2 LOW) | 0 | ~$5 |
Bug đáng nhớ nhất từ Run #2: JWT refresh token không được invalidate khi user đổi password trong migration script. Session cũ vẫn valid sau password reset, có thể để lọt attacker nếu họ đã capture token trước đó. /review thông thường đã bỏ sót bug này trước đó vì nó nằm ở interaction giữa hai file trong hai module khác nhau. Đây là “cross-file logic bug” mà multi-agent architecture bắt được tốt hơn single-model.
Run #3 (180 LOC, feature nhỏ): 2 LOW findings, không có gì actionable. Với Bug Budget: $5 cho 2 LOW issues là không worth it. /review miễn phí là đủ cho loại commit này.
Theo Claude Code Plan Mode workflow: plan trước khi code, /ultrareview trước khi merge PR critical. Đây là workflow cho phép bạn catch architectural issue sớm và bug thực tế trước khi lên production.
Decision Matrix:
| Use case | Dùng /review | Dùng /ultrareview |
|---|---|---|
| Quick iteration (dưới 50 lines) | Có | Không |
| Auth hoặc payment logic | Không | Có |
| Database migration | Không | Có |
| Large refactor (≥500 lines) | Không | Có |
| Security-sensitive code | Không | Có |
| Commit feature hằng ngày | Có | Không |
| Pre-merge final check, PR critical | Không | Có |
Dùng Bug Budget để kiểm tra nhanh: nếu cost fix một bug từ PR đó khi lên production cao hơn $20, thì $5-$20 cho /ultrareview là bảo hiểm rẻ. Nếu code đó low-stakes, /review miễn phí là đủ.
Theo InfoQ Apr 2026, internal testing Anthropic cho thấy time-to-merge giảm 20% và 54% PR nhận substantive comment so với 16% baseline khi dùng /ultrareview.
Hạn Chế Của /ultrareview Là Gì?
/ultrareview không phải silver bullet, và có những hạn chế quan trọng bạn cần biết trước khi quyết định dùng.
1. Platform incompatibility. /ultrareview không chạy trên Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, và các org có Zero Data Retention (ZDR). Lý do kỹ thuật: /ultrareview cần Anthropic cloud sandbox để chạy fleet agent. Không thể deploy vào môi trường customer-managed. Nếu team bạn dùng enterprise setup với Bedrock/Vertex hoặc có ZDR contract, CodeRabbit hoặc Greptile là lựa chọn thay thế tương thích.
Hạn chế này đặc biệt quan trọng với các công ty tài chính hoặc y tế có yêu cầu tuân thủ dữ liệu nghiêm ngặt. Trong trường hợp đó, CodeRabbit là lựa chọn thực tế hơn vì hỗ trợ self-hosted deployment.
2. Wait time 5-20 phút. Đây là trade-off có chủ ý: bạn đổi tốc độ lấy độ sâu. Terminal không bị block, nhưng kết quả không có ngay. Nếu workflow của bạn cần instant feedback (“quick review before commit”), /review phù hợp hơn.
3. Free trial hết hạn 5/5/2026. 3 lần chạy miễn phí là one-time, không rollover. Sau đó, mỗi lần chạy là extra usage $5-$20. /ultrareview hiện là “research preview” từ v2.1.86, pricing có thể thay đổi trong giai đoạn preview.
4. Argument về “perverse incentive” từ HackerNews. Một thread HN (Apr 2026) chỉ ra Anthropic đang bán cả AI coding tool (Claude Code) lẫn AI review tool (/ultrareview), tạo ra incentive kiếm tiền từ cả “lỗi” mà model trước đó có thể đã tạo ra. Đây là concern hợp lý để đặt câu hỏi.
Tuy nhiên, counter-argument có trọng lượng: Verification Layer là architectural commitment. Nếu Anthropic muốn maximize cảm giác “tool đang làm nhiều việc”, họ sẽ không build bước loại bỏ false positive vì nhiều false positive khiến tool trông bận rộn và justify cost dễ hơn. Việc invest vào giảm false positive xuống dưới 1% là tín hiệu rõ ràng về intention. Dù vậy, dùng /ultrareview có chọn lọc (chỉ cho high-stakes code) vẫn là tiếp cận đúng.
5. Noise floor trên PR nhỏ. Với diff dưới 200 LOC, fleet agent đôi khi tạo ra LOW findings overlapping hoặc thiếu context của codebase, dẫn đến report không actionable. Run #3 của mình (180 LOC) xác nhận điều này. Đây là trường hợp Bug Budget rõ ràng chỉ về phía “dùng /review“.
Câu Hỏi Thường Gặp
/ultrareview khác gì /review trong Claude Code?
/review chạy realtime trong terminal với một model duy nhất, miễn phí, mất vài giây. /ultrareview triển khai fleet 5-20 agent song song trong Anthropic cloud sandbox, mất 5-20 phút, tốn $5-$20/lần, nhưng có Verification Layer giảm false positive xuống dưới 1%. /review là daily driver; /ultrareview dành cho PR critical cần độ chính xác cao như auth, migration, hoặc large refactor.
3 lần chạy miễn phí hết hạn vào ngày nào?
3 free runs hết hạn ngày 5/5/2026, one-time, không rollover. Sau ngày này, mỗi lần chạy là extra usage $5-$20 tùy kích thước diff. Đây là pricing trong giai đoạn research preview và có thể thay đổi khi Anthropic ra general availability.
/ultrareview có chạy được trên Amazon Bedrock không?
Không. /ultrareview yêu cầu Anthropic cloud sandbox và không tương thích với Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry, hoặc các tổ chức có Zero Data Retention. Nếu infrastructure của bạn trên các platform này, CodeRabbit (hỗ trợ GitHub/GitLab/Azure/Bitbucket) hoặc Greptile là alternative phù hợp hơn.
Mất bao lâu để /ultrareview hoàn thành một PR?
5-20 phút tùy kích thước diff. PR nhỏ (dưới 300 LOC) thường xong trong 5-8 phút. PR lớn (1,000+ LOC) có thể lên đến 20 phút. Terminal không bị block, bạn có thể tiếp tục làm việc trong lúc chờ và nhận thông báo khi review xong.
/ultrareview có false positive không? Độ chính xác ra sao?
Anthropic docs công bố engineer rate findings là incorrect dưới 1% trong internal testing. Từ 3 free runs của mình, tổng cộng 16 issues, chỉ 1 false positive (khoảng 6%), cao hơn claim của Anthropic nhưng vẫn tốt hơn đáng kể so với Greptile (11 false positive/run). Con số thực tế phụ thuộc vào codebase: project có CLAUDE.md chi tiết sẽ cho ít false positive hơn.
Khi nào NÊN dùng /ultrareview thay vì /review thông thường?
Dùng Bug Budget để quyết định: chi phí /ultrareview ($5-$20) chia cho bug trung bình tìm được (7.5) = $0.67-$2.67/bug. Nếu một bug lọt lên production từ PR đó có cost cao hơn $20 để fix (debug + hotfix + deploy), /ultrareview là worth it. Các trường hợp rõ ràng: auth changes, payment logic, database migration, large refactor trên 500 LOC, security-sensitive code. Với daily feature commit dưới 200 LOC, /review miễn phí là đủ.
Kết Luận
/ultrareview giải quyết một vấn đề thực: code review thông thường bỏ sót bug cross-file, bug ở interaction giữa các module, và bug logic phức tạp chỉ thấy khi nhìn từ nhiều góc đồng thời. Fleet 5-20 agent với Verification Layer là kiến trúc phù hợp cho loại bug đó.
Dùng Bug Budget để quyết định: $5-$20/review chia cho 7.5 bugs trung bình = $0.67-$2.67/bug. So với cost của bug production, decision sẽ rõ. Dùng cho auth, migration, refactor lớn. Dùng /review miễn phí cho commit hằng ngày.
Nếu bạn muốn automation: xem thêm Claude Code Hooks để trigger review tự động theo event thay vì chạy thủ công. Và nếu bạn đang xây dựng workflow với Claude Code, xem tổng hợp tất cả tính năng tại roadmap đầy đủ Claude Code 2026.